
Machine Learning on Mobile: It’s cool, but…
Machine learning is moving to the edge. You’ve probably read or heard this sentiment somewhere. Whether it was a WWDC session, an ARM whitepaper, or any number of insightful pieces about the future of ML, the concept of on-device machine learning is expanding in both theoretical and practical terms.
But the truth is, the buzz surrounding ML on mobile (Android and iOS) is only one variable in a nuanced equation.
For starters, the worlds of mobile development and machine learning are, in theory, quite far apart. From language and logic to the amount of specific knowledge needed to truly understand neural networks, the skill sets involved in mobile dev and machine learning can be disparate. The performance of a neural net and creating a fluid UI on mobile are (generally speaking) largely unrelated concerns.
Additionally, mobile machine learning primarily takes place in two different contexts. Model training still generally happens on server-side ML frameworks (think TensorFlow, PyTorch, etc), while model inference can reliably take place on-device. It would follow, then, that developers and engineers working with ML on mobile have to know how and when to code switch between model and application development.
Luckily, we’re starting to see more robust tools with increased institutional and community support. From big players like Apple (Core ML, Create ML, Turi Create, Core ML Tools), Google (ML Kit, TensorFlow Lite), and Facebook (PyTorch Mobile), to startups like Skafos, the landscape of developer tools, educational resources, and incredible real-world applications continues to expand.
But from what we’ve gleaned working in this space over the past couple of years, there’s lingering uncertainty about how machine learning features can actually make user experiences better, more transformative, and more intuitive.
It’s really cool and impressive to be able to point your phone’s camera at a scene and get a near-instant prediction that classifies an object, estimates a human’s position, or analyzes a block of text. But in and of themselves, those ML tasks aren’t usually actionable inside a mobile experience.
As such, we’ve seen a lot of interesting and high-performing demo projects that implement standalone ML features. These demo projects are invaluable for learning the intersecting skill sets and tools that make them possible.
But to transition from demo projects to production-ready apps that effectively leverage machine learning as a core component, it’s essential to clearly define and understand what machine learning features do, how they’re currently being used (and how to use them), and possible use cases for the future.
A tall task, for sure, but I’m going to attempt to do that in this blog post. Wish me luck.
What can machine learning do on mobile?
Before trying to dive into the tools and techniques that sit at the mobile + ML intersection, let’s quickly review the primary task categories in machine learning. I’ll avoid jumping into the weeds of how machines actually learn. This is valuable information, of course, but there are plenty of great dives into this that are easily findable with a simple Google Search (i.e. here, here, and here).
Instead, I want to focus on what machine learning tasks actually do (see, hear, sense, think, etc.), which will hopefully begin to provide a sense of what machine learning might actually do inside mobile apps and experiences.
Computer Vision
With recent advances in both smartphone cameras and AI-accelerated chip technology (i.e. the A13 Bionic in the iPhone 11 series, the Neural Core in the Pixel 4), it’s no wonder that some of the most innovative, transformative use cases for machine learning on mobile come in the form of computer vision — broadly defined as a field of study designed to help computers learn how to “see” and, in turn, understand content in digital images and video.
In a general sense, we can think of computer-vision based machine learning (and specifically those tasks that are currently viable on mobile) as belonging to one or more of the following broad categories:
- Understanding and interpreting scenes in images and video
- Tracking motion
- Art and creativity
Here, I’ll provide brief overviews of some of the core computer vision tasks that are happening on-device (not an exhaustive list by any means). I’ll also showcase some current mobile applications that employ these computer vision tasks.
Image Recognition
Image recognition is a computer vision technique that allows machines to interpret and categorize what they “see” in images or videos. Often referred to as “image classification” or “image labeling”, this core task is a foundational component in solving many computer vision-based machine learning problems. As such, it’s one of the most foundational and widely-applicable computer vision tasks.

Recognizing image patterns and extracting features is a building block of other, more complex computer vision techniques (i.e. object detection, image segmentation, etc.), but it also has numerous standalone applications that make it an essential machine learning task.
