
In order to understand computer vision, we must first understand how we’ve evolved to see the world. Not only is it important to investigate how we see but why our sight evolved this way.
We use computer vision in some of our solutions at Wallscope, so it was important to start from the beginning and ensure I had a solid understanding.
In case you missed the introduction to this series, Joseph Redmon released a series of 20 lectures on computer vision in September of 2018. As he’s an expert in the field, I wrote a lot of notes while going through his lectures. I am tidying my notes for my own future reference but am posting them on Medium also, in case they’re useful for others.
Contents
- The Evolution of Eyes
- How Do Our Eyes Work?
- The Brain – Our Visual Processor
- 3D Vision
- Light
- Recreating Color on a Screen
- Conclusion
The Evolution of Eyes
To begin with, we need to consider why we have eyes in the first place. The obvious answer is of course to see the world, but in order to fully understand this, we must start by investigating the most basic form our eyes took.
Eyespots
Simple eyes, named eyespots, are photosensitive proteins with no other surrounding structure. Snails, for example, have these at the tip or base of their tentacles.

Our vision evolved from eyespots, which can only really detect light and a very rough sense of direction. No nerves or brain processing is required, as the output is so basic. But snails can use these to detect and avoid bright light to ensure they don’t dry out in the sun.
Importantly, eyespots have extremely low acuity, as light from any direction hits the same area of proteins.
Pit Eyes
Slightly more complex are pit eyes. These are essentially eyespots in a shallow cup-shaped pit. These have slightly more acuity, as light from one direction is blocked by the edge of the pit, increasing directionality. If only one side of the cells are detecting light, then the source must be to one side.
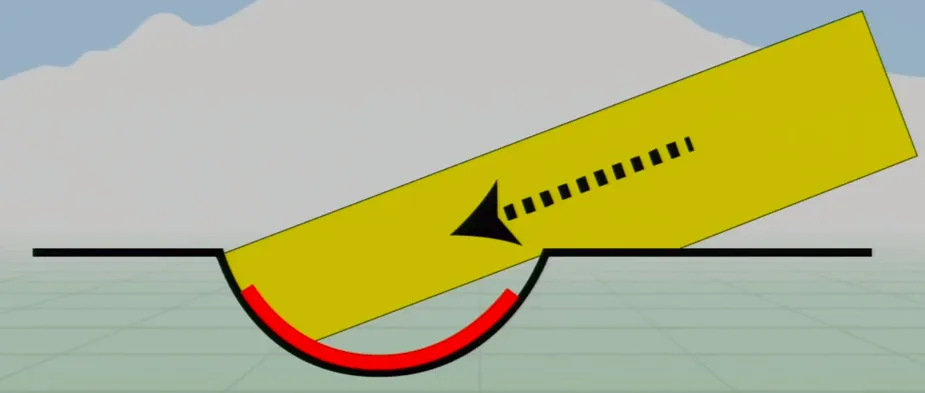
These eyes still have low acuity, as they’re relatively simple, but they’re very common in animals. Most animal phyla (28 of 33) developed pit eyes independently. This is due to the fact that recessed sensors are a simple mutation and increased directionality is such a huge benefit.
Complex Eyes
Many different complex eye structures now exist, as different animals have evolved with various needs in diverse environments.
