
n this post, we will learn to develop a generative adversarial network (GAN) for generating realistic manga or anime characters.
I’ve always been amazed by vivid animations, especially Manga and their bold looks and strokes. Wouldn’t it be awesome to be able to draw a few ourselves, to experience the thrill of creating them with the help of a self-developed neural network?!
So what makes a GAN different?
The best way to master a skill is to practice and improvise it until you’re satisfied with yourself and your efforts. For a machine or a neural network, the best output it can generate is the one that matches human-generated outputs—or even fool a human to believe that a human actually produced the output. That’s exactly what a GAN does—well, at least figuratively 😉
Generative adversarial networks have lately been a hot topic in deep learning. Introduced by Ian Goodfellow et al., they have the ability to generate outputs from scratch.
Quick Overview of Generative Adversarial Networks
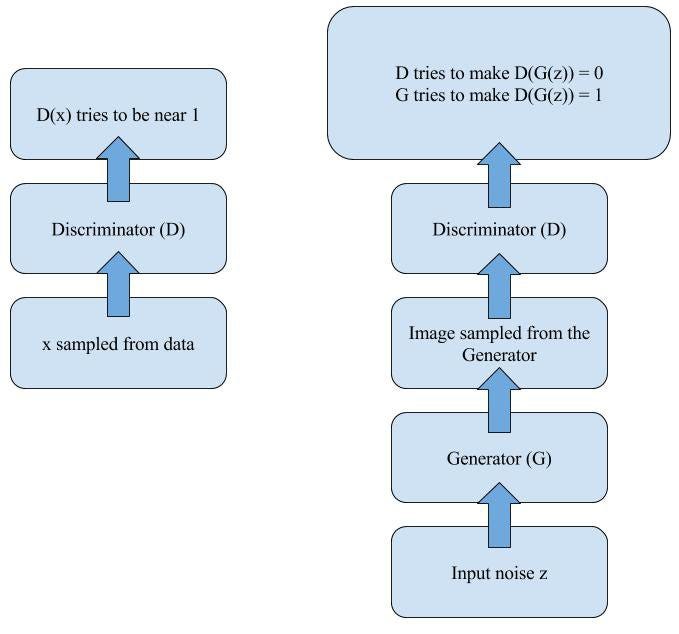
In generative adversarial networks, two networks train and compete against each other, resulting in mutual improvisation. The generator misleads the discriminator by creating compelling fake inputs and tries to fool the discriminator into thinking of these as real inputs . The discriminator tells if an input is real or fake.
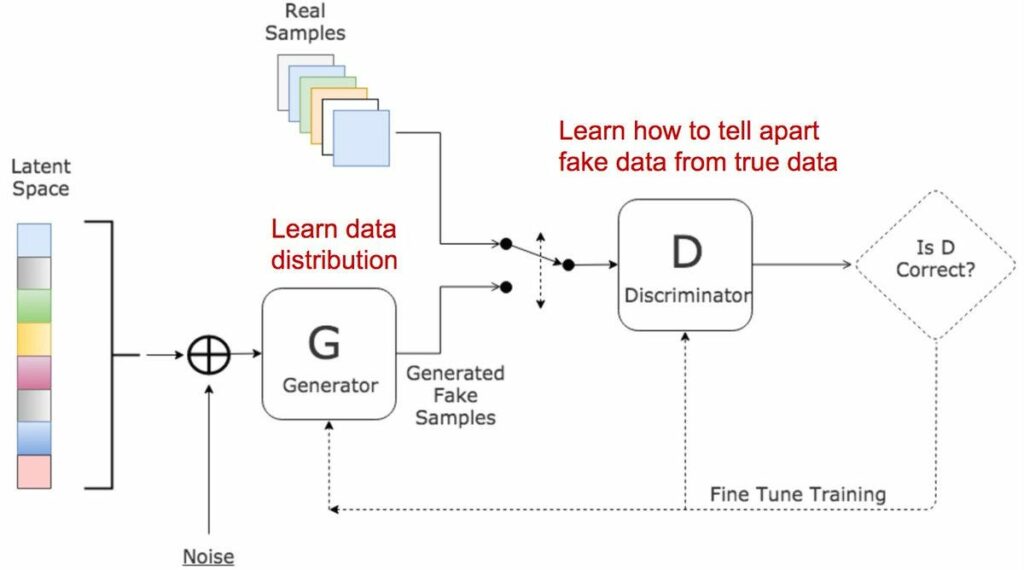
There are 3 major steps in the training of a GAN:
- Using the generator to create fake inputs based on random noise or in our case, random normal noise.
- Training the discriminator with both real and fake inputs (either simultaneously by concatenating real and fake inputs, or one after the other, the latter being preferred).
- Train the whole model: the model is built with the discriminator combined with the generator.
An important point to note is that the discriminator’s weights are frozen during the last step.
The reason for combining both networks is that there is no feedback on the generator’s outputs. The ONLY guide is if the discriminator accepts the generator’s output.
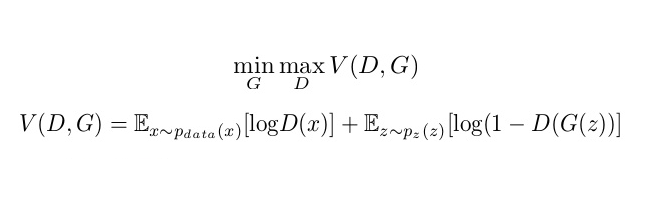
That was a brief overview of GAN’s architecture. If that doesn’t suffice, you can refer to this elaborate introduction.
Our GAN
For the task at hand, we use a DCGAN (deep convolutional generative adversarial network)
A few guidelines to follow with DCGANs:
- Replace all max pooling with convolutional strides
- Use transposed convolution for upsampling.
- Eliminate fully connected layers.
- Use batch normalization except for the output layer for the generator and the input layer of the discriminator.
- Use ReLU in the generator, except for the output, which uses tanh.
- Use LeakyReLU in the discriminator.
Setup Details
- Keras version==2.2.4
- TensorFlow==1.8.0
- Jupyter notebook
- Matplotlib and other utility libraries like NumPy, Pandas.
- Python==3.5.7
The Dataset
The dataset for anime faces can be generated by curling through various manga websites and downloading images, cropping faces out of them, and resizing them to a standard size. Given below is the link for A Python code depicting the same:
I managed to be lucky enough to find a pre-processed (faces-cropped) dataset from the following sites:
A Glimpse of the Dataset-
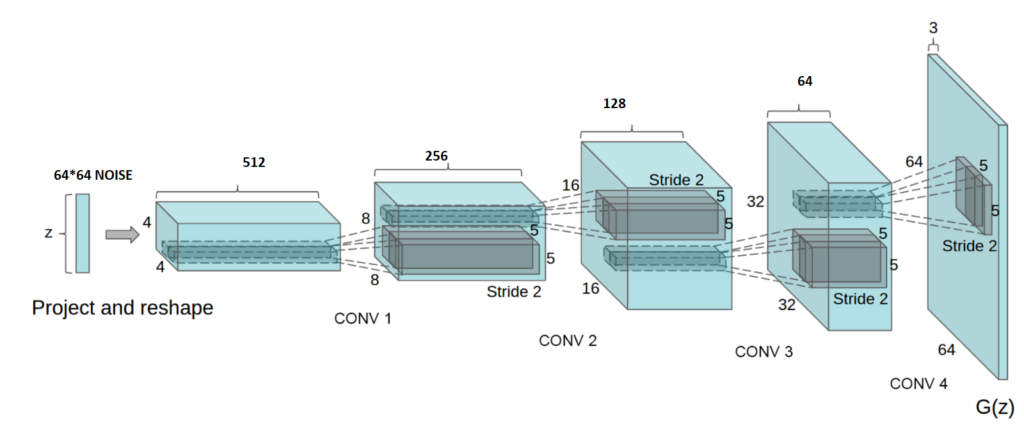
The Model
Now let’s have a look at the architecture of our neural network! Do remember the points we discussed earlier about DCGANs.
This implementation of GAN uses deconv layers in Keras. I’ve tried various combinations of layers such as:
- Conv + Upsampling
- Conv + bilinear
- Conv + Subpixel Upscaling
The Generator
The generator consists of convolution transpose layers followed by batch normlization and a leaky ReLU activation function for upsampling. We’ll use a strides parameter in the convolution layer. This is done to avoid unstable training. Leaky ReLUs are one attempt to fix the “dying ReLU” problem. Instead of the function being zero when x < 0, a leaky ReLU will instead have a small negative slope (of 0.01, or so).
Code