Image recognition’s broad and highly-generalizable functionality can enable a number of transformative user experiences, including but not limited to:
- Automated image organization
- User-generated content moderation
- Enhanced visual search
- Automated photo and video tagging
- Interactive marketing/Creative campaigns
Image recognition in action
- Google Lens: Google Lens is probably the seminal use of on-device image recognition. Its goal is to present the user with relevant information related to objects that it identifies in a given image (i.e. a business, a restaurant’s menu, a historical landmark, etc). Originally released in 2017 as a standalone app, it’s now a core feature in Android’s standard camera app.
- One Bite: One Bite is a pizza review app that uses on-device image labeling to moderate user-generated content (UGC). Specifically, if a user submits a review, they also send along an image of the pizza being taste-tested — the image recognition system then ensures that that image actually contains pizza. In this case, One Bite is using on-device image recognition to better moderate and authenticate large volumes of UGC. [Download]
- Storyo: Storyo is an application that helps users organize their photos in order to more effectively tell the stories behind them. Not sure about you, but I have a few thousand images on my phone, a few of which I’ve manually organized. Apps like Storyo make it possible to automatically organize your camera roll—and do cool things with those photos, like create video memories and other shareable content. Here’s an in-depth look at the what, why, and how behind Storyo. [Download]
Object Detection
Object detection allows us to identify and locate objects in an image or video. With this kind of identification and localization, we can count objects in a scene and determine and track their precise locations, while also accurately labeling them.
Specifically, object detection draws bounding boxes around these detected objects, which allow us to locate where said objects are in (or how they move through) a given scene.
Object detection is commonly confused with image recognition, so before we proceed, it’s important that we clarify the distinctions between them.
Image recognition assigns a label to an image. A picture of a dog receives the label “dog”. A picture of two dogs, still receives the label “dog”. Object detection, on the other hand, draws a box around each dog and labels the box “dog”. The model predicts where each object is and what label should be applied. In that way, object detection provides more information about an image than recognition.
Here’s an example of how this distinction looks in practice:

Object detection in action
- Nuru, by PlantVillage: Nuru is an Android app that leverages on-device object detection to locate instances of disease in Cassava, potato, and African maize crops. Local smallholder farmers in East Africa then use this diagnostic information to target high-risk fields and develop treatment plans for them. [Download]
- MDacne: MDacne is a great representation of how AI can provide expertise that’s inherently scarce to a much broader population. It’s a skin care iOS app that allows users to take a selfie, upload it securely to app, and receive a personalized, actionable acne treatment plan in a matter of minutes (at most). [Download]
Image Segmentation
Image segmentation, at its core, separates a digital image into multiple parts.
In an era where cameras and other devices increasingly need to see and interpret the world around them, image segmentation has become an indispensable technique for teaching devices how to do this.
Essentially, it’s used to understand what’s in a given image at a pixel level. It’s different than image recognition, which assigns one or more labels to an entire image; and object detection, which localizes objects within an image by drawing a bounding box around them. Image segmentation provides more fine-grained information about the contents of an image.
Consider a photo of a busy street you might take with your phone:

This photo is made up of millions of individual pixels, and the goal of image segmentation is to assign each of those pixels to the object to which it belongs. Segmenting an image allows us to separate the foreground from background, identify the precise location of a bus or a building, and clearly mark the boundaries that separate a tree from the sky.
We can readily see the power of image segmentation when we consider its flexibility in photo editing software. From automatically separating backgrounds and foregrounds, to cutting out segmented people and objects, to creating responsive portrait modes, image segmentation offers a wide range of capabilities for these kinds of creativity tools.
Image segmentation in action
- Momento: Momento is an iOS app that uses on-device image segmentation to transform photos, live photos, and videos into shareable GIFs. Users are able to segment out people and apply various immersive AR effects. [Download]

- Superimpose X: Superimpose X is a professional-grade photo editing app that leans on image segmentation to power two of its core functionalities: masking and layering. These features allow users to let their imaginations run free — composite images, incredible double exposures, different worlds blended into one surreal landscape, etc. [Download]
Style Transfer
Style transfer allows us to recompose the content of an image in the style of another. If you’ve ever imagined what a photo might look like if it were painted by a famous artist, then style transfer is the computer vision technique that turns this into a reality.
