
Ever wondered what the 27th letter in the English alphabet might look like? Or how your appearance would be twenty years from now? Or perhaps how that super-grumpy professor of yours might look with a big, wide smile on his face?

Thanks to machine learning, all this is not only possible, but relatively easy to do with the inference of a powerful neural network (rather than hours spent on Photoshop). The neural networks that make this possible are termed adversarial networks. Often described as one of the coolest concepts in machine learning, they are actually a set of more than one network (usually two) which are continually competing with each other (hence, adversarially), producing some interesting results along the way.
In this article, we dive into StyleGANs, a type of generative adversarial network that “enables intuitive, scale-specific control of image synthesis by learned, unsupervised separation of high-level attributes and stochastic variation”. Or, to put it plainly, StyleGANs switch up an image’s style.

Introduction
StyleGAN was originally an open-source project by NVIDIA to create a generative model that could output high-resolution human faces. The basis of the model was established by a research paper published by Tero Karras, Samuli Laine, and Timo Aila, all researchers at NVIDIA.
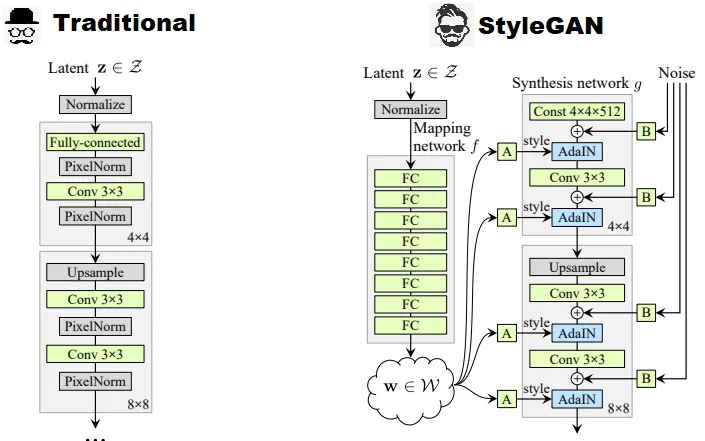
In this paper, they proposed a new architecture for the “generator” network of the GAN, which provides a new method for controlling the image generation process. In simple words, the generator in a StyleGAN makes small adjustments to the “style” of the image at each convolution layer in order to manipulate the image features for that layer.
Moreover, this new architecture is able to separate the high-level attributes (such as a person’s identity) from low-level attributes (such as their hairstyle) within an image. This separation is what allows the GAN to change some attributes without affecting others. For example, changing a person’s hairstyle in a given image.
Before we dive into the specifics of how StyleGANs works, here’s a list of interesting implementations, just to give you a sense of what’s possible with these powerful neural networks:
- Generating Game of Thrones characters
- Generating new watch styles
- Generating album covers
- Generating Pokémon characters
- Generating portraits (paintings)
Recap: What are GANs again ?
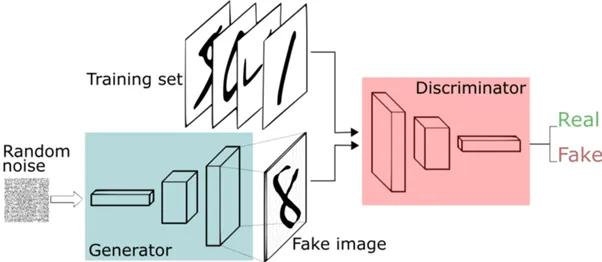
Let’s first step back and refresh our knowledge about Generative Adversarial Networks. The basic GAN is composed of two separate neural networks which are in continual competition against each other (adversaries).
One of these, called the generator, is tasked with the generation of new data instances that it creates from random noise, while the other, called a discriminator, evaluates these generated instances for authenticity.
Both tasks are phases in the GAN’s process cycle and are interdependent on each other. The generative phase is influenced by the discriminative phase’s evaluation, and the discriminative phase makes comparisons between the original dataset and the generated samples.
As training progresses, both networks keep getting smarter—the generator at generating fake images and the discriminator at detecting their authenticity. By the time the model has been trained, the generator manages to create an image authentic enough that the discriminator can’t tell if it’s a fake or not. Often, this final generated image is the resulting output.