The Discriminator
The discriminator also consists of convolution layers where we use strides to do downsampling and batch normalization for stability.
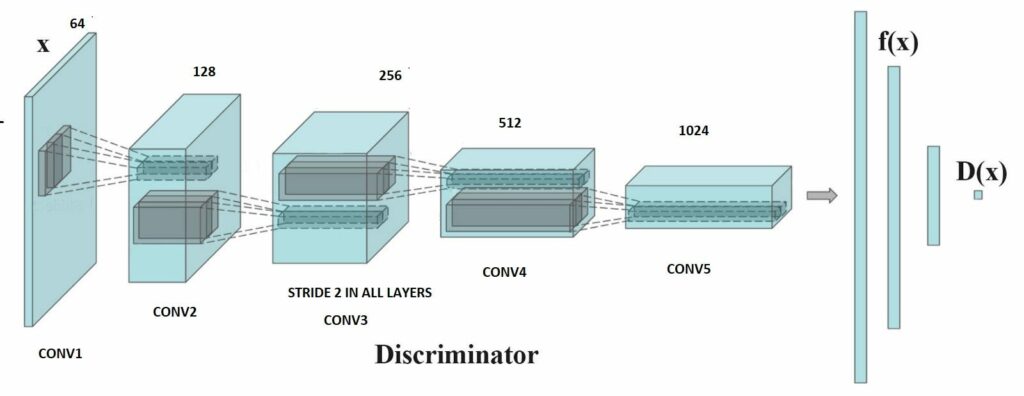
Code