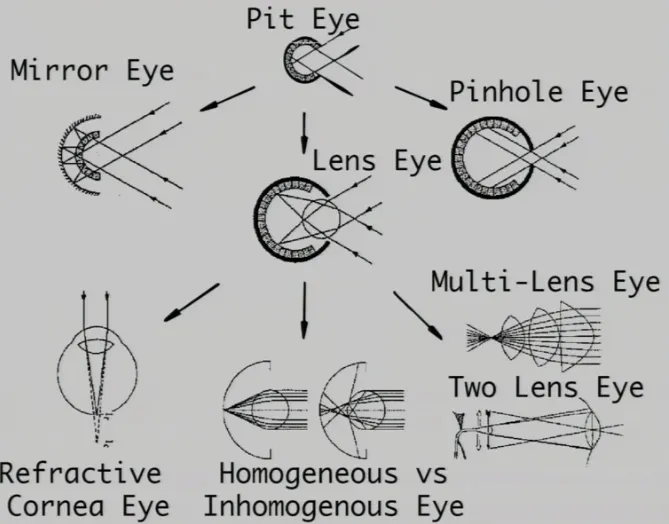
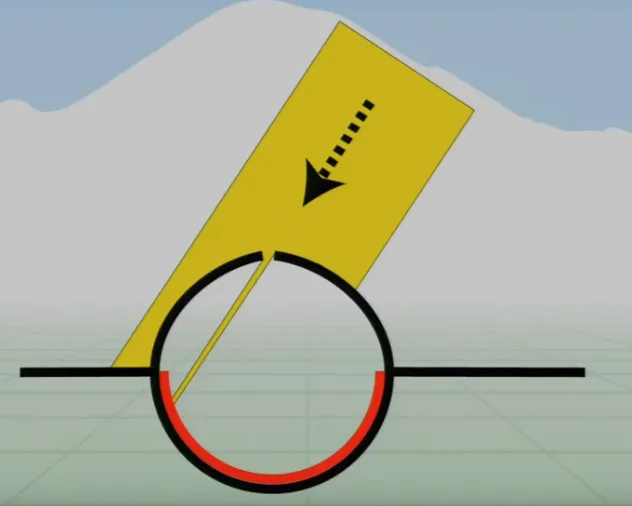
Pinhole Eyes are a further development of the pit eye as the ‘pit’ has recessed much further, only allowing light to enter through a tiny hole (much like some cameras). This tiny hole lets light through, which is then projected onto the back surface of the eye or camera.
As you can see in the diagram above, the projected image is inverted, but the brain handles this (post-processing), and the benefits are much more important. If the hole is small enough, the light hits a very small number of receptors—we can therefore detect exactly where the light is coming from.
As mentioned, eyespots have basically no acuity and pit eyes have very low acuity, as some light is blocked by the edges of the ‘pit’. Complex eyes, however, have very high acuity.
That raises another question: What are the advantages that evolved our eyes even further than pinhole eyes?
Humans have Refractive Cornea Eyes, which are similar to pinhole eyes but curiously evolved to have a larger holes. To combat the loss of acuity this difference causes, a cornea and lens is fitted within the opening.
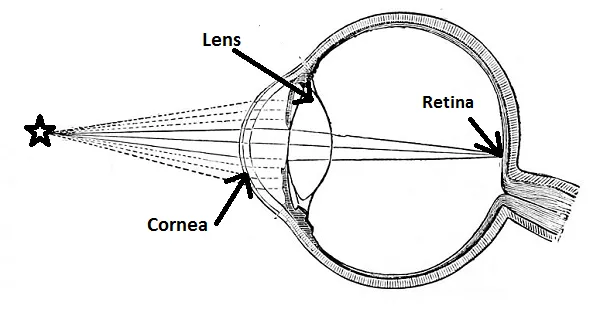
The high acuity of the pinhole eye is a result of the fact that only a tiny amount of light could get through the hole, and therefore only a few receptors in the retina are activated.
As you can see in the diagram above, the lens also achieves this by focusing the incoming light to a single point on the retina.
The benefit of this structure is that high acuity is maintained to allow accurate direction, but a lot more light is also allowed in.
More light hitting the retina allows more information to be processed, which is particularly useful in low-level light (hence why species tend to have at least a lens or cornea). Additionally, this structure gives us the ability to focus.
Focusing incoming light onto the retina is mainly done by the cornea, but its focus is fixed. Re-focusing is possible thanks to our ability to alter the refractive index of each lens. Essentially, we can change the shape of the lens to refract light accurately from different sources onto single points on the retina.

This ability to change the shape of our lenses is how we can choose to focus on something close to us or in the distance.
If you imagine sitting in a train and looking at houses in the distance, you’d not notice a blurry hair on the window. Conversely, if you focused on the hair (by changing the refractive index of your lenses) the houses in the distance would be blurry.
