
At WWDC 18, Apple announced Create ML, a platform to create and train custom machine learning models on your Mac. You can train models to perform tasks like image recognition, extracting meaning from text, or finding relationships between numerical values.
One of the biggest appeals of Create ML is how easy it is to use. With images, you can simply drag-drop them into a folder in your Create ML project to start training a model. But when you’re working with other kinds of data (text, tabular data) you may need to read that data from a source file (CSV or JSON) and do some pre-processing.
Enter the MLDataTable to make life easier for developers using Create ML.
Introduction to MLDataTable
MLDataTable is a structure in Create ML that simplifies the loading and processing of text and tabular data. Most of the built-in machine learning models (MLTextClassfier, MLRegressor, MLClassifier, etc.) in Create ML reads the data in MLDataTable format, so in order to train these models we need to convert our raw training data to this format.
Via MLDataTable we can read data from JSON or CSV and manipulate the data before training. MLDataTable provides us some pre-processing methods like column manipulation (add, drop, rename), row filtering, creating new tables, and dropping duplicates.
To understand it’s usage, let’s look at a sample use-case. For this tutorial, I collected AppStore reviews of Fortnite and created a CSV, like below. The file has eight columns (review_id, title, author, etc.) and all the fields are separated with a comma.

Let’s create an empty Xcode Playground and get our hands dirty with data.
We use MLDataTable by giving it the path of the file that we want to read. Instead of writing, you can drag-drop the file to create the path.
import CreateML
import Foundation
// Read from CSV
var data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/ozgur/dataset/fortnite.csv"))We run the Playground and track the progress in the debug area panel. As you can see in the image below, MLDataTable couldn’t parse 62 lines in the CSV. When we check these lines, we see that there are extra quotes, which cause a problem for parsing.

Parsing Options
We can guide the MLDataTable to make parsing easier. MLDataTable.ParsingOptions allows us to specify the custom formats in our data. With these options, we can guide parsing with settings like the delimiter, end of line character (lineTerminator) or whether our data contains a header (containsHeader). We can even choose the columns that we want to parse by setting the column names to the selectColumns parameter. It lets us parse more lines successfully.
let parsingOptions = MLDataTable.ParsingOptions(containsHeader: true, delimiter: ",", comment: "", escape: "", doubleQuote: false, quote: "", skipInitialSpaces: false, missingValues: [], lineTerminator: "r", selectColumns:["author","rating","review"], maxRows: nil, skipRows: 0)
var table = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/ozgur/Downloads/fortnite.csv"), options: parsingOptions)As you can see above, we can guide the model as we indicate the file uses r (carriage return) for line breaks. With this guidance, the number of lines failed decreases to 2.

