
Currently, different domains of machine learning software and hardware have different compiler infrastructures. There are number of challenges posed by this dynamic, including:
- the high cost of building domain-specific compilers
- innovation in one domain does not benefit other domains
- connecting existing compilers together is a challenge
MLIR seeks to address this software fragmentation by building a reusable and extensible compiler infrastructure. In this piece, we’ll look at a conceptual view of MLIR.
The Need for MLIR
MLIR seeks to promote the design and implementation of code generators, optimizers, and translators at various stages of abstraction across different application domains. The need for MLIR arose from the realization that modern machine learning frameworks have different runtimes, compilers, and graph technologies. For example, TensorFlow itself has different compilers for different frameworks.
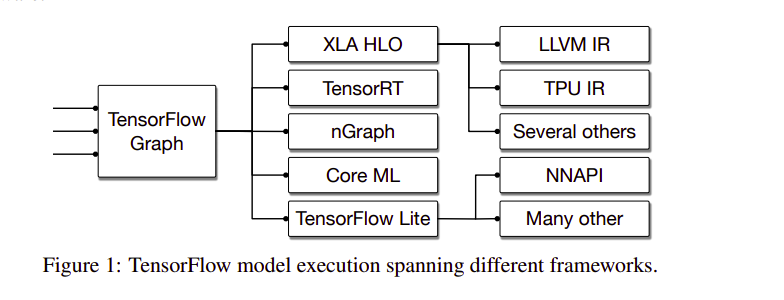
This kind of design poses various challenges to the end-user:
- poor error messages
- unpredictable performance
- failures in edge cases
- difficulties in supporting new hardware
As shown below, different languages have different compilation pipelines with multiple mid-level intermediate representations. LLVM is a collection of modular and reusable compiler and toolchain technologies.
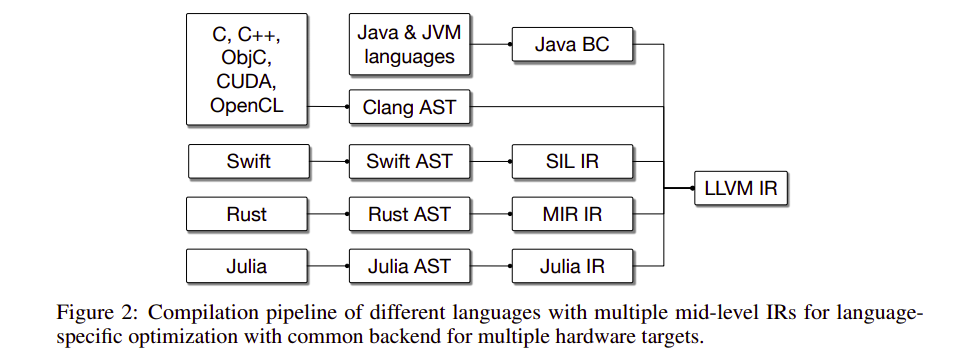
MLIR Design Principles
In order to achieve a global compiler infrastructure, MLIR is built on the following principles.
Little Built-in, Everything Customizable
The system is built such that most of the intermediate representation is fully customizable. The most common types, operations, and attributes in intermediate representations are used to express everything else.
Customizability enables the system to adapt to changing needs and desires. This allows expression of different abstractions, such as machine learning graphs, mathematical abstractions, and instruction-level intermediate representations, such as LLVM IR.
Static Single Assignment (SSA) and Regions
SSA is a commonly-used method in compiler intermediate representations. It’s advantageous because it makes data flow analysis simple and sparse. Multiple existing intermediate representations use a flat, linearized Control Flow Graph (CFG).
However, representing higher-level abstractions led to the introduction of nested regions as a first-class concept in intermediate representation. In order to support heterogeneous compilation, the system supports the expression of structured control flow, concurrency constructs, and closure in source languages. To do this, CFG-based analyses and transformations have to be made to compose over nested regions. Making this a reality required the normalization and canonization properties of LLVM to be sacrificed.
Progressive Lowering
The system supports the lowering of a high-level representation down to the lowest level. This is done in stages, along multiple levels of abstraction, and is especially crucial because the compiler has to support different programming models and platforms.

Maintain Higher-level Semantics
The system retains higher-level semantics and computation structures that are needed for analysis and performance optimization. This ensures that operations (such as loops) and their structures are maintained throughout different transformations.
Intermediate Representation Validation
Since this is an open ecosystem, the availability of a robust validation mechanism is crucial. This ensures the detection of compiler bugs and captures intermediate representation invariants.
Declarative Rewrite Patterns
For this system, common transformations should be implementable as rewrite rules that are expressed declaratively. Modeling program transformations as rewrite systems aids in ensuring extensibility and incremental lowering capabilities. The rewrite rules and machine descriptions are built such that they work through multiple levels of abstraction.
Source Location Tracking and Traceability
To address the lack of transparency common in compilation systems, the original location and applied transformations of an operation are traceable within the system. This possibility helps in sending more relevant and meaningful error messages to end users.
MLIR and TensorFlow
In TensorFlow, MLIR will be crucial in bringing interoperability to the entire ecosystem. Models will perform faster and become easier to debug. MLIR will also provide standard infrastructure for researchers and make integration for hardware partners simpler.

Here’s a look at the places the MLIR infrastructure will be applied in TensorFlow.
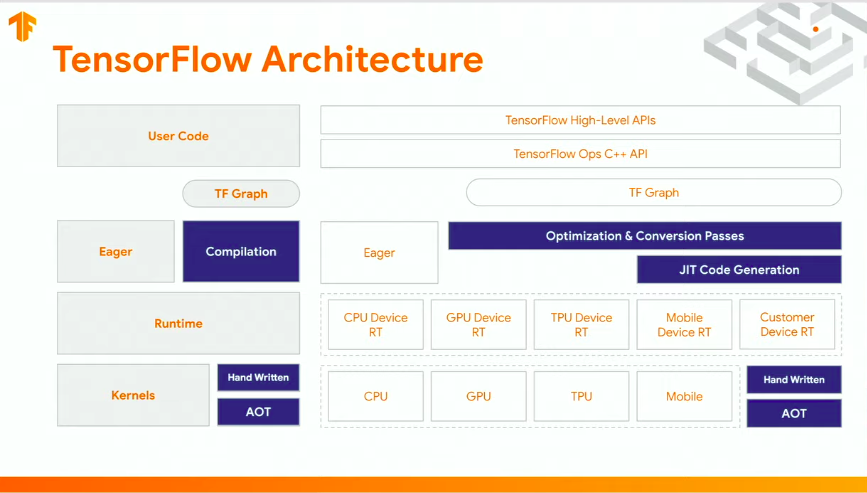
MLIR Application in TensorFlow
Currently, MLIR is being used in the TF Lite converter. As a result, users get better conversion error messages.

MLIR Support
MLIR is supported by 95% of the industry. This means that it will become increasingly easier to apply machine learning, even with the invention of new hardware accelerators.

What’s Next for MLIR
Looking ahead, we can expect to see more usage of MLIR in TensorFlow graph optimizations and the onboarding of new hardware partners to the project. MLIR will also integrate very tightly with the new TensorFlow runtime. The new runtime is expected to ship in new versions of TensorFlow later this year.

Hopefully, this piece gives you some background on MLIR and its usage. If you’d like to learn more, check out the resources below.
Comments 0 Responses