
As of this year, there are more than two billion active Android devices. The rapid adoption of Android phones has largely been due to the variety of smart apps, ranging from maps to photo editors. With the emergence of Deep Learning, our mobile apps are destined to become smarter.
The next generation of mobile apps powered by Deep Learning will learn and customize their functionality specifically for you.
An excellent example of this is “Microsoft SwiftKey”, a keyboard app that helps you type faster by learning the common words and phrases you use.
Computer Vision, Natural Language Processing, Speech Recognition, and Speech Synthesis can greatly improve the overall user experience in mobile applications.
Fortunately, there are a number of tools that have been developed to ease the process of deploying and managing deep learning models in mobile applications.
In this post, I’ll explain how to deploy both PyTorch and Keras models to mobile devices, using TensorFlow mobile.
Deploying models to Android with TensorFlow Mobile involves three steps:
- Convert your trained model to TensorFlow
- Add TensorFlow Mobile as a dependency in your Android app
- Write Java code to perform inference in your app with the TensorFlow model.
In this post, I’ll take you through the entire process and conclude with a working Android app infused with Image Recognition.
Table of contents
Setup
We’ll walk through this tutorial using both PyTorch and Keras—follow the instructions for your preferred machine learning framework. Your setup depends on your framework of choice.
First, install TensorFlow:
If you’re a PyTorch developer, ensure you have the latest version of PyTorch installed. For instructions on installing PyTorch, check out my previous article.
If you’re a Keras developer, install it using the following commands:
Android Studio (Minimum version of 3.0)
Converting PyTorch Models to Keras
This section is only for PyTorch developers. If you’re using Keras, you can skip ahead to the section Converting Keras Models to TensorFlow.
The first thing we need to do is transfer the parameters of our PyTorch model into its equivalent in Keras. To simplify this process, I’ve created a script to automate this conversion.
In this tutorial, we’ll be using SqueezeNet, a mobile architecture that’s extremely small with a reasonable level of accuracy. Download the pre-trained model here (just 5mb!).
Before converting the weights, we need to define the SqueezeNet model in both PyTorch and Keras.
Define SqueezeNet in both frameworks and transfer the weights from PyTorch to Keras, as below.
Create a convert.py file, include the code below and run the script.
import torch
import torch.nn as nn
from torch.autograd import Variable
import keras.backend as K
from keras.models import *
from keras.layers import *
import torch
from torchvision.models import squeezenet1_1
class PytorchToKeras(object):
def __init__(self,pModel,kModel):
super(PytorchToKeras,self)
self.__source_layers = []
self.__target_layers = []
self.pModel = pModel
self.kModel = kModel
K.set_learning_phase(0)
def __retrieve_k_layers(self):
for i,layer in enumerate(self.kModel.layers):
if len(layer.weights) > 0:
self.__target_layers.append(i)
def __retrieve_p_layers(self,input_size):
input = torch.randn(input_size)
input = Variable(input.unsqueeze(0))
hooks = []
def add_hooks(module):
def hook(module, input, output):
if hasattr(module,"weight"):
self.__source_layers.append(module)
if not isinstance(module, nn.ModuleList) and not isinstance(module,nn.Sequential) and module != self.pModel:
hooks.append(module.register_forward_hook(hook))
self.pModel.apply(add_hooks)
self.pModel(input)
for hook in hooks:
hook.remove()
def convert(self,input_size):
self.__retrieve_k_layers()
self.__retrieve_p_layers(input_size)
for i,(source_layer,target_layer) in enumerate(zip(self.__source_layers,self.__target_layers)):
weight_size = len(source_layer.weight.data.size())
transpose_dims = []
for i in range(weight_size):
transpose_dims.append(weight_size - i - 1)
self.kModel.layers[target_layer].set_weights([source_layer.weight.data.numpy().transpose(transpose_dims), source_layer.bias.data.numpy()])
def save_model(self,output_file):
self.kModel.save(output_file)
def save_weights(self,output_file):
self.kModel.save_weights(output_file)
"""
We explicitly redefine the Squeezent architecture since Keras has no predefined Squeezent
"""
def squeezenet_fire_module(input, input_channel_small=16, input_channel_large=64):
channel_axis = 3
input = Conv2D(input_channel_small, (1,1), padding="valid" )(input)
input = Activation("relu")(input)
input_branch_1 = Conv2D(input_channel_large, (1,1), padding="valid" )(input)
input_branch_1 = Activation("relu")(input_branch_1)
input_branch_2 = Conv2D(input_channel_large, (3, 3), padding="same")(input)
input_branch_2 = Activation("relu")(input_branch_2)
input = concatenate([input_branch_1, input_branch_2], axis=channel_axis)
return input
