
Our experience of the world is multimodal — we see objects, hear sounds, feel the texture, smell odors and taste flavors and then come up to a decision. Multimodal learning suggests that when a number of our senses — visual, auditory, kinesthetic — are being engaged in the processing of information, we understand and remember more. By combining these modes, learners can combine information from different sources.
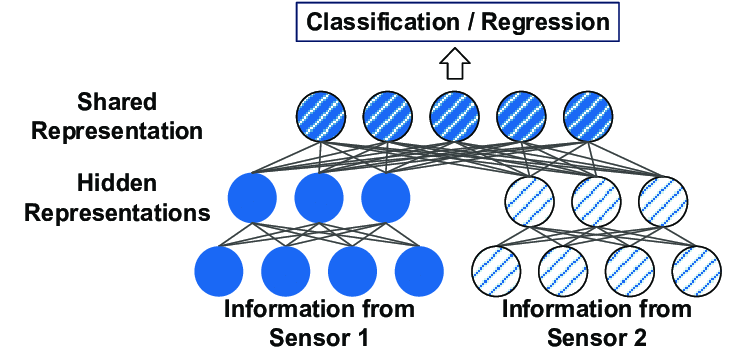
When it comes to deep learning, the approach of training models on only source of information—be it images, text, audio, video—is commonplace.
But there’s also a way to build models that incorporate two data types—say, text and images—at the same time. Working with multimodal data not only improves neural networks, but it also includes better feature extraction from all sources that thereby contribute to making predictions at a larger scale.
Benefits of multimodal data
Modes are, essentially, channels of information. These data from multiple sources are semantically correlated, and sometimes provide complementary information to each other, thus reflecting patterns that aren’t visible when working with individual modalities on their own. Such systems consolidate heterogeneous, disconnected data from various sensors, thus helping produce more robust predictions.
For example, in an emotion detector, we could combine information gathered from an EEG and also eye movement signals to combine and classify someone’s current mood—thus combining two different data sources for one deep learning task.
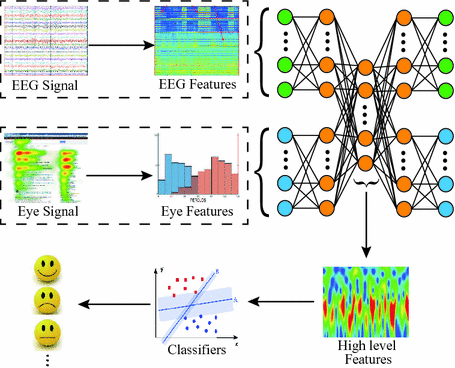
How multimodal learning works
Deep neural networks have been successfully applied to unsupervised feature learning for single modalities—eg. text, images or audio. Here, we aim to do information fusion from different modalities to improve our network’s predictive ability. The overall task can mainly be divided into three phases — individual feature learning, information fusion and testing.
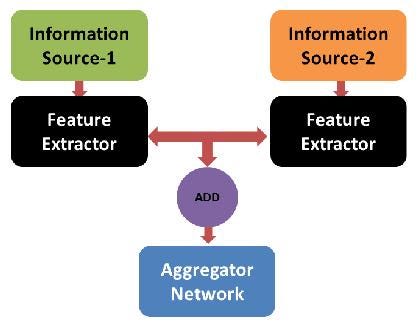
We’ll need the following:
- At least two information sources
- An information processing model for each source
- A learning model for the combined information
Given these prerequisites, let’s take a look at the steps involved in multimodal learning in more detail
Representation of modalities
A first fundamental step is learning how to represent inputs and summarizing the data in a way that expresses the multiple modalities. The heterogeneity of multimodal data makes it challenging to construct such representations.
For example, text is often symbolic, while audio and visual modalities will be represented as signals. For more details have a look at this foundational research paper on multimodal learning.
Translation
A second step is to addresses how to translate (map) data from one modality to another. Not only is the data heterogeneous, but the relationship between modalities is often open-ended or subjective. There has to be a direct relation between (sub)elements from two or more different modalities.
For example, we may want to align the steps in a recipe to a video showing the dish being made. To tackle this challenge, we need to measure similarity between different modalities and deal with possible long range dependencies and ambiguities.
Feature extraction
Features need to be extracted from individual sources of information by building models that best suit the type of data. Feature extraction from one source is independent from another.
For example, in image-to-text translation, the features extracted from images are in the form of finer details, like edges and environmental surroundings, while corresponding features extracted from text are in form of tokens.
After all the features important for prediction are extracted from both data sources, it’s time to combine the different features into one shared representation.
Fusion and Co-learning
The next step is to combine information from two or more modalities to perform a prediction.
For example, for audio-visual speech recognition, a visual description of lip motion is fused with the audio input to predict spoken words. The information coming from these different modalities may have varying predictive power and noise topology, with possibly missing data in at least one of the modalities. For more details do have a look at this source.
Here, we can take a weighted combination of the subnetworks so that each input modality can have a learned contribution (Theta) towards the output prediction. This enables the inclusion of the useful features from different sources more as compared to others.
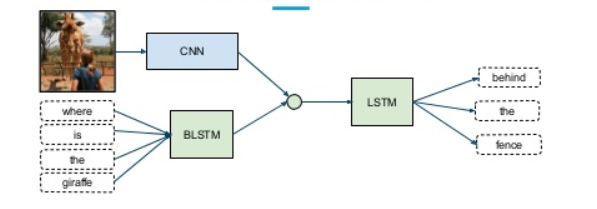
The model architecture for different modalities can be chosen according to the need—eg. an LSTM for text data or a CNN for images. We can then combine the features and pass it to the final classifier by aggregating the models.
Conclusion
The primary thing to keep in mind, when dealing with multimodal datasets, is the aggregation of features. Everything up until feature extraction from individual data sources follows the same rules and steps and is independent of other sources. The fusion of information, keeping in mind the weightage to be given to each data type, is the primary area of research.
To learn more about specific multimodal learning techniques, check out this GitHub repo:
Have a happy learning! Do share your experiences. If there are any areas, papers, and interesting datasets to work on, please let me know!
Comments 0 Responses