
PyTorch, Facebook’s core machine and deep learning framework, has been steadily gaining momentum and popurity in recent months, especially in the ML/DL research community.
But until recently (last week, in fact), there was a substantial piece of the puzzle missing—an end-to-end solution for deploying PyTorch models to mobile.
TensorFlow Lite and Apple’s Core ML have, until now, stood as the primary primary mobile deployment frameworks, enabling Android and iOS developers to embed computer vision, NLP, and audio/speech neural networks directly on-device.
Announced at this year’s PyTorch Developer Conference, PyTorch 1.3 includes an experimental build of PyTorch Mobile, the platform’s new end-to-end workflow from Python to cross-platform mobile deployment.
In this post, we’ll dive into the release of PyTorch Mobile—what it is, its benefits and limitations, early benchmarks and takeaways, and some resources for further exploration.
What is PyTorch Mobile?
Put simply, PyTorch Mobile is a new framework for helping mobile developers and machine learning engineers embed PyTorch ML models on-device. Currently, it allows any TorchScript model to run directly inside iOS and Android applications.

Before this release, running PyTorch models on-device required a number of workarounds and integrations with other tools (i.e. Caffe2go, ONNX) that were brittle and frustrating to work with—and not nearly fast enough to justify using them over existing solutions like TensorFlow Lite and Core ML.
PyTorch Mobile’s unified, end-to-end workflow changes that equation and brings another major player to the table, joining the offerings from TensorFlow and Apple.
Here’s a simple look at how PyTorch Mobile works:
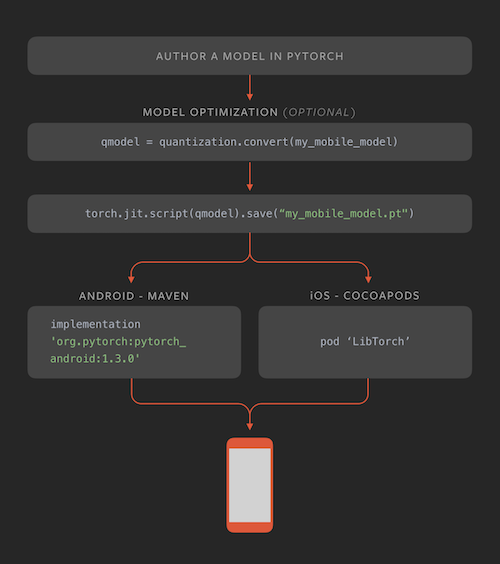
Benefits
It’s important to note that these are early days for PyTorch Mobile—the current version is experimental, and the initial features represent a skeleton upon which the PyTorch team will likely build. That said, here are some of the things we’re excited about:
- Cross-platform support: When it comes to machine learning, developing cross-platform mobile support is no trivial task. With significant differences in hardware and software, providing viable solutions for both iOS and Android is a point of differentiation.
- Quantization for model optimization: One of the primary constraints in deploying ML to mobile is model size. Bulky models inflate app sizes quickly and can be compute-intensive. Quantization is one of the primary methods for shrinking model sizes without significantly affecting performance. PyTorch Mobile’s initial release supports a number of different quantization techniques: post-training quantization, dynamic quantization, and quantization-aware training
- Dedicated runtime: PyTorch Mobile allows developers to directly convert a PyTorch model to a mobile-ready format, without needing to work through other tools/frameworks, à la Caffe2go (mentioned previously). As such, devs don’t need to worry about hooking together multiple toolchains—everything happens directly in PyTorch.
Limitations
Again, PyTorch Mobile is currently in an experimental build. As such, for all the exciting positives discussed above, there are a few notable limitations that are important to keep in mind:
- PyTorch C++ library for iOS: Currently, PyTorch Mobile is facilitated through PyTorch’s C++ library. This creates a hurdle for iOS devs. Swift cannot communicate directly with the C++ library, which means that devs will either need to use an Objective-C class as a bridge, or create a C wrapper for the C++ library. Luckily, the PyTorch team is well-aware of this and is working on providing Swift/Obj-C API wrappers.
- CPU only (for now): The PyTorch team notes that future iterations will bolster support and access for mobile GPUs, but the experimental build is limited in it’s current hardware access—thus limiting on-device inference speeds.
- API Limitations: The team also admits that the current API doesn’t cover some pre-processing and integration functions that could help make the workflow simpler and more intuitive.
Additionally, the release materials indicate that future improvements will include build-level optimization and selective compilation, which will allow developers to work with only the specific operators their apps require. Additionally, support for QNNPACK and ARM CPUs is forthcoming.

Early Results
Julien Chaumond of Hugging Face has been kind enough to share some very early benchmarks and findings on iOS. His interesting Twitter thread is linked below:
Here’s a quick summary:
- Core ML runs ResNet50 inference in 20ms (including image preprocessing, on iPhone 11)
- The PyTorch mobile demo app ships ResNet18 (~40% of the parameters of ResNet50). A forward pass of this model takes 80ms, also on the iPhone 11.
And here are his initial pros/cons:
Resources to get started
I’d expect that the PyTorch community will quickly flesh out the content ecosystem for PyTorch Mobile, but there are already some great resources, both from the PyTorch team and elsewhere:
- PyTorch 1.3 announcement
- PyTorch Mobile summary
- iOS Docs
- [GitHub] iOS demo app
- Android Docs
- [GitHub] Android demo app
- Image Classification on Android (Link to John’s tutorial)
Conclusion
It will be very interesting to see what the PyTorch team does in the coming weeks and months to support and improve upon this experimental build of PyTorch Mobile. Will this cross-platform framework be able to compete with TensorFlow Lite and Core ML? And will developers eventually be able to move beyond research and testing and release apps with PyTorch models on-device into production?
We’ll be paying attention to these questions and more as PyTorch Mobile matures. If you’ve experimented with this new framework, we’d love to hear about and share your results with our readers and developer community!
Comments 0 Responses