def SqueezeNet(input_shape=(224,224,3)):
image_input = Input(shape=input_shape)
network = Conv2D(64, (3,3), strides=(2,2), padding="valid")(image_input)
network = Activation("relu")(network)
network = MaxPool2D( pool_size=(3,3) , strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = MaxPool2D(pool_size=(3,3), strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = MaxPool2D(pool_size=(3, 3), strides=(2, 2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
#Remove layers like Dropout and BatchNormalization, they are only needed in training
#network = Dropout(0.5)(network)
network = Conv2D(1000, kernel_size=(1,1), padding="valid", name="last_conv")(network)
network = Activation("relu")(network)
network = GlobalAvgPool2D()(network)
network = Activation("softmax",name="output")(network)
input_image = image_input
model = Model(inputs=input_image, outputs=network)
return model
keras_model = SqueezeNet()
#Lucky for us, PyTorch includes a predefined Squeezenet
pytorch_model = squeezenet1_1()
#Load the pretrained model
pytorch_model.load_state_dict(torch.load("squeezenet.pth"))
#Time to transfer weights
converter = PytorchToKeras(pytorch_model,keras_model)
converter.convert((3,224,224))
#Save the weights of the converted keras model for later use
converter.save_weights("squeezenet.h5")
Having converted the weights above, all you need now is the Keras model saved as squeezenet.h5. At this point, we can discard the PyTorch model and proceed to the next step.
Converting Keras to TensorFlow Models
At this point, you have a Keras model either converted from PyTorch or obtained directly from training with Keras. You can download the pre-trained Keras SqueezeNet model here. The next step is to take our entire model structure and weights and convert it into a production-ready TensorFlow model.
Create a new file ConvertToTensorflow.py and add the code below.
from keras.models import Model
from keras.layers import *
import os
import tensorflow as tf
def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True):
if os.path.exists(output_dir) == False:
os.mkdir(output_dir)
out_nodes = []
for i in range(len(keras_model.outputs)):
out_nodes.append(out_prefix + str(i + 1))
tf.identity(keras_model.output[i], out_prefix + str(i + 1))
sess = K.get_session()
from tensorflow.python.framework import graph_util, graph_io
init_graph = sess.graph.as_graph_def()
main_graph = graph_util.convert_variables_to_constants(sess, init_graph, out_nodes)
graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False)
if log_tensorboard:
from tensorflow.python.tools import import_pb_to_tensorboard
import_pb_to_tensorboard.import_to_tensorboard(
os.path.join(output_dir, model_name),
output_dir)
"""
We explicitly redefine the Squeezent architecture since Keras has no predefined Squeezenet
"""
def squeezenet_fire_module(input, input_channel_small=16, input_channel_large=64):
channel_axis = 3
input = Conv2D(input_channel_small, (1,1), padding="valid" )(input)
input = Activation("relu")(input)
input_branch_1 = Conv2D(input_channel_large, (1,1), padding="valid" )(input)
input_branch_1 = Activation("relu")(input_branch_1)
input_branch_2 = Conv2D(input_channel_large, (3, 3), padding="same")(input)
input_branch_2 = Activation("relu")(input_branch_2)
input = concatenate([input_branch_1, input_branch_2], axis=channel_axis)
return input
def SqueezeNet(input_shape=(224,224,3)):
image_input = Input(shape=input_shape)
network = Conv2D(64, (3,3), strides=(2,2), padding="valid")(image_input)
network = Activation("relu")(network)
network = MaxPool2D( pool_size=(3,3) , strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = squeezenet_fire_module(input=network, input_channel_small=16, input_channel_large=64)
network = MaxPool2D(pool_size=(3,3), strides=(2,2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = squeezenet_fire_module(input=network, input_channel_small=32, input_channel_large=128)
network = MaxPool2D(pool_size=(3, 3), strides=(2, 2))(network)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=48, input_channel_large=192)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
network = squeezenet_fire_module(input=network, input_channel_small=64, input_channel_large=256)
#Remove layers like Dropout and BatchNormalization, they are only needed in training
#network = Dropout(0.5)(network)
network = Conv2D(1000, kernel_size=(1,1), padding="valid", name="last_conv")(network)
network = Activation("relu")(network)
network = GlobalAvgPool2D()(network)
network = Activation("softmax",name="output")(network)
input_image = image_input
model = Model(inputs=input_image, outputs=network)
return model
keras_model = SqueezeNet()
keras_model.load_weights("squeezenet.h5")
output_dir = os.path.join(os.getcwd(),"checkpoint")
keras_to_tensorflow(keras_model,output_dir=output_dir,model_name="squeezenet.pb")
print("MODEL SAVED")The code above saves squeezenet.pb in our output_dir. It also creates TensorBoard events in the same folder.