As you may have noticed, complex eyes have all evolved with the same goal — better visual acuity. Only 6 of the 33 animal phyla have complex eyes, but 96% of all known species have them, so they are clearly very beneficial.
This is of course because higher acuity increases the ability to perceive food, predators, and mates.
How Do Our Eyes Work?
We now know that light passes through our cornea, humours, and lens to refract light to focus on our retina. We also know this has all evolved to increase acuity with lots of light for information—but what next?
Once light hits the retina, it’s absorbed by photosensitive cells that emit neuro-transmitters through the optical nerve to be processed by our visual cortex.
Unlike cameras, our photosensitive cells (called rods and cones) are not evenly distributed or even the same as each other.
Rods and Cones
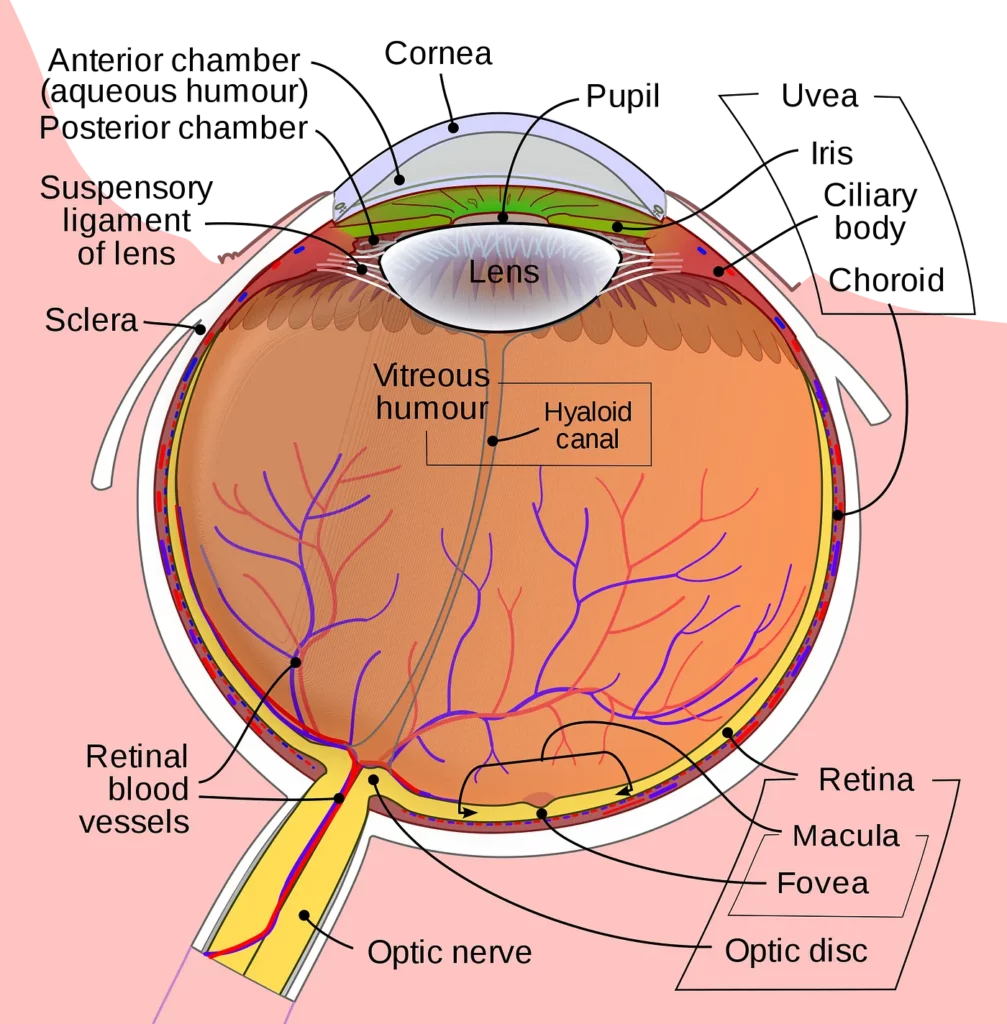
There are around 126 million photosensitive cells in the retina that are found in different areas and used for very different purposes.