How does the StyleGAN work?
Before diving into the changes made by the researchers to the GAN network architecture to build their StyleGAN, it’s important to note that these changes pertain only to the generator network, thus influencing the generative process only. There have been no changes to the discriminator or to the loss function, both of which remain the same as in a traditional GAN.
The purpose of NVIDIA’s StyleGAN is to overcome the limitations of a traditional GAN, wherein control may not be possible for individual characteristics of data, such as facial features in a photographs. The proposed model allows a user to tune hyperparameters in order to achieve such control. Moreover, it allows for a factor of variability in generated images due to the addition of “styles” to images at each convolution layer.
The model starts off by generating new images, starting from a very low resolution (something like 4×4) and eventually building its way up to a final resolution of 1024×1024, which actually provides enough detail for a visually appealing image.
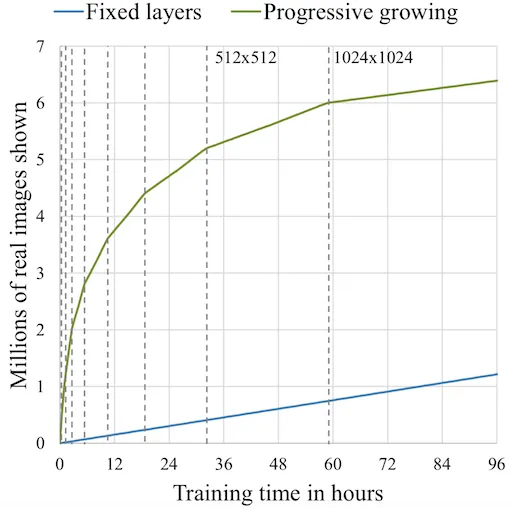
The main principle behind training the StyleGAN is this “progressive” method which was first used by NVIDIA in their ProGAN. It works by gradually increasing the resolution , thus ensuring that the network evolves slowly, initially learning a simple problem before progressing to learning more complex problems(or, in this case, images of a higher resolution). This kind of training principle ensure stability and has been proven to minimize common problems associated with GANs such as mode collapse. It also makes certain that high level features are worked upon first before moving on to the finer details, reducing the likelihood of such features being generated wrong(which would have a more drastic effect on the final image than the other way around). StyleGANs use a similar principle, but instead of generating a single image they generate multiple ones, and this technique allows for styles or features to be dissociated from each other.
