
In machine learning, a hyperparameter is a configuration variable that’s external to the model and whose value is not estimated from the data given.
Hyperparameters are an essential part of the process of estimating model parameters and are often defined by the practitioner.
When a machine learning algorithm is used for a specific problem, such as using a grid search or a random search algorithm, then you’re actually tuning the hyperparameters of the model to discover the values that result in the most accurate predictions.
What is Learning Rate?
Learning rate is one such hyperparameter that defines the adjustment in the weights of our network with respect to the loss gradient. In simple language, we can define it as how quickly our network replaces the concepts it has learned up until now with new ones.
To understand this better lets consider an example.
If a child sees ten birds and all of them are black in color, he might believe that all birds are black and would consider this as a feature when trying to identify birds. Imagine next he’s shown a yellow bird, and his parents tell him that it’s a bird. With a desirable learning rate, he would quickly understand that black color is not an important feature of birds and would look for another feature. But with a low learning rate, he would consider the yellow bird an outlier and would continue to believe that all birds are black. And if the learning rate is too high, he would instantly start to believe that all birds are yellow even though he has seen more black birds than yellow ones.
It’s really important to achieve a desirable learning rate because both low and high learning rates result in wasted time and resources. A lower learning rate means more training time, and more time results in increased cloud GPU costs; and a higher rate could result in a model that might not be able to predict anything accurately.
A desirable learning rate is one that’s low enough so that the network converges to something useful but high enough so that it can be trained in a reasonable amount of time.
Determining learning rate
We’ve just discussed why learning rate is one of the most important hyperparameters in machine learning — this makes it important to configure it effectively.
It isn’t possible to calculate an optimal learning rate for a model on a given dataset using analytical methods, but we can obtain a good enough learning rate using trial and error.
Generally, due to high randomness of the weights, a relatively large default value is taken and decreased during training. A common and naive starting point for the learning rate is 0.1, followed by exponentially lower values like 0.01 and 0.001.
When training is initiated using a large learning rate, the loss doesn’t improve (and sometimes even increases) during the first few iterations. When a smaller rate is used, at a certain point the value of the loss function starts decreasing in the first few iterations itself. An ideal value for the learning rate to start training from is generally 2 orders lower than this.
To investigate whether the learning rate is too large or too low, diagnostic plots such as the line plot of loss over training epochs can be used. This plot shows whether the model has learned too quickly or is learning too slowly.
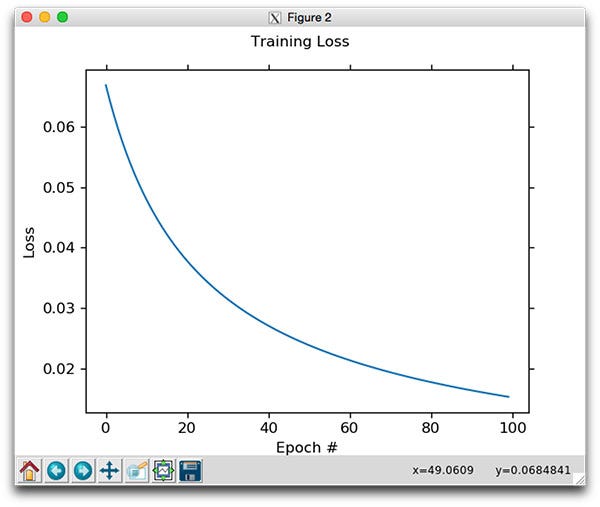
A good learning rate can also be determined using an alternative approach in which you can perform a sensitivity analysis of the learning rate that can easily highlight an order of magnitude where a good learning rate may reside, and also the relation between learning rate and performance.
Several other approaches (which can be found here, here and here) have been proposed and used by data scientists all over the world, but no matter which method you use, determining a good learning rate is a challenging and time-consuming task.
Adaptive learning rate
An alternative to using a fixed learning rate hyperparameter is to use adaptive learning rates. Here, the training algorithm monitors the performance of the model and automatically adjusts it.
The most basic example is to make the learning rate smaller once the performance of the model reaches a plateau, such as by decreasing the learning rate by a factor of two or an order of magnitude. Or, the learning rate can be increased again if the performance doesn’t improve.
A model using adaptive learning rates is most likely to outperform a model with a badly configured learning rate.
Further Reading
It’s clear that configuring a model’s learning rate is a crucial task, and whatever approach you opt for, it will be time-consuming and challenging.
To read more on how to configure the learning rate, check out the following:
Also, a powerful technique that involves selecting a range of learning rates for a neural network has been discussed in the paper “Cyclical Learning Rates for Training Neural Networks” by Leslie N. Smith.
Comments 0 Responses