To have a clearer understanding of your model, you can visualize it in TensorBoard.
Open the command prompt and type:
tensorboard –logdir=output_dir_path
output_dir_path would be the path to your output_dir.
Once TensorBoard starts successfully, you’ll see the logs asking you to open the url COMPUTER_NAME:6006
Type the URL into your favorite browser and the interface below will show up.
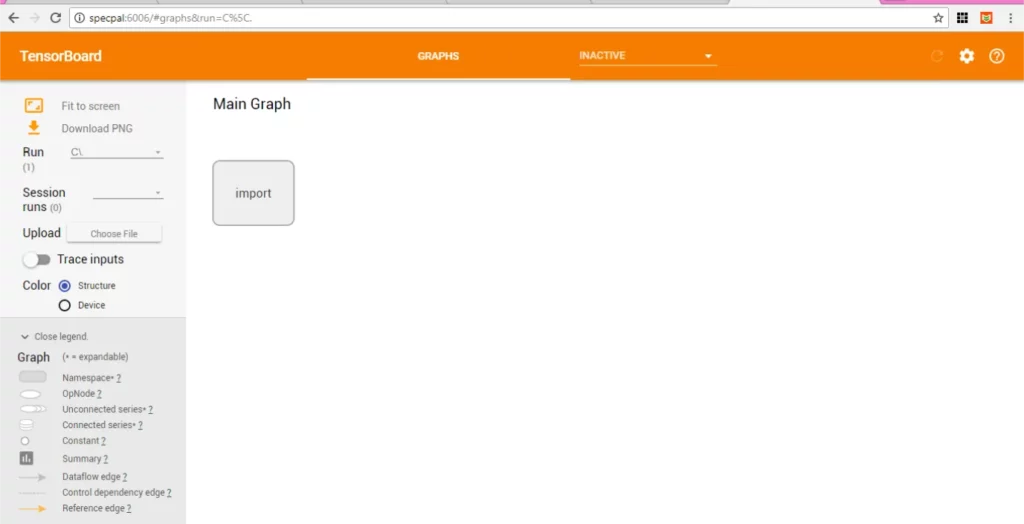
To visualize your model, double-click IMPORT.
Take a good look at the model and note the names of the input and output nodes (First and Last in the structure).
This should be input_1 and output_1 respectively, if you named your layers as I did in the previous codes.
At this point, our model is fully ready for deployment.
Adding TensorFlow Mobile to Your Project
TensorFlow has two mobile libraries, TensorFlow Mobile and TensorFlow Lite. The Lite version is designed to be extremely small in size, with the entire dependencies occupying just around 1Mb. Its models are also better optimized.
Lastly, on Android 8 and above, it’s accelerated with Android’s Neural Network API. However, unlike TensorFlow Mobile” it’s not production-ready, as a few layers might not work as well as intended yet.
Furthermore, support for compiling the library and converting models to its native format is not yet supported on Windows. Hence, in this tutorial, I’ll stick to TensorFlow Mobile.
Using Android Studio, create a new Android project if you don’t have an existing one. Add TensorFlow Mobile as a dependency in your build.gradle file.
implementation ‘org.tensorflow:tensorflow-android:+’
Android studio will prompt you to synchronize gradle. Click Sync Now and wait until it’s done.
At this point, your setup is complete.
Performing Inference in Your Mobile App
Before writing code to perform actual inference, you need to add your converted model (squeezenet.pb) into your application’s assets folder.
In Android Studio, right-click on your project, navigate to the “Add Folder” section and select “Assets Folder.”
This will create an assets folder in your app directory. Next, copy your model into the assets directory.
Also download the class labels here, and copy the file into your assets directory.
Now your project contains everything you need to classify images.
Add a new Java class to the main package of your project, name it ImageUtils, and copy the code below into it.
package com.specpal.mobileai;
import android.content.res.AssetManager;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Matrix;
import android.os.Environment;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import org.json.*;
/**
* Utility class for manipulating images.
**/
public class ImageUtils {
/**
* Returns a transformation matrix from one reference frame into another.
