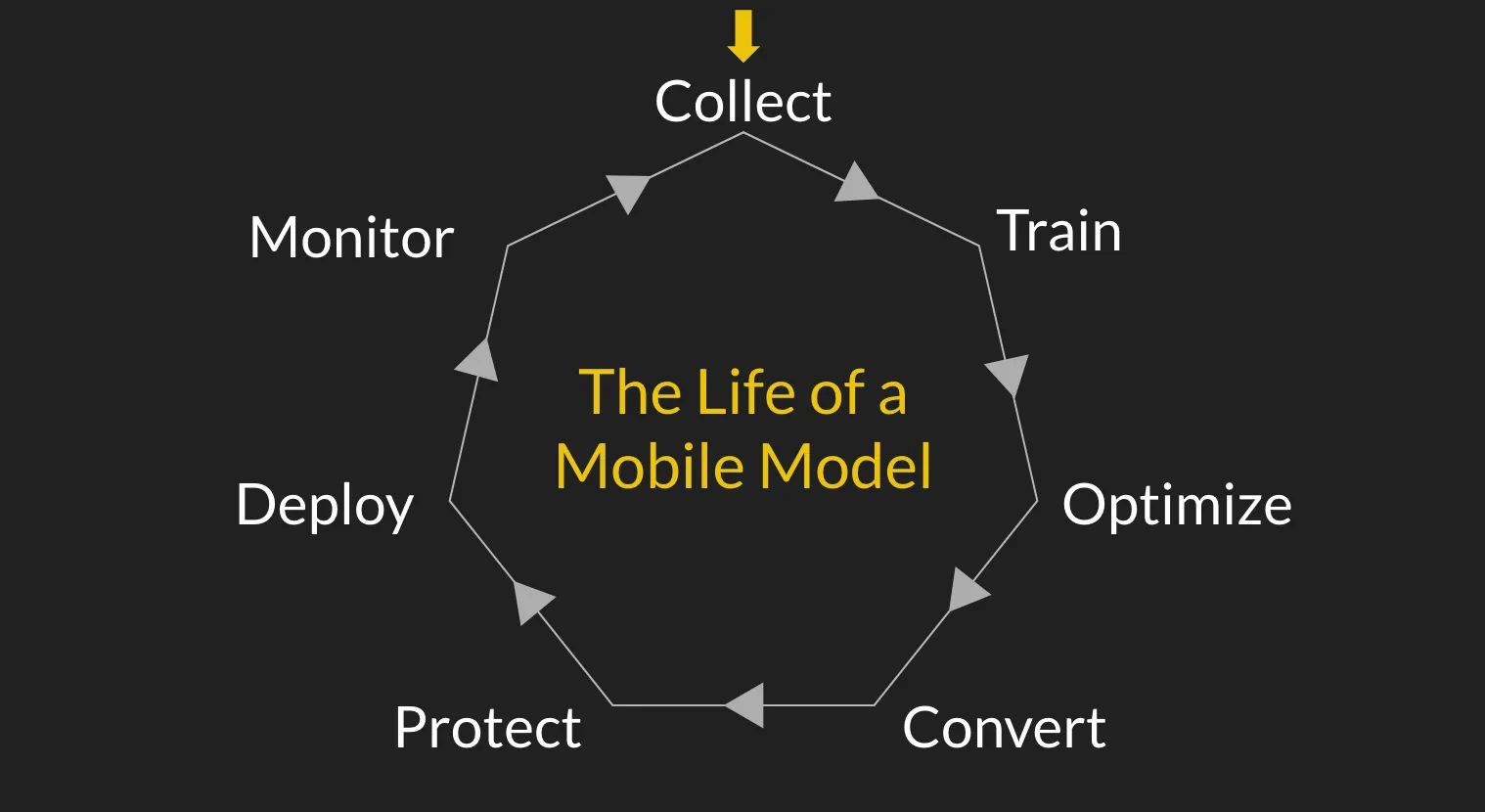
This is part 3 of an ongoing series on language models, starting with defining neural machine translation and exploring the transformer model architecture, and then implementing GPT-2 from scratch.
Specifically, in the first part of the series, we implemented a transformer model from scratch, talked about language models in general, and also created a Neural Machine Translator.