
Joseph Redmon released a series of 20 lectures on computer vision in September (2018). As he is an expert in the field, I wrote a lot of notes while going through his lectures.
4I am tidying my notes for my own future reference but will post them on Medium also in case these are useful for others.
His first lecture is an introduction in which he details the differences, methods and applications of low, mid, and high level computer vision (CV).
Low-Level:
Low-level computer vision techniques operate on pixel values within images and video frames. These are generally used in the first stages of a CV pipeline as the foundations upon which higher level techniques are implemented.
Resizing
We resize images every day while we two finger zoom images on our phones or resize browser windows. Therefore, resizing algorithms have to be fast, and this is often balanced with image quality.
For example, nearest neighbor sampling is fast but tends to be pixelated, whereas 2×SaI scaling is much smoother but of course slower. Below is an image scaled with nearest neighbor scaling (left) and 2×SaI scaling (right).

Grayscale
Converting color images to grayscale is actually more complex than you might think, as human perception of red green and blue can vary.
This process is of course low-level, as it’s performed on a pixel level and is very common as a foundational step in a CV pipeline. For example, edge detection is much faster when applied over a grayscale image—and usually at least as accurate.

Exposure:
Images can be manipulated in a post processing stage to alter exposure. This is common to tweak photography flaws in photoshop.

Saturation:
Image saturation is often modified in house rental images, as estate agents have likely found that houses with saturated photos sell better.

Hue:
Hue is often tweaked on TVs and monitors, as the hardware is vastly different. The same software on two monitors could show very different images, so manufacturers adjust the hue to ensure images look natural.

Edges:
Edges within images are very commonly extracted for use in higher level processing. Feature detection (such as line detection) is simplified significantly after edge detection, as less relevant information from the original image is filtered out.

Oriented Gradients:
Like edge detection, oriented gradients improve the performance of object detection by filtering out non-essential information. You can see on the images below that there’s a person in the image, even though most of the detail has been removed.

Segmentation:
Color segmentation speeds up image processing, as it simplifies images into more meaningful and easier to analyze representations. Typically segmentation is used to locate objects or boundaries.

Uses:
These low-level computer vision techniques are used in photo manipulation tools (Photoshop or Instagram filters) and feature extraction, which can in turn be used for machine learning.
Mid-Level:
Mid-level computer vision techniques tie images with other images and the real world. These often build upon low level processing to complete tasks or prepare for high level techniques.
Panorama Stitching:
One clear example of combining images with other images is panorama stitching. Additionally we know some real world information, such as how a phone is usually turned, so we can warp and combine multiple images together.

Multi-view Stereo:
This is another image combination technique that we can use our knowledge of the outside world to do. As we have two eyes, we see in 3D and perceive depth. By comparing two images, we can assess which parts of an image move a lot, and which move less, in order to judge depth.

Structured Light Scan:
Using patterned light emitters and receivers, we can construct high dimensional models of real world objects from the curvature in the patterns received. Once again, this is a combination of real world knowledge and multiple images to get the desired result.

Range Finding:
As with structured light scans, light emitters can be used alongside cameras to analyze the world. The difference here is that range finding aims to judge the distance between the camera and an object rather than building a 3D model.
This is particularly useful for use in self-driving cars, for example. Emitters are attached to the car, and the camera can judge distances from the time it takes the light to reflect back into the camera.
Laser light is used—hence, it’s commonly called LaDAR and LiDAR (Laser Detection And Ranging and Light Detection And Ranging, respectively).

Optical Flow:
In a similar fashion to creating multi-view stereo images, differences between images can be used for optical flow. Instead of using two images from slightly different positions, frames in a video are used.
By comparing which parts of an image have the biggest differences in frames of a video, we can construct an optical flow.
This is extremely useful for object tracking (and therefore image tagging) as objects move between frames.

Time-lapse:
The final mid-level computer vision technique Joseph Redmon covered in his first lecture was time-lapse creation. This seems like a relatively simple process, in which many frames over time are combined. But it’s actually more complex than I assumed.
Inconsistencies and variation such as lighting differences, snowfall on one day, or objects like cars stopping in front of the camera need to get smoothed out to create a fluid time-lapse.