Specifically, it’s a technique that takes two images — a content image and a style reference image — and blends them together so that the resulting output image retains the core elements of the content image, but appears to be “painted” in the style of the style reference image.
A selfie, for example, would supply the image content, and the van Gogh painting would be the style reference image. The output result would be a self-portrait that looks like a van Gogh original.
Here’s what this looks like in practice:

If we’re being honest with ourselves, not everyone is born an artist. Some are more adept at language or other tactile tasks. But with recent advances in technologies like style transfer, almost anyone can enjoy the pleasure that comes along with creating and sharing an artistic masterpiece.
This is where the transformative power of style transfer lies. Artists can easily lend their creative aesthetic to others, allowing new and innovative representations of artistic styles to live alongside original masterpieces.
Style transfer in action
- Looq: Looq leverages on-device artistic style transfer to turn photos into instant masterpieces, in the styles of famous artists. Looq comes with 10 styles built-in, with the option to upgrade for more (and all future) styles. [Download]
- Video Star: Video Star is a great example of how developers can use ML features as a way to continuously engage and delight their users. Each week, the Video Star team releases a new “Art Style”, which is actually a new style transfer filter. They’ve added this functionality to an already-rich content creation toolkit that allows users to become the stars of their own music videos. [Download]
Pose Estimation
Pose estimation predicts and tracks the location of a person or object. This is done by looking at a combination of the pose and the orientation of a given person/object.
We can also think of pose estimation as the problem of determining the position and orientation of a camera relative to a given person or object.
This is typically done by identifying, locating, and tracking a number of keypoints on a given object or person. For objects (rigid pose estimation), this could be corners or other significant features. And for humans (human pose estimation), these keypoints represent major joints like an elbow or knee.
The goal of a pose estimation model, then, is to track these keypoints in images and videos.
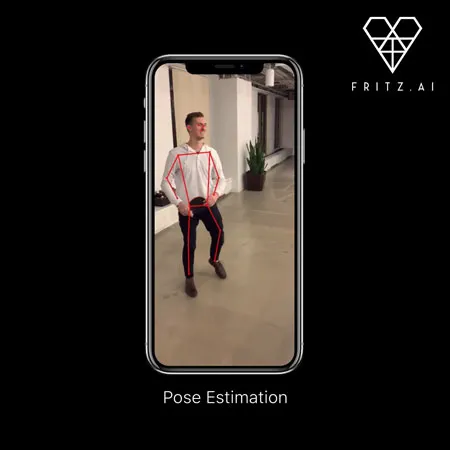
Pose estimation also differs from other common computer vision tasks in some important ways. A task like object detection also locates objects within an image. This localization, though, is typically coarse-grained, consisting of a bounding box encompassing the object. Pose estimation goes further, predicting the precise location of keypoints associated with the object.
We can clearly envision the power of pose estimation by considering its application in automatically tracking human movement. From virtual sports coaches and AI-powered personal trainers to tracking movements on factory floors to ensure worker safety, pose estimation has the potential to create a new wave of automated tools designed to measure the precision of human movement.
Pose estimation in action
- Homecourt: Homecourt is an iOS app that uses human pose estimation to capture how users are performing various basketball moves on-court: shooting, dribbling, etc. It’s a great example of how pose estimation can help track and evaluate human movement in a particular context.
- Posemoji: Posemoji uses (as its name suggests) pose estimation to track user movement and then apply fun AR effects like fireball hands or lightning bolts. The app also renders both the pose and AR effects in 3D space, meaning a more realistic, immersive experience. [Download]
Facial Recognition
Broadly speaking, facial recognition is a technique that allows us to identify (and in many cases verify) a person from an image or video.
More specifically, facial recognition systems employ a variety of algorithms that work to recognize a number of visual patterns unique to faces: similarity and proportions of skin color, facial contours, facial symmetries (and asymmetries), and more.
There are a number of measurements that are key for facial recognition systems, including but not limited to:
- distance between the eyes
- nostril width
- nose length
- cheekbone height and shape
- chin width
It’s important to note here that facial recognition is different than face detection (a kind of object detection), which only identifies and locates the existence of a face in an image or video — any face — but it doesn’t identify whose face it is.