Specifically, this method causes two images to be generated and then combined by taking low-level features from one and high-level features from the other. A mixing regularization technique is used by the generator, causing some percentage of both to appear in the output image.
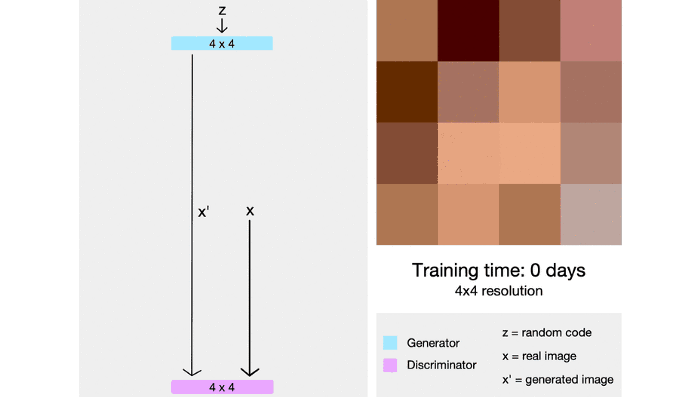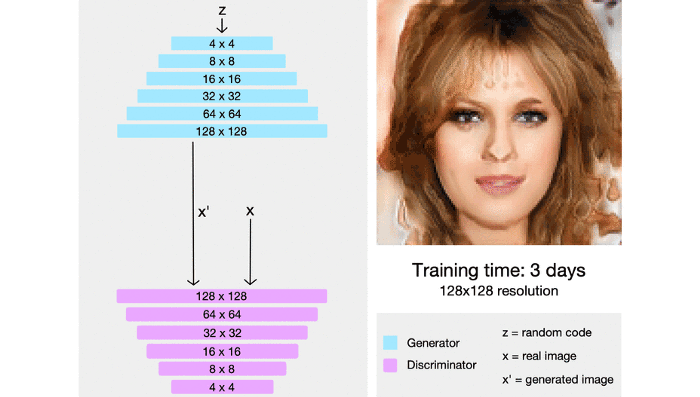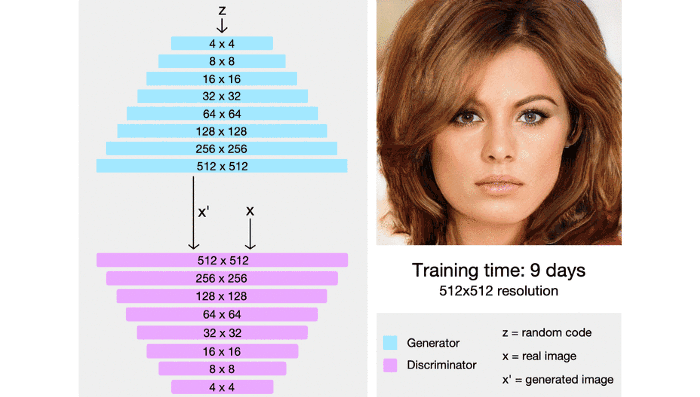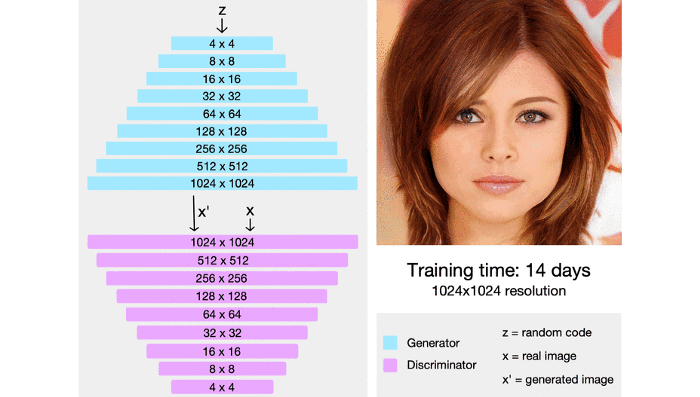
At every convolution layer, different styles can be used to generate an image: coarse styles having a resolution between 4×4 to 8×8, middle styles with a resolution of 16×16 to 32×32, or fine styles with a resolution from 64×64 to 1024×1024.
Coarse styles govern high-level features such as the subject’s pose of in the image or the subject’s hair, face shape, etc. Middle styles control aspects such as facial features. Lastly, fine styles cover details in the image such as color of the eyes or other microstructures.

The StyleGAN architecture also adds noise on a per-pixel basis after each convolution layer. This is done in order to create “stochastic variation” in the image. The researchers observe that adding noise in this way allows a localized style changes to be applied to “stochastic” aspects of the image, such as wrinkles, freckles, skin pores, stubble, etc.
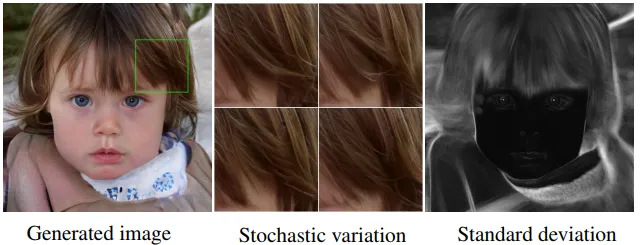
In a traditional GAN, the generator network would obtain a random “latent” vector as its input, and using multiple transposed convolutions, would alter that vector into an image that would appear authentic to the discriminator. This latent vector can be thought of as a tensor representation of the image to the network.
The traditional GAN doesn’t allow for control over finer styling of the image because it follows its own distribution, as governed by its training with high-level attributes, and also because it gets influenced by the general “trend” of its dataset (say for example, a dominant hair color throughout the dataset). The most one could do is change the input image (the vector) and thus obtain a different result.