* Handles cropping (if maintaining aspect ratio is desired) and rotation.
*
* @param srcWidth Width of source frame.
* @param srcHeight Height of source frame.
* @param dstWidth Width of destination frame.
* @param dstHeight Height of destination frame.
* @param applyRotation Amount of rotation to apply from one frame to another.
* Must be a multiple of 90.
* @param maintainAspectRatio If true, will ensure that scaling in x and y remains constant,
* cropping the image if necessary.
* @return The transformation fulfilling the desired requirements.
*/
public static Matrix getTransformationMatrix(
final int srcWidth,
final int srcHeight,
final int dstWidth,
final int dstHeight,
final int applyRotation,
final boolean maintainAspectRatio) {
final Matrix matrix = new Matrix();
if (applyRotation != 0) {
// Translate so center of image is at origin.
matrix.postTranslate(-srcWidth / 2.0f, -srcHeight / 2.0f);
// Rotate around origin.
matrix.postRotate(applyRotation);
}
// Account for the already applied rotation, if any, and then determine how
// much scaling is needed for each axis.
final boolean transpose = (Math.abs(applyRotation) + 90) % 180 == 0;
final int inWidth = transpose ? srcHeight : srcWidth;
final int inHeight = transpose ? srcWidth : srcHeight;
// Apply scaling if necessary.
if (inWidth != dstWidth || inHeight != dstHeight) {
final float scaleFactorX = dstWidth / (float) inWidth;
final float scaleFactorY = dstHeight / (float) inHeight;
if (maintainAspectRatio) {
// Scale by minimum factor so that dst is filled completely while
// maintaining the aspect ratio. Some image may fall off the edge.
final float scaleFactor = Math.max(scaleFactorX, scaleFactorY);
matrix.postScale(scaleFactor, scaleFactor);
} else {
// Scale exactly to fill dst from src.
matrix.postScale(scaleFactorX, scaleFactorY);
}
}
if (applyRotation != 0) {
// Translate back from origin centered reference to destination frame.
matrix.postTranslate(dstWidth / 2.0f, dstHeight / 2.0f);
}
return matrix;
}
public static Bitmap processBitmap(Bitmap source,int size){
int image_height = source.getHeight();
int image_width = source.getWidth();
Bitmap croppedBitmap = Bitmap.createBitmap(size, size, Bitmap.Config.ARGB_8888);
Matrix frameToCropTransformations = getTransformationMatrix(image_width,image_height,size,size,0,false);
Matrix cropToFrameTransformations = new Matrix();
frameToCropTransformations.invert(cropToFrameTransformations);
final Canvas canvas = new Canvas(croppedBitmap);
canvas.drawBitmap(source, frameToCropTransformations, null);
return croppedBitmap;
}
public static float[] normalizeBitmap(Bitmap source,int size,float mean,float std){
float[] output = new float[size * size * 3];
int[] intValues = new int[source.getHeight() * source.getWidth()];
source.getPixels(intValues, 0, source.getWidth(), 0, 0, source.getWidth(), source.getHeight());
for (int i = 0; i < intValues.length; ++i) {
final int val = intValues[i];
output[i * 3] = (((val >> 16) & 0xFF) - mean)/std;
output[i * 3 + 1] = (((val >> 8) & 0xFF) - mean)/std;
output[i * 3 + 2] = ((val & 0xFF) - mean)/std;
}
return output;
}
public static Object[] argmax(float[] array){
int best = -1;
float best_confidence = 0.0f;
for(int i = 0;i < array.length;i++){
float value = array[i];
if (value > best_confidence){
best_confidence = value;
best = i;
}
}
return new Object[]{best,best_confidence};
}
public static String getLabel( InputStream jsonStream,int index){
String label = "";
try {
byte[] jsonData = new byte[jsonStream.available()];
jsonStream.read(jsonData);
jsonStream.close();
String jsonString = new String(jsonData,"utf-8");
JSONObject object = new JSONObject(jsonString);
label = object.getString(String.valueOf(index));
}
catch (Exception e){
}
return label;
}
}
It’s okay if you don’t understand much of the code above — it’s a couple standard functions not implemented in the core TensorFlow Mobile library. Hence, with some help from the official samples, I wrote them to make things easier later on.
Create an ImageView and a TextView in your main activity. This’ll be used to display the image and the prediction.