Various implementations of facial recognition have come under intense scrutiny in recent months, and for good reason. Some of the most obvious use cases for facial recognition are in security, surveillance, and law enforcement systems, all of which can threaten user privacy and, in some cases, safety. There are also lingering concerns about bias as an adverse side effect of some facial recognition systems.
That’s not to say facial recognition can’t be used on-device to improve user experiences and user security. From Apple’s Face ID (which employs the TrueDepth camera in its system) to the Pixel 4’s Face Unlock, on-device facial recognition has the potential to power user experiences that are more personalized and secure — if these systems can overcome the vulnerabilities that others have succumb to.
Facial recognition in action
- Alipay: Alipay is a Chinese payment system that uses neural networks on point-of-sale systems that are equipped with cameras. The facial recognition network links the image captured with a digital payment system or bank account. While not exactly a mobile app, this is an excellent example of on-device facial recognition in action. Perhaps not surprisingly, this system has come under intense scrutiny, especially outside of China. But inside of China, Alipay (and similar payment systems like Tencent’s Frog Pro) have seen widespread adoption, with devices already in 100 cities. Some good discussion and more info about this system in this recent article from The Guardian.
Text Recognition (Optical Character Recognition)
A variation of image recognition, text recognition allows us to capture, extract, and potentially manipulate text from a variety of objects, documents, and more.
The underlying technology at play with text recognition is Optical Character Recognition (OCR), which is an umbrella term for a computer vision technology that allows us to recognize and extract text from images, video, scanned documents, etc.
We can easily see the powerful potential of on-device text recognition when we consider a simple application that could quickly extract and accurately record relevant information from, let’s say, business cards.
Imagine you’re at a conference designed for networking with other professionals in your field. While there, you gather a stack of business cards—new contacts and maybe some potential leads. Instead of manually entering those contacts into a spreadsheet or another database, a mobile app powered by text recognition could allow you to snap a quick photo of a given card, and automatically extract and record the relevant information.
This is just one possibility when it comes to on-device text recognition—later, we’ll highlight a couple more use cases and tools that already exist to implement text recognition on-device.
Text recognition in action
- Scanbot: Scanbot is a high-end, OCR-powered document scanning app. OCR happens automatically, with the resulting text showing up right next to your original scan, with tabs for easily navigating between views. [Download: iOS; Android]
- Adobe Scan: This is Adobe’s mobile OCR offering. As you might expect, the app is able to scan a number of different text-based objects (receipts, notes, docs, business cards, whiteboards, etc) into Adobe PDFs. Apps like this show the additive potential of mobile ML when it comes to fleshing out a product’s group of offerings. [Download: iOS; Android]
Augmented Reality*
I’ve included an asterisk here because while augmented reality (AR) is a computer vision task, it isn’t in and of itself a machine learning feature. However, I’d be remiss if I didn’t briefly discuss AR. We’re seeing more and more evidence that combining AR and ML can lead to some of the most immersive and engaging user experiences on mobile.
I tried to work up my own definition of AR, but Jameson Toole does it best in his look at combining AR and AI in mobile apps:

AR is a technology that, in theory, can be layered on top of just about any of the computer vision ML tasks we’ve discussed above. Segment the sky from an image and add an AR Death Star. Allow users to “try on” a style or a pair of shoes before buying them. Point a camera at a food item and see a sleek digital display of it’s nutritional information. Even hand puppets:
Besides Hart Woolery’s hand puppets, these are just a couple of ideas off the top of my head. Greater minds than mine (as evidenced by the above project) will certainly be able to push these complementary technologies in innovative directions.
Banuba Video Editor SDK for developers: shows how AR and on-device ML can be combined in real-world apps: it enables mobile video editing with real-time AR masks, filters, and effects that run directly on the user’s device, keeping AR experiences smooth and reliable even with limited network connectivity.
Natural Language Processing
Natural language processing (NLP) is a field of study concerned with helping computers learn how to interact with and understand human language.