Cones are predominantly found in the centre of the retina, called the fovea, and rods are mainly in the peripherals. There is one spot of the retina that contains neither, as this is where the optic nerve connects to the retina — commonly known as the blind-spot.
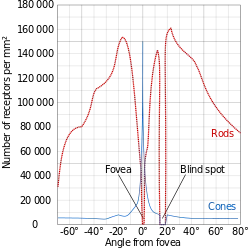
Interestingly, Octopuses have very similar eyes but do not have a blind-spot. This is because our optic nerve comes out of the retina into the eye and then back out, whereas optic nerves in an octopus come out in the opposite direction. Light can not pass through nerves; hence, we have a blind-spot.
Rods, predominantly found in our peripherals as mentioned, make up the significant majority of our photosensitive cells, as we have roughly 120 million of them in each eye!
We use rods predominantly in low light conditions, and for this reason, they don’t see color. They respond even if hit by a single photon, so they’re very sensitive but respond slower.
Rods take a relatively long time to absorb light before emitting a response to our brain, so they work together. Information is pooled by multiple rods into batches of information that get transmitted.
Rods are so adapted for low light vision that they’re unfortunately very poor in bright light because they saturate very quickly. This is why it takes so long for our eyes to adjust from bright to low light.
For example, if you’ve ever gone stargazing and then glanced at your phone screen, you’ll notice that it takes 10 to 15 minutes for your ‘night vision’ to return.
This is because the phone light saturates your rods, and they have to go through the chemical process to desaturate the proteins for them to absorb light again.
Cones, on the other hand, are found in the fovea and are much rarer, as each eye only contains around 6 million of them.
This is a lot less than the number of rods, but our cones are a lot more concentrated in the centre of our retina for the specific purpose of fine grained, detailed color vision (most of our bright and colorful day-to-day lives).
Our cones can see quick movement and have a very fast response time (unlike rods) so they work brilliantly in the quickly-changing environments that we inhabit.
The Fovea is where all the cones are concentrated, but it’s only 1.5mm wide and therefore very densely packed with up to 200,000 cones/mm².
This concentration of cones makes the fovea the area of the retina with the highest visual acuity, which is why we move our eyes to read. To process text, the image must be sharp and therefore needs to be projected onto the fovea.
Our peripheral vision contains few cones, reducing acuity, but the majority of our rods. This is why we can see shapes moving in our peripherals but not much color or detail. Try reading this with your peripherals for example, it is blurry and clearly does not have the same acuity of vision.
As mentioned above, the advantage is ‘night vision’, and this is clear when stargazing, as stars appear bright when looking at them in your peripheral vision, but dim when you look directly at one.
Pilots are taught to not look directly at other planes for exactly this reason—they can see plane lights better in their peripherals.
There are other differences between peripheral and foveal vision. Look at this illusion and then stare at the cross in the centre:

If you look directly at the change in the purple dots, you can clearly see that the purple dots are simply disappearing for a brief moment in a circular motion.
If, however, you stare at the cross, it looks like all the purple dots disappear and a green dot is travelling in a circle… why?
When using your foveal vision, you are following the movement with your eyes. When fixating on the cross however, you are using your peripheral vision. The important difference is where you’re primarily focusing.
The purple light hits the exact same points on your retina, as you’re not moving your eyes. Your rods in those points therefore adjust to the purple so you don’t see them (hence they appear to disappear), and the adjustment makes grey look green.
Our eyes adjusting and losing sensitivity over time when you look directly at something could cause major problems—so how do we combat this?
Fixational Eye Movement
There are many ways that we compensate for this loss in sensitivity over time, but all these ways essentially do the same thing — expose different parts of the retina to light.
There are a couple of large shifts (large being a relative term here) and a much smaller movement.