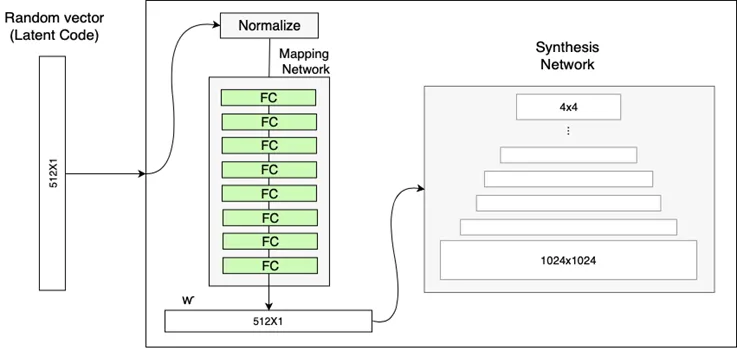
NVIDIA’s architecture includes an intermediate “latent space”, which can be thought of as being “detachable”. Input latent code can then be embedded into this space. The styles or features present in images are actually different forms of the same latent vector embedding, which is used to normalize the input of each convolutional layer.
Additional noise is also fed to the network in order to assert greater control over the finer details. When generating the output image, the user switches between latent codes at a selected point in the network, thus leading to a mixing of styles.
Feature disentanglement
The reason why traditional GANs have a problem with control of styles or features within the same image is due to something called feature entanglement. As the name suggests, a GAN is not as capable of distinguishing these finer details as a human, thus leading the features to become “entangled” with each other to some extent within the GAN’s frame of perception.
A good example would be “entanglement” between the features of hair color and gender. If the dataset used for training has a general trend of males having short hair and females having long hair, the neural network would learn that males can only have short hair and vice-versa for females. As a result, changing the latent vector to obtain long hair for the image of a male in the result would also end up changing the gender, leading to an image of a woman.

Using the intermediate latent space, the StyleGAN architecture lets the user make small changes to the input vector in such a way that the output image is not altered dramatically. A “mapping network” is included that maps an input vector to another intermediate latent vector, which is then fed to the generator network.
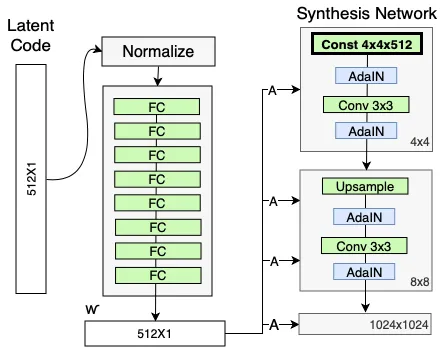
The researchers made use of a network with 8 layers for this purpose, whose input and output are both a vector with 512 dimensions. In their paper, they also make the case as to why these hyperparameters work best. They present two separate approaches to measure feature disentanglement:
- Perceptual path length — Calculate the difference between VGG16 embeddings of images when interpolating between two random inputs. A drastic change indicates that multiple features have changed together and thus might be entangled.
- Linear separability — Classify all inputs into binary classes, such as male and female. The better the classification, the more separable the features.
GAN you try it out?
Here’s a chance for you to get your hands dirty. Not only has NVIDIA made the whole project open-source, but they’ve also released a variety of resources, documentation, and pre-trained models for developers to play around with. A coder’s paradise!
StyleGAN was trained on the CelebA-HQ and FFHQ datasets for one week using 8 Tesla V100 GPUs. Its implementation is in TensorFlow and can be found in NVIDIA’s GitHub repository, made available under the Creative Commons BY-NC 4.0 license. This means you can use, redistribute, and adapt the material for non-commercial purposes, as long as you give appropriate credit by citing the research paper and indicating any changes made.
# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# This work is licensed under the Creative Commons Attribution-NonCommercial
# 4.0 International License. To view a copy of this license, visit
# http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to
# Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
"""Minimal script for generating an image using pre-trained StyleGAN generator."""