From real-time translation and sentiment analysis to form auto-completion and “Smart Reply” technologies, the possibilities of implementing NLP models on-device are both fascinating and far-reaching. This is especially true with recent advances in NLP model architectures that have worked to take large language models and distill and prune them to become viable for mobile deployment.
While there’s still work to be done, the sheer power and accuracy of on-device NLP models has opened the door for a range of possibilities that can create unique, personalized user experiences. Here, we’ll take a look at a few specific NLP tasks that promise to power on-device language understanding and processing. I’ll also showcase some current mobile applications that employ these NLP tasks.
Text Classification
In similar ways to classifying images, machine learning can also help us assign tags or categories to a given piece of text. Specifically, text classification can help us do a number of things:
- Analyze sentiment: Determine if the content of a given text is positive, negative, or neutral — here, we could classify user reviews and feedback to better respond to customer inquiries.
- Categorize topics: Determine which category a piece of written content belongs to — essentially, this constitutes as robust, automatic way of tagging and organizing a piece of written content. Consider a news aggregator mobile app that uses NLP to automatically separate news articles by topic.
- Recognize language: Determine the language (English, German, French, etc.) of a given document — more organizational potential here, as businesses could use this technique to appropriately route support requests.
- Understand intent: Determine the underlying intention of a given text — for instance, this could be used to classify and screen responses to an open-ended survey about a particular product or service (i.e. Very Interested, Somewhat Interested, etc.)
Text classification in action
- Google Translate: In order for Google Translate to reliably translate text from one language to another, it has to first complete an underlying task — identifying which language the source text is in to begin with. This process requires an on-device language identification neural network. Perhaps not coincidentally, Firebase’s ML Kit (discussed in more detail below) includes an on-device Language Identification API for developers who want to implement the feature in their apps.
- Youper: Youper is a mobile app that employs an AI-based chatbot as an “Emotional Health Assistant”. Essentially, the app uses text classification to help users track, identify, and process their thoughts and feelings. A really interesting app that shows the potential of combining secure, on-device text classification with specific domain knowledge and research — in this case, research-based therapy approaches like cognitive behavioral therapy, mindfulness, and more. [Download: iOS; Android]
Translation
On-device translation has received a lot of attention recently, and especially as Google has built-out Google Translate, not just server-side but also on mobile.
Google also recently added an on-device translation API in their mobile machine learning framework ML Kit, which allows developers to add this functionality to their applications — meaning there’s now the potential to develop apps that can translate language without access to the internet, in (nearly) real-time.
Given these recent advancements and tools, we can imagine this kind of powerful on-device feature enabling a new era of global communication and information sharing that’s more seamless, private, and connective than ever before.
Translation in action
- Google Translate: The definitive standalone mobile translation app. Is able to translate into and from 59 language on-device/offline (103 online). It even employs a text recognition feature, in which you can snap a photo that contains text, recognize that text, and then translate it automatically into the target language of your choice. [Download: iOS; Android]
- TextGrabber: Another example of the combined powers of text recognition and translation, TextGrabber allows you to recognize and translate text in 60+ languages in real-time. [Download: iOS; Android]
Auto-Completion/”Smart Reply”
If you’ve ever typed out the same message to different recipients over and over and over again, then the advent of text auto-completion systems should be good news.
Essentially, these systems work by analyzing previous conversations to generate suggested text responses. If you use Gmail, then you’ve seen this ML-powered technique in action.
But these systems are now also finding their way into mobile as well as server-side applications. This is also true for Gmail, Google Hangouts, and more — the mobile flavors of these applications employ this auto completion technology on-device and in real-time. And similar to translation, developers can now implement this tech in their mobile apps, as Google has released an ML Kit API to do just that.
Audio
Ostensibly, we can perform machine learning on data captured by any of the sensors on our mobile devices, including their microphones. As such, we can also see the power of on-device ML when it comes to analyzing audio.
Couple that with recent research advances in areas like automatic speech recognition, and we can begin to imagine the possibilities of deploying audio-based machine learning models on-device.
Audio Classification
Much like other kinds of classification we’ve discussed throughout this post, audio classification works to recognize a given input and associate it with a given category, person/animal, or other class label. In this case, that input is some kind of audio file.