Microsaccades (one of the large movements) are sporadic and random small versions of saccades.
You don’t notice these happening, but these tiny short movements expose new parts of the retina to the light.
Ocular drift is a much slower movement than microsaccades—more of a roaming motion in conjunction with what you’re fixating on. This is a random but constant movement.
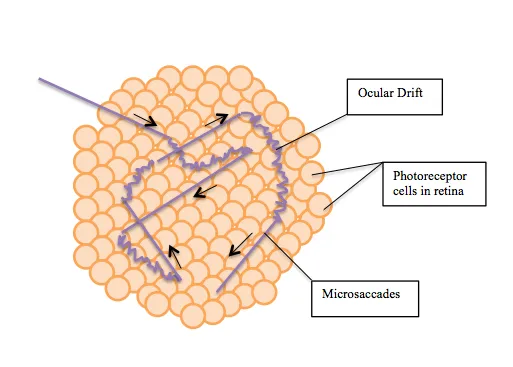
This image illustrates the constant ocular drift combined with sporadic microsaccades.
Finally, microtremors are tiny vibrations that are so small that light doesn’t always change which receptor it’s hitting, just the angle at which it hits it.
Amazingly, these microtremors are synced between eyes to vibrate at the exact same speed.
These three fixational eye movements allow us to see very fine-grained detail!
In fact, the resolution of our fovea is not as high as you might expect. Microsaccades, ocular drift, and microtremors help our brains build more accurate mental models of what’s happening in the world.
The Brain — Our Visual Processor
All the information we’ve discussed so far gets transmitted through our optical nerves—but then what?
Our brain takes all of these signals and processes them to give us vision!
It’s predominantly thought that our brains developed after our eyes. For example, jellyfish have very complex eyes that connect directly to their muscle tissue for quick reactions.
There’s very little point in having a brain without sensory input, so it’s likely that we developed brains because we had eyes, as this allows complex responses beyond just escape reactions.
Ganglia
There are roughly 1 million ganglia in each eye that transmit info to the brain. We know there are way more rods than there are ganglia, so compression must take place at this point, and our photoreceptors must complete some pre-processing.
There are two types of ganglia: M-cells and P-cells.
M-Cells:
Magnocellular cells transmit information that help us perceive depth, movement, orientation, and positions of objects.
P-Cells:
Parvocellular cells transmit information that help us perceive color, shape, and very fine details.
These different types of ganglia are connected to different kinds of photoreceptors depending on what they’re responsible for. But they all connect to the visual cortex.
Visual Cortex
The visual cortex contains at least 30 different substructures, but we don’t know enough to build a coherent model. We do know, however, that information from the ganglia is passed to the primary visual cortex, followed by the secondary visual cortex.
V1 — Primary Visual Cortex:
This area of the visual cortex performs low-level image processing — like edge detection, for example.

V2 — Secondary Visual Cortex
Following V1, this area of the visual cortex helps us recognize object sizes, colors, and shapes. It’s often argued that visual memory is stored in V2.
From V2, the signals are sent to V3, V4, and V5 but also fed back to V1 for further processing.
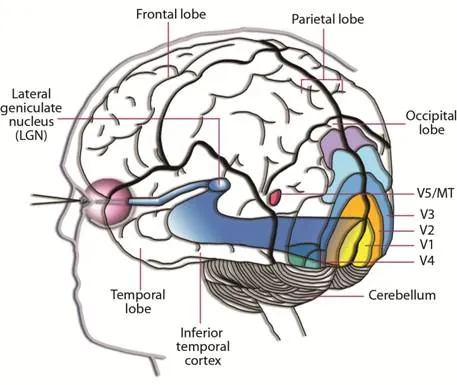
It’s theorized (and generally accepted) that the information passes through V1, through V2, and is then split and streamed to both the ventral and dorsal systems for two very different purposes.
