
Computers’ ability to have a deep understanding of images has given us the power to use them to extract information from images in an automated manner. A technique as simple as thresholding can extract enough information to be used in different applications.
More advanced algorithms can extract much complex information about the context and the content of images, such as classification and detection.
Techniques used in image segmentation can extract even more sophisticated information from images, which makes image segmentation a very hard task to do.
Still, image segmentation is super interesting, as it’s a step closer for computers to have perception close to humans, and it’s used in many applications in different fields. In this article, we’ll explain how to approach image segmentation using deep learning.
Table of contents
Definition
Image segmentation represents each pixel in an image in a certain way depending on the problem at hand. Put simply, we can say that we’re classifying each pixel in the image.
I’ll introduce two types of segmentation in this article, which are both classifying pixels belonging to different objects in an image.
Semantic Segmentation
Semantic segmentation simply means to assign each pixel in the image a class. In other words, we figure out which type of object a pixel belongs to (cat, dog, building, street, sidewalk, tumor, etc.,) without stating the difference between different objects of the same class in the picture.
In this problem, we have to output one image representing different classes appearing in the image using a different label for each class.

Instance Segmentation
Instance segmentation does the same as semantic segmentation while differentiating between different objects of the same class. In this task, the algorithm has to output a mask for each object in the image with its corresponding class.
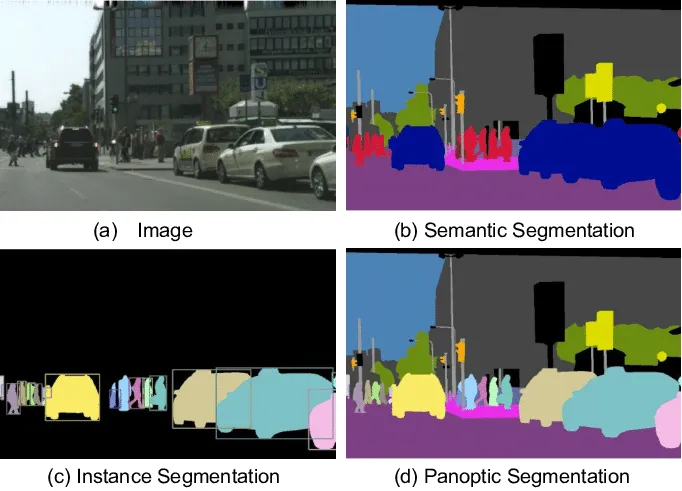
Model Examples
Using convolutional neural networks (CNNs) to approach computer vision problems has been proven as the best approach in classification problems.
Image segmentation is also best approached via CNNs. However, it is very complex and requires more advanced techniques to be used to construct and train models.
I will present some of the most common techniques by explaining the following models: U-Net, DeepLab, and Mask R-CNN.
U-Net
Approaching semantic segmentation, this architecture uses a fully convolutional network (FCN) approach built to be trained quickly and with little data.
It uses a series of convolutional and max-pooling layers, reducing the spatial resolution while doubling the channels as the network goes forward.
Then, it reverses the process using up-convolution instead of max-pooling while compensating the lost information due to spatial downsampling, using skip connections between layers with the corresponding spatial size as shown in the picture below.

Up-Convolution
Also known as transpose convolution and de-convolution, it is a convolutional layer created to upsample the input feature map by applying a normal convolutional kernel on a dilated version of the image. As shown in the below picture, the convolution operation is being done on the dilated image.

Skip Connections
Skip connections in U-Net are implemented via cropping out the borders of the layers’ outputs of the first half of the network and concatenating them to the corresponding layers of the second half.
Some improvements can be made to this approach which can lead to better performance, however, the main purpose of skip connections is to compensate for the information lost by downsampling.
DeepLab
DeepLab is another fully convolutional neural network based on using atrous convolution and CRFs.
Atrous Convolution
This version of convolution layers is just regular convolutional layers with added dilation. This way, we can capture features in different spatial scales by using different dilation rates, while still using the same kernel size. DeepLab uses a pyramid of atrous convolutional layers with different dilations to be able to detect objects of different sizes. In the below image, you can see a 3×3 kernel applied with dilations of one, two, and three. It’s like using 3×3, 5×5, and 7×7 kernels, but with zeros in between.

CRFs
Conditional random fields (CRF) is used in DeepLab as it’s been proven to refine edges. It does this by using inter-pixel correlation, by which it can combine class scores captured by local interactions between pixels, edges, or superpixels.
As this technique can be computationally expensive, DeepLab is using a version called fully connected pairwise CRF, which is computationally efficient, has the ability to refine edges, and is able to correlate long-range dependencies.
Mask R-CNN
Mask R-CNN is a state-of-the-art instance segmentation model, which is based on the Faster R-CNN model built for object detection.
This network is based on a region proposal network (RPN) in which it outputs a class label, bounding box, and a mask for each region proposal generated by the RPN while having the class and the mask outputs decoupled.
This approach uses a sigmoid activation of the mask predictions and has been proven more reliable than the approach taken by U-Net.

The output of Mask R-CNN consists of an independent mask for each object, bounding box, class, and confidence. Unlike U-Net, classification and segmentation are decoupled and the segmentation task just consists of generating binary images (on the right of the GIF) for each region of interest. This is different from U-Net, which uses a soft-max output for segmentation.

RPN
An RPN’s task is to take an image of any size and propose different windows in the image which might have objects. This task has been previously approached by R-CNN and Fast R-CNN models using selective search, which is much slower than the CNN implementation.
ROI-Align
ROI-Aligh is based on the same idea as ROI-Pooling (used in Faster R-CNN) which is a layer that transforms every region proposal into a 7×7 grid to predict the class of the region and refines the bounding box.
While ROI-Align does the same task, it doesn’t quantize the windows of the proposed regions which ROI-Pooling does, rather, it transforms the whole region directly via bilinear interpolation.
Although this quantization doesn’t affect classification or bounding box regression, it affects the accuracy of the output masks.

Anchor Boxes
Another technique to detect objects at different sizes is used by Mask R-CNN, which is a part of the pre-processing of the training data.
It works by using different anchor boxes with different ratios and scales and setting the label of objects in their closest anchor box. In this way, different parts of the network can focus on objects at a specific scale.
Conclusion
In this article, I have given a detailed introduction and overview of image segmentation, showing the main types of segmentation and presenting different models and techniques used for each.
This was a brief introduction, showing some of the essential and most common building blocks of segmentation models. I hope this has encouraged you to go deeper into the topic of segmentation.
Comments 0 Responses