Somewhat surprisingly, many of the methods and techniques used to perform computer vision-based classification apply to classifying audio, as well. For a closer look at that dynamic, I’d recommend taking a look at Netguru’s excellent look at on-device audio classification.
My first thought when imagining the possibilities of an on-device audio classification system was recognizing bird songs. Not a huge surprise that a former poet would default to this nature-oriented use case, but we can clearly see the potential of on-device audio classification when we consider it — allow your phone to listen to a particular bird’s song and receive a prediction as to what kind of bird it is, alongside any other relevant identifying information.
From this one hypothetical example, we can envision the potential of classifying limitless kinds of sounds on-device.
Audio classification in action
- Google Sound Search: Google’s version of Shazam identifies popular songs playing near users via an on-device classification model. Essentially, the neural network captures a few seconds of audio from a given song to turn it into a unique identifier (kind of like a fingerprint) that can then be used to identify the music.
Speech Recognition
Speech recognition is, in its essence, the computer-based processing and identification of human voices. Research surrounding automatic speech recognition has bloomed in recent years, and alongside that research, its use cases have become more robust.
Two of the most common and obvious use cases are speech-to-text applications and voice assistant interaction. These kinds of user experiences can increase accessibility, make human-computer interaction more realistic, and create more responsive and interactive voice assistants.
Speech recognition in action
- Voice Assistants: Siri, Alexa, Google Home. These devices have become pervasive and more powerful in recent months. Specifically, these devices use what are known as “wake words” on-device to help users more seamlessly interact with the devices. If you’ve ever uttered the phrases “Hey Siri” or “Ok Google”, then you’ve interacted with an on-device speech recognition neural network.
- Pixel 4’s Real-Time Transcription: One of the most impressive experiences accompanying the release of Google’s Pixel 4 is its on-device, real-time speech-to-text transcription. The results are impressive — we’ve even done some internal testing in our own meetings. While not perfect, this experience signals the immense possibility in building accessibility and productivity tools with on-device speech recognition.
Why would developers choose to put ML in their apps?
Now that we’ve covered (or attempted to cover) the ways in which machine learning can and already is inspiring incredible mobile experiences, I also want to spend a bit of time answering a couple other questions:
- Why should developers consider implementing ML on-device?
- What are the current tools and resources available for doing so?
First, without a more complete understanding of the potential benefits of on-device ML, it could seem like sticking with the backend handling all the ML heavy lifting makes the most sense. But there are a few distinct advantages to choosing on-device inference.
Low Latency
If you’re doing anything in real-time, like manipulating live video, you’re not going to have network speeds high enough to transmit live video from your device, up to the cloud, then back to the device again.
Snapchat is probably the most obvious example here, where they use neural networks for face landmark detection to anchor AR masks. It would be a pretty terrible experience if you needed to wait 20 seconds for each filter to process before you could see the result.
Another great example of this is Hart Woolery’s app InstaSaber. He trained a custom ML model to detect and estimate the position of a rolled up piece of paper to turn it into a lightsaber. These types of AR interfaces are only possible if the processing is done on-device.
Low / No Connectivity
If you don’t have access to the internet, your app isn’t going to work. This isn’t too big of a problem in many major cities, but what about in rural settings? We mentioned PlantVillage earlier when discussing object detection, but their app Nuru is also a great example of this particular mobile ML benefit. The PlantVillage team trained a neural network that can detect different types of crop diseases impacting certain areas of east Africa. These smallholder farmers don’t always have great connectivity, though, and data costs are very expensive. The solution in this case was to put the model in the app and run it on-device.
Privacy
Machine learning can do amazing things, but it needs data. What if that data is sensitive? Would you feel comfortable sending a 3D scan of your face to Apple? They don’t think you should — which is why FaceID works entirely on-device. A neural network takes the 3D scan, embeds it into a vector, stores that in the secure enclave, and then future scans are compared to that. No facial data ever gets sent to Apple.
Similar issues come up all the time in health care applications of machine learning. For example, MDAcne (also aforementioned) is an app that tracks skin health over time with computer vision algorithms running right on the phone.