Uses:
Some of these mid-level computer vision techniques tie images together into a final state. For example, panorama stitching, time-lapse creation, and video stabilization are used for no other reason than to create their output.
Optical flow, however, is often a preliminary step to assist object tracking or content-aware resizing so important parts of video frames can be detected.
High-Level:
Computer vision techniques that are considered high-level bring semantics into the process. Extracting meaning from images is much more complicated but relies heavily on pipelines of low- and mid-level computer vision techniques.
Image Classification:
Grouping images into categories is known as image classification. The CV pipeline is given an image and is then categorized into a bucket depending on the task. In the case of an emotion detector, the buckets would represent different emotions.
Then each image is tagged with the emotion that the pipeline predicts is shown in that image. Another related use of this is object detection, as shown in the image and discussed below.

Object Detection:
Extending on image classification, object detection doesn’t just return what is in the image but also where it thinks it is! This is an important distinction and very difficult to do in a reasonable timescale.
Detecting that a person is in front of a self-driving car 3 seconds after they step in front of you is of course not fast enough.
Joseph Redmon is well known in this field, as he developed YOLO (You Only Look Once), an extremely fast object detection algorithm, which you can check out in the video below:
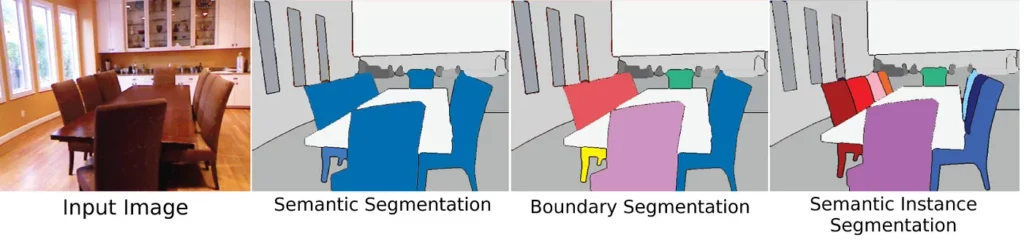
Semantic Segmentation:
Also similar to image classification is semantic segmentation. Building upon low-level segmentation, this is essentially classification at a pixel level. It’s clear how optical flow and range finding are used to classify the segments in the image below:

Instance Segmentation:
Similar to semantic segmentation, instance segmentation classifies pixels. The difference between the two is that instance segmentation can recognize multiples of the same object.
For example, illustrated below, semantic segmentation classifies chairs, a table, a building, etc. In the instance segmentation example, however, each chair is highlighted separately.
This is useful in self-driving cars, as it can distinguish between multiple vehicles in one image.
Uses:
If you keep up with the latest tech and research, you’ll have seen many uses of high-level computer vision techniques. We covered autonomous vehicles above, but didn’t mention robots.
Assistants for the elderly require vision to detect falls, retrieve objects, or for complex question answering.
To answer the question, “Do I need to do laundry?” requires image classification (at least). As such, future smart homes will increasingly rely on computer vision.
This question, of course, contains additional challenges such as the semantic meaning of what is “clean”. But that might be better suited for another article.
Other uses include game playing. Deep Blue beat the human chess champion in 1996, and since then computers have mastered games like Dota 2. This requires extremely fast image processing to win in real time.
Image retrieval, super resolution, medical imaging, and shops like Amazon Go all use high level computer vision techniques, as well, so this is a booming area of research.
High accuracy is important for many of these uses. Humans have high image processing accuracy while driving, yet many people die on the roads each year, so these systems need to be even more accurate.
Similarly, a medical imaging app could cause panic if it returned too many false positives (detecting cancer for example), so further research in this area is critical, as well.
Conclusion
Resizing your browser screen, Instagram filters, panorama stitching, 3D model creation, and real-time object detection to create safer vehicles and homes—we all use computer vision everyday.
As our technology gets smarter, we increasingly need to improve these CV pipelines with more sophisticated techniques.
In his subsequent lectures, Joseph Redmon covers some of these methods in more detail and explains how machine learning, deep learning, and natural language processing can improve our pipelines.
In the next lecture that I’ll summarize, Redmon continues to discuss human vision and its connection to computer vision. Stay tuned!
Comments 0 Responses