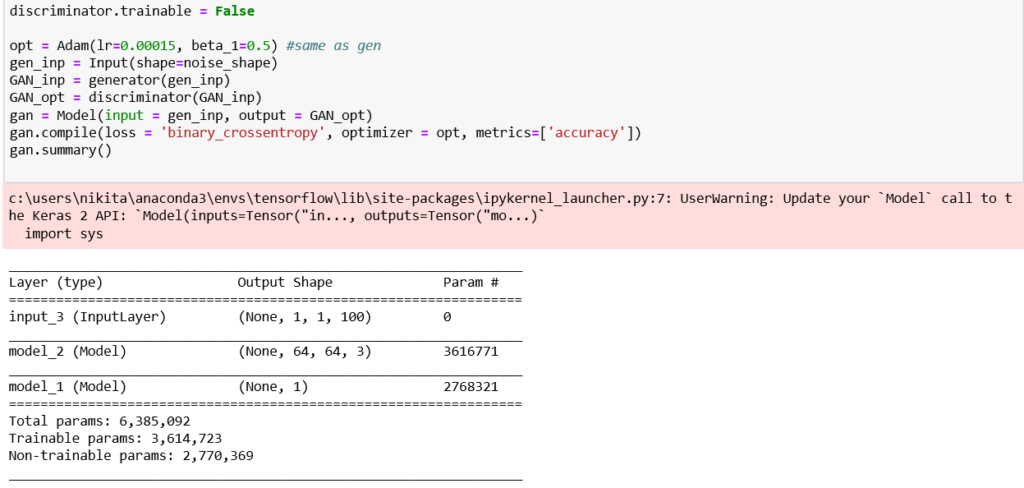
The Compiled GAN
To conduct back propagation for the generator, in order to keep a check on it’s outputs, we compile a network in Keras—generator followed by discriminator.
In this network, the input is the random noise for the generator, and the output would is the generator’s output fed to the discriminator, keeping the discriminator’s weights frozen to avoid the adversarial collapse. Sounds cool, right? Look it up!
Code
Training the Model
Basic Configurations of the model
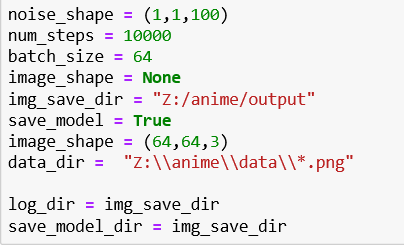
- Generate random normal noise for input

2. Concatenate real data sampled from dataset with generated noise

3. Add noise to the input label

4. Training only the generator

5. Training only the discriminator

6. Train the combined GAN

7. Saving instances of generator and discriminator
I trained this code on my Acer-Predator helios 300, which took almost half an hour for 10,000 steps and around 32,000 images, with an Nvidia GTX GeForce 1050Ti GPU.
Manga-Generator Results
After training for 10,000 steps, the results came out looking pretty cool and satisfying. Have a look!


In terms of improving the model, I think training for a longer duration and on a bigger dataset would improve the results further (Some of the faces were scary weird! Not the conventional Manga, I must say :D)
Conclusion
The task of generating manga-style faces was certainly interesting.
But there is still quite a bit of room for improvement with better training, models, and dataset. Our model cannot make a human wonder if these faces generated were real of fake; even so, it does an appreciably good job of generating manga-style images. Go ahead and try this with complete manga postures, too.
Repository
Here is the link to my GitHub repository. Feel free to have a look, clone, or improvise it. All kinds of suggestions and criticisms are welcome. Please upvote if you like the content and implementation.
Sources
- https://towardsdatascience.com/generate-anime-style-face-using-dcgan-and-explore-its-latent-feature-representation-ae0e905f3974
- https://github.com/pavitrakumar78/Anime-Face-GAN-Keras
- https://medium.com/@jonathan_hui/gan-dcgan-deep-convolutional-generative-adversarial-networks-df855c438f
I hope you enjoyed my first article on generative adversarial networks for manga-face generation! Don’t forget to hit the upvote and follow button!
Comments 0 Responses