Cost
Services like AWS and GCP are pretty cheap, provided you’re using the lower end CPU / Memory configurations. But ML workloads often demand GPUs and lots of memory, even just for inference. This can get expensive really quickly. By offloading processing to a user’s device, you also offload the compute and bandwidth costs you’d incur if you were to maintain that backend.
What’s it like to develop with on-device ML?
And lastly (I swear — this is the end), it’s necessary to quickly outline the tools, frameworks, and resources available to actually start building mobile apps powered by ML.
In summary: It’s still a bit tricky, but it’s getting easier! Here’s a look at developer environments for both iOS and Android.
iOS
On iOS, you’re going to have a much better time because there are higher-level tools, and the performance of models on-device is WAY better thanks to Apple’s chip advantage. To get started, take a look at:
- Core ML — Core ML is a unified representation for all machine learning models that are ready to deploy to iOS. In essence, when you build a machine learning model and want to deploy it on iOS, you have to convert that model to Core ML format. More about the latest version of Core ML here.
- Create ML — Apple introduced a high-level Core ML model training tool in Swift Playgrounds last year. It’s essentially drag-and-drop ML. Not as much flexibility, but if you want to do something like text classification or image classification, it’s very easy to get started.
- Turi Create — A Python-based, high-level training framework maintained by Apple. It’s more flexible than Create ML, but you need to know Python.
- PyTorch Mobile — PyTorch Mobile is a new framework for helping mobile developers and machine learning engineers embed PyTorch ML models on-device. For more on PyTorch Mobile, you can check out my overview here.
- Skafos — Skafos is a tool for deploying machine learning models to mobile apps and managing the same models in a production environment. Built to integrate with any of the major cloud providers, users can utilize AWS, Azure, Google, IBM, or nearly any other computational environment to organize data and train models. Skafos then versions, manages, deploys, and monitors model versions running in your production application environments.
Android
- ML Kit — Part of Google’s Firebase product offering, ML Kit offers pre-trained models for things like face detection and OCR. They also offer the ability to create hybrid systems where some server-side and on-device models are usable via the same API. Technically ML Kit is cross-platform, but performance on iOS is poor at best.
- TensorFlow Lite / Mobile — If you’re feeling up to it, you can convert raw TensorFlow models for use on-device. TensorFlow Lite is a pared down, mobile-optimized runtime to execute models in iOS and Android apps. For now, though, there’s limited support for many operations, and performance can be somewhat lacking. However, the TFLite team is making significant progress, and some recent benchmarks suggest performance improvements, especially when accessing the GPU delegate. Many Android deployments still use the deprecated TensorFlow Mobile runtime, but that’s becoming less and less true over time.
- PyTorch Mobile — PyTorch Mobile is a new framework for helping mobile developers and machine learning engineers embed PyTorch ML models on-device. For more on PyTorch Mobile, you can check out my overview here.
Other
- Keras — A popular Python-based framework for deep learning, most often used with a TensorFlow backend. I recommend Keras over TensorFlow directly because it’s simpler, and coremltools has the easiest time converting Keras models to Core ML. TensorFlow models can be extracted for conversion to TFLite and TFMobile as well.
- QNNPACK — A mobile-optimized runtime developed and used by Facebook. Quantized operations written in low-level languages provide fast, CPU-only performance. QNNPACK is compatible with Caffe2 and PyTorch models and ships to every Facebook user via their mobile app.
- ONNX — ONNX began as an open source, standardized protocol for defining the structure and parameters of neural networks. Microsoft has now added an inference runtime as well.
These are some of the major tools, frameworks, and resources that you’ll need to be familiar with when starting your mobile ML journey.
If you’d like to explore further, I’d recommend checking out our “Awesome Mobile Machine Learning” repo on GitHub, which is regularly updated includes links to all the aforementioned tools and lots, lots more:
Additional Resources
I fibbed a little bit about that last section being the end. What would an Austin blog post be without an addendum of additional resources? Below, I’ve included links to our resource collections, which are chock full of helpful tutorials, platform reviews, in-depth implementations, and more.
Comments 0 Responses