In this case, the problems are the commas that are being used in the sentences. It’s confusing to parse commas as they’re serving as both delimiters for columns and as punctuation. We’d better remove the punctuation before training.
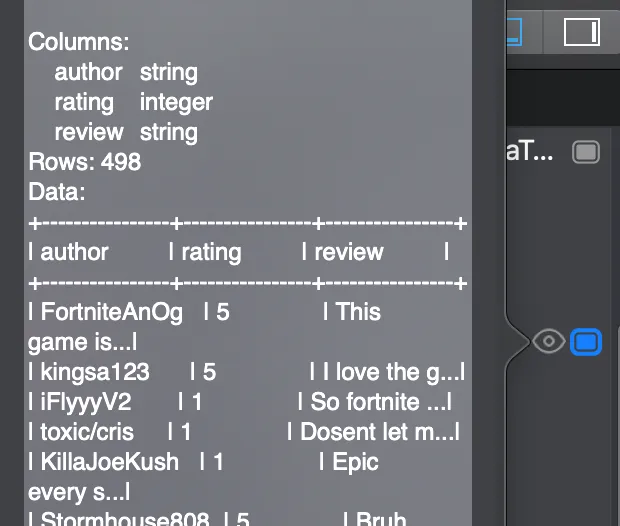
When we click the eye icon in the assistant editor, it shows us the summary of the MLDataTable.
Creating the MLDataTable with a Dictionary
We can create the MLDataTable with a dictionary as well. Types that conform to the MLDataValueConvertible protocol can be converted to a value in a data table. Array and Dictionary structures already conform to this protocol.
The code below shows converting a dictionary to the data table:
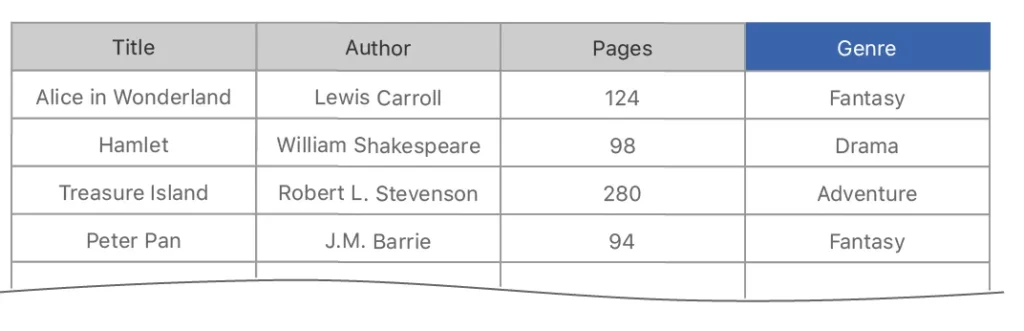
let data: [String: MLDataValueConvertible] = [
"Title": ["Alice in Wonderland", "Hamlet", "Treasure Island", "Peter Pan"],
"Author": ["Lewis Carroll", "William Shakespeare", "Robert L. Stevenson", "J. M. Barrie"],
"Pages": [124, 98, 280, 94],
]
var bookTable = try MLDataTable(dictionary: data)Removing a Column
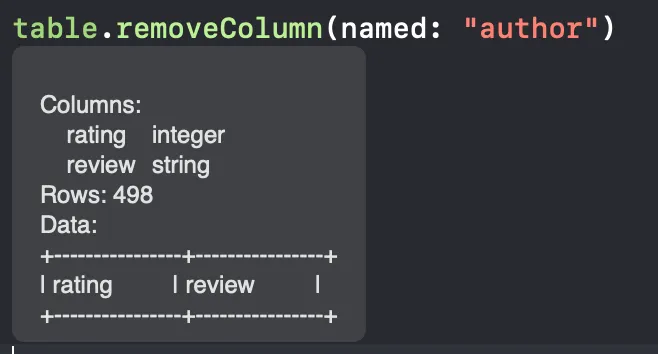
We can use the removeColumn method to remove the columns that we don’t want to include in the training process.
Adding a New Column
We can create a new column in our data table by creating a MLDataColumn and add it with the addColumn method:
let pagesColumn = MLDataColumn([124, 98, 280, 94])
bookTable.addColumn(pagesColumn, named: "Pages")Okay, so far so good. Let’s have a look at another sample. In this case, we want to create a new column by merging two other columns. How can we do that?
To show this use case, let’s say we have two subjective sentiment scores for the words in our data table.
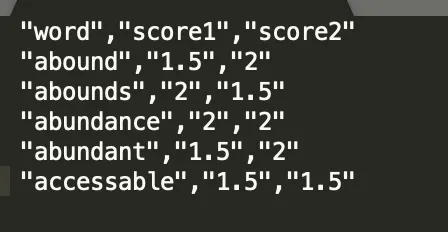
The scores are between -2 and+2 (negative to positive). We want to calculate the average of these two scores and label them as positive, negative, or neutral. We’ll write this label into a new column.
import Foundation
import CreateML
// Read from CSV
var data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/ozgur/Documents/CreateMLFiles/englishwords.csv"))
let newColumn = data.map { row -> String in
guard
let score1 = row["score1"]?.doubleValue,
let score2 = row["score2"]?.doubleValue
else {
fatalError("Missing or invalid columns in row.")
}
let average = (score1 + score2)/2
var sentiment = "negative"
if average < 0
{sentiment = "negative"}
else if average == 0
{sentiment = "neutral"}
else
{sentiment = "positive"}
return sentiment
}
data.addColumn(newColumn, named: "Sentiment")After running this code in Create ML, the data table will have a new column like in the image below.

Extra Methods
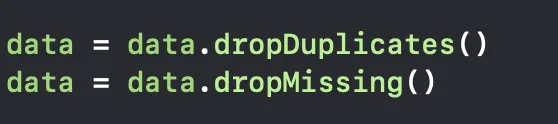
dropDuplicates: removes the duplicate rows in the table.
dropMissing: removes the rows that have missing values.
fillMissing: fills the missing values in the named column.
randomSplit: splits the data into two sets—this is useful for creating training and testing data sets. It takes a value between 0.0 and 1.0, indicating the fraction of rows that go into one subset or the other.

After finishing the pre-processing, we can give this MLDataTable directly to a model and start the training process of our machine learning model.

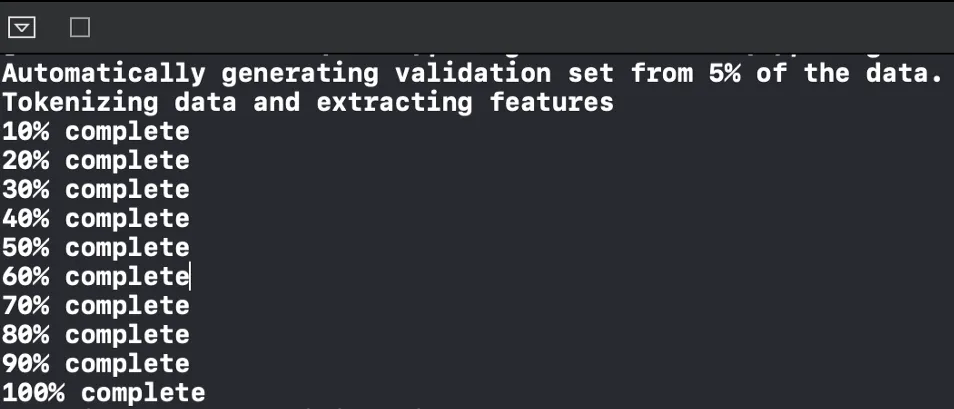
We use MLTextClassifier to train a text classification model—it takes the text column and the label column as parameters. We hit the play button to start training and track the process in the debug area.
Conclusion
MLDataTable is a fundamental structure for process non-image data in Create ML. In this tutorial, we learned the basics of how to use and manipulate this data table to prep it for training a machine learning model. Thanks for reading!
If you liked this story, you can follow me on Medium and Twitter. You can contact me via e-mail.
Comments 0 Responses