The Ventral Dorsal Hypothesis
Instead of listing the differences between the two systems, I have cut the slide from Joseph Redmon’s lecture:
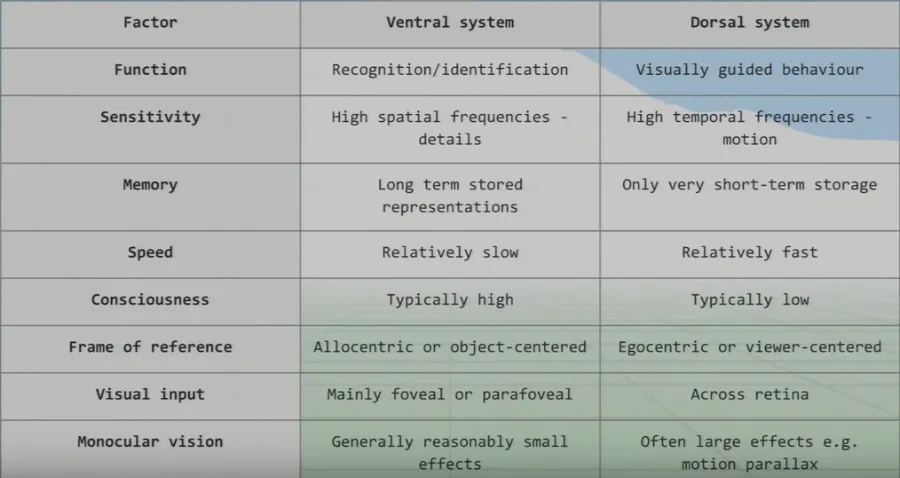
Ventral System
This is essentially our conscious, fine-grain detailed sight that we use for recognition and identification. This system takes the high-detail foveal signals, as we need it to consciously see in the greatest detail possible.
Since we need such high detail (and most of this detail comes from the brain’s visual processing), the processing speed is relatively slow when compared to the dorsal system.
Dorsal System
Why would we need unconscious vision? If someone threw a ball at you right now, you’d move your head to dodge it very quickly, but the ventral system has slow processing speed.
We can dodge something and then look for the thrown object afterwards because we don’t know what was thrown!
We therefore did not consciously see the object. Instead, we reacted quickly thanks to our very fast and unconscious vision from our dorsal system.
We also use this ‘unconscious vision’ while walking and texting. Your attention is on your phone screen yet you can avoid bins, etc. on the street.
We use both systems together to pick up objects, as well—let’s say a glass. The ventral system allows us to see and locate the glass; then the dorsal guides our motor system to pick it up.
This split is really seen when sections of the brain are damaged!
Dorsal Damage
If people damage their dorsal system, they can recognize objects without a problem but struggle to then pick objects up. They find it really difficult to use vision for physical tasks.
Ventral Damage
The majority of the information in the dorsal system isn’t consciously accessible, so ventral damage renders a person blind. Interestingly however, even though they cannot consciously see or recognize objects, they can still do things like walk around obstacles.
This man walks around obstacles in a corridor even though he cannot see and later, when questioned, is not consciously aware of what was in his path:
The human brain and vision have co-evolved and are tightly knit. The visual cortex is the largest system in the brain, accounting for 30% of the cerebral cortex and two thirds of its electrical activity.
This tightly knit, complex system is still not fully understood, so it’s highly-researched and new discoveries are made all the time.
3D Vision
We have covered a lot of detail about each eye, but we have two. Do we need two eyes to see in three dimensions?
Short answer: No.
There are, in fact, many elements that help our brain model in three dimensions with information from just a single eye.
One Eye
Focusing provides a lot of information on depth, like how much the lens has to change and how blurry parts of the image are.
Additionally, movement also helps this, as a nearby car moves across our field of vision much faster than a plane (which is actually traveling much faster) in the distance. Finally, if you’re moving (on a train for example), this parallax effect of different objects moving at different speeds still exists.
All of this helps us judge depth using each eye individually. It is, of course, widely known that our ability to see in three dimensions is greatly assisted by combining information from both eyes.
Two Eyes
What we all mainly consider depth perception is called stereopsis. This uses the differences in the images from both eyes to judge depth.
