
Text summarization is a well-known task in natural language processing. In general, summarization refers to presenting data in a concise form, focusing on parts that convey facts and information, while preserving the meaning. To understand this better, we can think of summarization as a process to find a subset of data that contains all the information.
With the exponential growth of the Internet, people often find themselves overwhelmed with data and information, which in most cases is textual. Due to this, automatic text summarization is becoming a necessity for various fields like search engines, business analysis, market review, academics, and more. Automatic text summarization means generating a summary of a document without any human intervention.
This is broadly divided into two classes — extractive summarization and abstractive summarization. Extractive summarization picks up sentences directly from the original document depending on their importance, whereas abstractive summarization tries to produce a bottom-up summary using sentences or verbal annotations that might not be a part of the original document.
Building an abstractive summary is a difficult task and involves complex language modelling. In this article we’re going to focus on extractive text summarization and how it can be done using a neural network.
To understand the difference better, let’s consider the following paragraph-
“Educators all around the world have fears about instituting large systemic changes, and sometimes those fears are well grounded. However, we cannot afford to ignore the possibilities that AI offers us for dramatically improving the student learning experience. People need to understand the role of AI in improving the face of education in the years to come. The resistance faced by this new technology has to decrease because AI can not only help the teachers be more productive, but also make them more responsive towards the needs of the students.”
The extractive summary of this would be-
The abstractive summary of the same paragraph would be-
As you can see, the abstractive summary is much shorter and to the point than the extractive summary.
The Neural Network
Until now, various models have been proposed for the task of extractive text summarization. Most of them have treated this as a classification problem that outputs whether a sentence should be included in the summary or not. They compare each sentence with every other one to select the most commonly-used words and give a score to each sentence on this basis.
A threshold score is decided depending upon the length of the summary required, and every sentence having a higher score is then included in the summary. This is generally done using a Standard Naïve Bayes Classifier or Support Vector Machines.
For genre-specific summarization (medical reports or news articles), engineering-based models or models that are trained using articles of the same genre have been more successful, but these techniques give poor results when used for general text summarization.
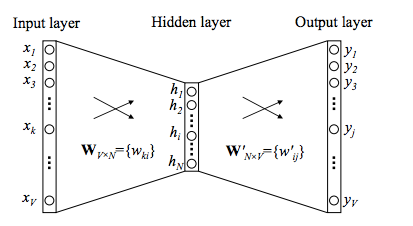
What if we could use a fully data-driven approach to train a feedforward neural network that gives reliable results irrespective of the genre of the document? A simple model consisting of one input layer, one hidden, and one output layer can be used for this task. This model would be able to generate a summary of arbitrarily-sized documents by breaking them into fixed-size parts and feeding them recursively to the network.
If you see the paragraph we summarized earlier, you’ll see that the summary contains the exact same sentences as in the original document were used:
These two sentences were selected by the model as most relevant to be included in the summary. The document is fed to the input layer, all the computation is done in the hidden layer, and an output is generated at the output layer as probability vectors, which determine whether a sentence is to be included into the summary or not.
A fixed number of sentences are selected from every run depending on the size of the summary required. Since the input to the network must be numbers, we need a way to convert sentences to a numerical form.
The best way of doing this is to convert the words to vector representations using the Word2Vec library. A tutorial for the same can be found here. Furthermore, these word vectors can be used to convert our sentences to vectors of fixed dimensions.
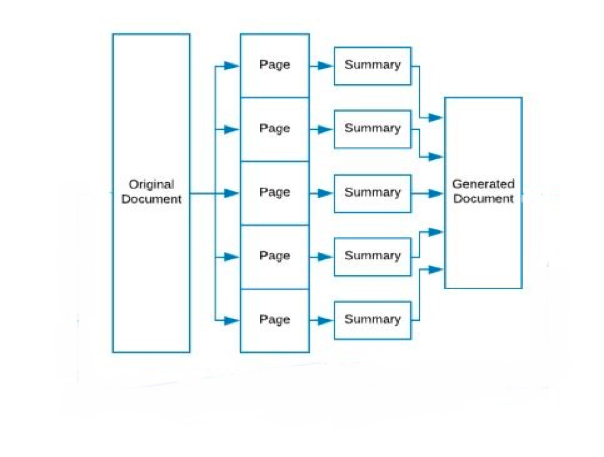
The biggest problem that this model faces is that if we convert each sentence to a fixed dimension vector, the length of the documents would vary widely. The size of the input layer is fixed and cannot be varied depending on the document length. To solve this problem, we use a completely new approach.
We divide the document into segments, each having a fixed number of sentences — let’s call these segments “pages” and the fixed number of sentences “length”. For each run of the network, we feed it with a single “page” and get a summary of that page. After the last run we concatenate all the summaries.
For pages that have less sentences than the “length”, the vector can be padded with zeroes. Another advantage of this approach is that we can test the model with different “lengths” and see which gives the best results.
This proposed model can prove extremely useful for generating extractive summaries, and this could run on devices with limited computational power like mobile phones.
Training and Evaluation
For training this model, DUC (Document Understanding Conferences) datasets can be used. These datasets include document-summary pairs, with each document having two summaries (both extractive). The only pre-processing required would be to convert them to text documents, as they are provided as XML pages.
The best way to evaluate this model would be to use ROUGE. It stands for Recall-Oriented Understudy for Gisting Evaluation. To evaluate the neural network, ROUGE compares the summaries generated by the network to human-generated summaries. This is the reason why it’s used extensively for evaluating automatic summaries and sometimes also for machine translations.
Applications of Automatic Text Summarization
Text summarization is becoming one of the most important tools in today’s fast-growing information age. It isn’t possible for humans to analyze and summarize large text documents in real time; therefore we need an accurate and efficient method to do the same.
The real-world applications of automatic text summarization are innumerable: generating news headlines, recording minutes of a meeting, summarizing notes for students, writing bulletins, and writing synopses are some of the most common use cases. Check out this spotlight of my app, Summary, which can help make some of these applications a reality
We might not realize this fact, but we are constantly reading and using summaries. We need a universal tool that can summarize text documents accurately, irrespective of their genres.
What can be improved?
The model proposed here is a very accurate and efficient way to generate summaries, but as always, it isn’t perfect. The major issue is that it uses the extractive text summarization technique. The problem with this technique is that it uses the exact same sentences as in the original document, and sometimes this may lead to a summary containing less important information because a part of a sentence may contain useful information, but the rest of it may be useless.
Another issue is the use of pronouns in the original document. When a certain sentence in the document containing a pronoun is included in the summary, it may be ambiguous to what the pronoun is referring to.
To solve these problems, we would have to shift to abstractive text summarization, but training a neural network for abstractive text summarization requires a lot of computational power and almost 5x more time, and it can not be used on mobile devices efficiently due to limited processing power, which makes it less useful.
Currently, extractive text summarization functions very well, but with the rapid growth in the demand of text summarizers, we’ll soon need a way to obtain abstractive summaries using less computational resources.
Refer to these for information on abstractive text summarization:
Some common models used till now for text summarization can be found here.
Comments 0 Responses