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
def main():
# Initialize TensorFlow.
tflib.init_tf()
# Load pre-trained network.
url = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ' # karras2019stylegan-ffhq-1024x1024.pkl
with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f:
_G, _D, Gs = pickle.load(f)
# _G = Instantaneous snapshot of the generator. Mainly useful for resuming a previous training run.
# _D = Instantaneous snapshot of the discriminator. Mainly useful for resuming a previous training run.
# Gs = Long-term average of the generator. Yields higher-quality results than the instantaneous snapshot.
# Print network details.
Gs.print_layers()
# Pick latent vector.
rnd = np.random.RandomState(5)
latents = rnd.randn(1, Gs.input_shape[1])
# Generate image.
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt)
# Save image.
os.makedirs(config.result_dir, exist_ok=True)
png_filename = os.path.join(config.result_dir, 'example.png')
PIL.Image.fromarray(images[0], 'RGB').save(png_filename)
if __name__ == "__main__":
main()The researchers trained their model on the Celeba-HQ and Flickr-Faces-HQdatasets, both containing 1024×1024 resolution images. They strongly advise training with 8 GPUs in order to produce similar results.
Results
In addition to the faces datasets, the researchers also used their StyleGAN on three other datasets: the LSUN BEDROOMS, CARS, and CATS datasets. Shown in the picture below are some of the results they obtained by mixing styles from the various images.
As we can see, in the BEDROOM dataset, the coarse styles control the viewpoint of the camera, the middle styles select the particular furniture, and fine styles deal with colors and smaller details of materials. The same concept holds true for the other two datasets. The effects of stochastic variation can be observed in the fabrics in BEDROOM, backgrounds and headlamps in CARS, and fur, background, and the positioning of paws in the CATS dataset.

The StyleGAN has been widely used by developers to tinker with image datasets, and many interesting results can be found. From generating anime characters to creating brand-new fonts and alphabets in various languages, one could safely note that StyleGAN has been experimented with quite a lot.
ThisPersonDoesNotExist.com also implements a StyleGan to generate a fake high-res face every time the page is refreshed. The image below shows various characters generated by a StyleGAN trained on scripts from several languages.

Concurrent Research
While in this article the focus lies by far on the research conducted by NVIDIA and compiled in their paper “A Style-Based Generator Architecture for Generative Adversarial Networks”, it would also be worthwhile to take a look at some more recent findings and developments that use NVIDIA’s research as a basis. This section summarizes the recent work relating to styleGANs with a deep learning approach.
Semantic Image Synthesis with Spatially-Adaptive Normalization

Similarly, another method for photorealistic style transfer is Semantic Image Synthesis with Spatially-Adaptive Normalization. SPADE, or spatially-adaptive normalization, acts as a layer for synthesizing images given an input semantic layout instead of directly feeding the semantic layout as input to a neural network. This input is then processed through stacks of convolution, normalization, and non-linearity layers. In many cases, traversing through this deep network of layers tends to “wash away” semantic information.
NVIDIA’s GauGAN is based on this approach. It creates photorealistic images from segmentation maps, which are labeled sketches that depict the layout of a scene. Users can use paintbrush and paint bucket tools to design their own landscapes with labels like river, rock, and cloud.
A style transfer algorithm allows users to apply filters — change a daytime scene to sunset, or a photograph to a painting. Users can even upload their own filters to layer onto their masterpieces, or upload custom segmentation maps and landscape images as a foundation for their artwork.
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?

Yet another algorithm aims to embed a given image into the latent space of StyleGAN. Supposedly, this embedding enables semantic image editing operations that can be applied to existing photographs. Taking the StyleGAN trained on the FFHD dataset as an example, researchers were able to successfully demonstrate results for image morphing, style transfer, and expression transfer.
Conclusion
StyleGAN is easily the most powerful GAN in existence. With the ability to generate synthesized images from scratch in high resolution, some would dub its capabilities scary.
Given that we live in an age where many security systems rely on measures such as facial recognition and images form a major part of all the data on the web, it’s important for people to be aware of such technology and to not unquestioningly trust information just because it’s in image form.
On the one hand, such advances in machine learning make redundant specialized skills in the domain of image manipulation and engineering. On the other, they offer opportunities for developing skill sets specific to the machine learning domain, for which there is currently a huge demand. As ML development and incorporation grow more commonplace in every sector, we can expect many more milestones such as these soon. Stay tuned!
Comments 0 Responses