In your main activity, you need to load the TensorFlow inference library and also initialize some class variables. Add the following before your onCreate method:
//Load the tensorflow inference library
static {
System.loadLibrary("tensorflow_inference");
}
//PATH TO OUR MODEL FILE AND NAMES OF THE INPUT AND OUTPUT NODES
private String MODEL_PATH = "file:///android_asset/squeezenet.pb";
private String INPUT_NAME = "input_1";
private String OUTPUT_NAME = "output_1";
private TensorFlowInferenceInterface tf;
//ARRAY TO HOLD THE PREDICTIONS AND FLOAT VALUES TO HOLD THE IMAGE DATA
float[] PREDICTIONS = new float[1000];
private float[] floatValues;
private int[] INPUT_SIZE = {224,224,3};
ImageView imageView;
TextView resultView;
Snackbar progressBar;
Add a function to compute the predicted class:
//FUNCTION TO COMPUTE THE MAXIMUM PREDICTION AND ITS CONFIDENCE
public Object[] argmax(float[] array){
int best = -1;
float best_confidence = 0.0f;
for(int i = 0;i < array.length;i++){
float value = array[i];
if (value > best_confidence){
best_confidence = value;
best = i;
}
}
return new Object[]{best,best_confidence};
}
Add the function that takes in an Image Bitmap and performs inference on it:
public void predict(final Bitmap bitmap){
//Runs inference in background thread
new AsyncTask(){
@Override
protected Integer doInBackground(Integer ...params){
//Resize the image into 224 x 224
Bitmap resized_image = ImageUtils.processBitmap(bitmap,224);
//Normalize the pixels
floatValues = ImageUtils.normalizeBitmap(resized_image,224,127.5f,1.0f);
//Pass input into the tensorflow
tf.feed(INPUT_NAME,floatValues,1,224,224,3);
//compute predictions
tf.run(new String[]{OUTPUT_NAME});
//copy the output into the PREDICTIONS array
tf.fetch(OUTPUT_NAME,PREDICTIONS);
//Obtained highest prediction
Object[] results = argmax(PREDICTIONS);
int class_index = (Integer) results[0];
float confidence = (Float) results[1];
try{
final String conf = String.valueOf(confidence * 100).substring(0,5);
//Convert predicted class index into actual label name
final String label = ImageUtils.getLabel(getAssets().open("labels.json"),class_index);
//Display result on UI
runOnUiThread(new Runnable() {
@Override
public void run() {
progressBar.dismiss();
resultView.setText(label + " : " + conf + "%");
}
});
}
catch (Exception e){
}
return 0;
}
}.execute(0);
}
The above code runs the prediction in a background thread and writes the predicted class and its confidence score into the TextView we defined earlier.
To focus this tutorial on the subject of image recognition, I simply used an image of a bird added to the assets folder. In standard applications, you should write code to load the image from the file system.
Add any image you want to predict to the assets folder. To run an actual prediction, in the code below, we add a click listener to a button. The listener simply loads the image and calls the predict function.
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);
setSupportActionBar(toolbar);
//initialize tensorflow with the AssetManager and the Model
tf = new TensorFlowInferenceInterface(getAssets(),MODEL_PATH);
imageView = (ImageView) findViewById(R.id.imageview);
resultView = (TextView) findViewById(R.id.results);
progressBar = Snackbar.make(imageView,"PROCESSING IMAGE",Snackbar.LENGTH_INDEFINITE);
final FloatingActionButton predict = (FloatingActionButton) findViewById(R.id.predict);
predict.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
try{
//READ THE IMAGE FROM ASSETS FOLDER
InputStream imageStream = getAssets().open("testimage.jpg");
Bitmap bitmap = BitmapFactory.decodeStream(imageStream);
imageView.setImageBitmap(bitmap);
progressBar.show();
predict(bitmap);
}
catch (Exception e){
}
}
});
}Now you’re all done! Double check to make sure you’ve done everything properly. If all is okay, click Build APK.
After a short while, your build should be done. Install your APK and run the App.
The result should look like this:

For a more exhilarating experience, you should implement new functionalities to load an image from the the Android File System or capture images with the camera, rather than the assets folder.
Summary
Deep Learning on mobile will eventually transform the way we build and use apps. Using the code snippets above, you can easily export your trained PyTorch and Keras models to TensorFlow. With the power of TensorFlow Mobile and following the steps explained in this article, you can seamlessly infuse your mobile applications with excellent AI features.
The complete code for the Android project and the model converters is on my GitHub
If you love this article, give it some claps! You can always reach to me on Twitter via @johnolafenwa.
Discuss this post on Hacker News.
Comments 0 Responses