
Hyperparameters have inevitably been used by anyone who has practiced machine learning, either in industry, academia, or even self-study. It can be an intimidating term if you’re just starting your dive into machine learning.
And once you’ve figured out how to pronounce the term, the key to understanding hyperparameters is knowing how they differ from parameters.
It took me a bit more than a simple Google search to fill in the details. In this blog post, I’m going to share what I’ve learned, and at the end of the post we should be able to:
- Demystify the meaning of hyperparameters and explain how they differ from parameters
- Understand the importance of using hyperparameters
- Optimize and tune hyperparameters in Sci-kit learn using Grid Search and Randomized Search
What are Hyperparameters?
Hyperparameters are configuration variables that are external to the model and whose values cannot be estimated from data. That is to say, they can’t be learned directly from the data in standard model training. They’re almost always specified by the machine learning engineer prior to training.
And we do this specification by trial and error until a best prediction score is obtained. Let’s take the simple Support Vector Machine (SVM) example below and use it to explain hyperparameters even further. SVM picks a hyperplane separating the data, but maximizes the margin. (For more information about SVMs and how they work visit here)
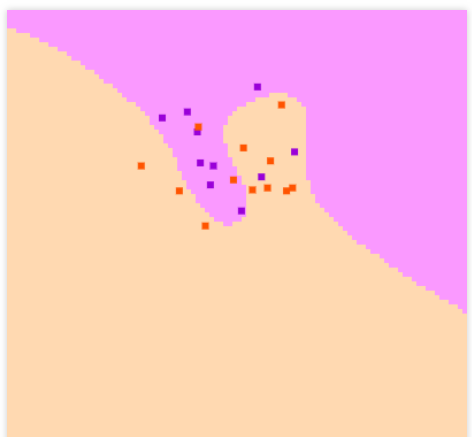
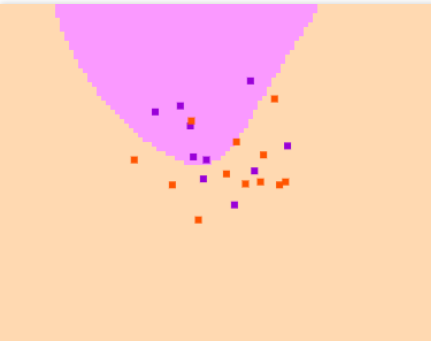
In the two instances visualized above, we can clearly see the impact of having different C values on the model. The C value represents the regularization constant. Very high C values will have a large penalty for non-separable points, and this can often cause overfitting, as seen in figure 1 (top).
In figure 2 (bottom), I had to manually input different C values before the data points could be separated into their respective classes (C=45). This can be an extremely difficult task (we’ll later see how to optimize this in sklearn).
Parameters, on the other hand, can be learned from data and don’t need to be manually set by the ML engineer. They are internal to the model. Examples of parameters include the coefficients of a linear and logistic regression.
Why are hyperparameters important?
Hyperparameters define higher-level concepts about the model, such as its complexity and/or its ability to learn (eg: learning rate). With the right values of hyperparameters will eliminate the chances of overfitting and underfitting. For instance, the learning rate hyperparameter determines how fast or slow your model trains. (Read more here)
How do we optimize hyperparameter tuning in Scikit-learn?
We can optimize hyperparameter tuning by performing a Grid Search, which performs an exhaustive search over specified parameter values for an estimator. This simply means that all you need to do is specify the hyperparameters you want to experiment with, and the range of values to try, and Grid Search will perform all the possible combinations of the hyperparameter values using cross-validation.
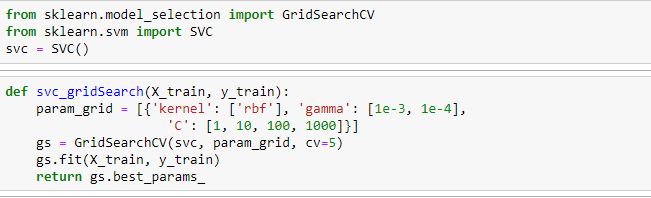
So all we have to do is import GridSearchCV from sklearn.model_selection and define a parameter grid. A parameter grid is a Python dictionary with hyperparmeters to be tuned as keys, and a respective range of values. The range of values are used in different combinations when GridSearch is running. It will later train the model 5 times, since we are using a cross validation (CV) = 5. After fitting the data, we can return the best parameters that will give a better prediction score.
The same process can be done for Randomized Search. With Randomized Search, however, there’s a larger hyperparameter search space. And it performs the search by randomly picking out the hyperparameters and finding its combinations for every iteration. It’s very often an excellent choice when there’s high dimensionality, since it arrives at a good combination very fast.
Conclusion
In this blog post, we’ve learned that hyperparameters are different from parameters in that they’re external to models, cannot be learned from data, and are inputted manually by ML engineers. We’ve also explored why hyperparameters are so important.
Additionally, we’ve learned that finding the right values for hyperparameters can be a frustrating task and can lead to underfitting or overfitting machine learning models. We saw how this hurdle can be overcome by using Grid Search & Randomized Search — which optimize tuning of hyperparameters to save time and eliminate the chance of overfitting or underfitting by random guessing. And finally, we saw key differences between the two, their strengths, and how to implement GridSearch in Sci-kit Learn.
I hope you enjoyed reading this blog post. As a general rule of thumb, any time you want to optimize tuning hyperparameters, think Grid Search and Randomized Search. Cheers!
Comments 0 Responses