The closer something is to you, the bigger the difference in visual information from each eye. For example, if you hold a finger up in front of you and change the distance from your eyes while closing each eye individually — you’ll see this in action.
If you move your finger really close to your face, you’ll go cross-eyed. The amount your eyes have to converge to see something also helps with depth perception.
All of this information is great, but the brain has to tie it all together, add in its own considerations, and build this world model.
Brain
In a similar fashion to stereopsis and parallax sight, our brain perceives kinetic depth. Essentially, your brain infers the 3D shapes of moving objects. This video illustrates this amazingly:
Our brains can also detect occlusion, such as “I can only see half a person because they’re behind a car”.
We know the obstructed object is farther away then the object that’s doing the obstructing. Additionally, our brain remembers the general size of things that we’re familiar with so we can judge whether a car is close or far away based on how big it is.

This is a famous illusion that plays with our brains’ understanding of occlusion.
Finally, our brains also use light and shadows to build our 3D model of the world. This face is a good example of this:

We can judge the 3D shape of this persons nose and philtrum (between the nose and upper lip) solely based on the highlights and shadows created by the light.
Tying this all together, we’re very skilled at perceiving depth.
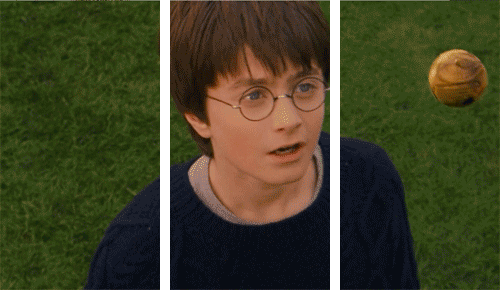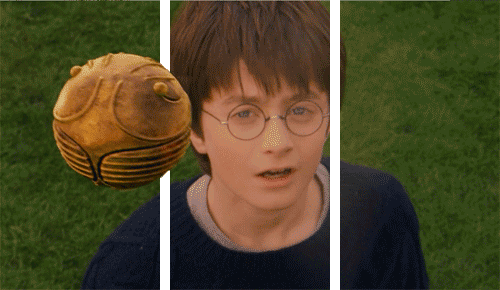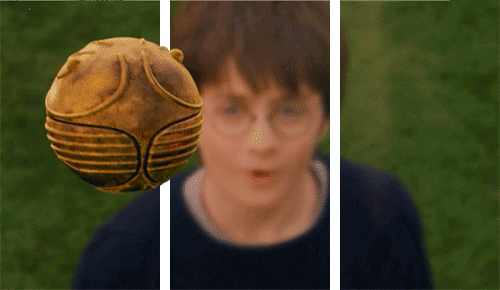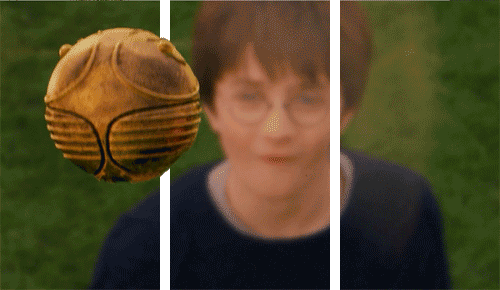
As I mentioned earlier, we don’t fully understand our visual processing—we only recently found out that our eyes reset orientation when we blink. (Our eyes rotate a little if watching a rotating object, and blinking resets this).
We have such complex eyes that use a huge amount of our resources—which is likely why vision is so beneficial to us. Without sight, we wouldn’t exist as we do in the world, and without light, we couldn’t have sight (as we know it).
Light
All light is electromagnetic radiation, made up of photons that behave like particles and waves.
Light Sources
The wavelength of ‘visible light’ (what our eyes perceive and therefore what we see) is around 400 to 700 nanometers. That’s also the wavelength range of sunlight, thankfully. Of course, we have evolved to see sunlight, so this isn’t just a coincidence.
We see a combination of waves of different wavelengths, and in the modern age (now that we have light bulbs and not just the sun), these are quite diverse.
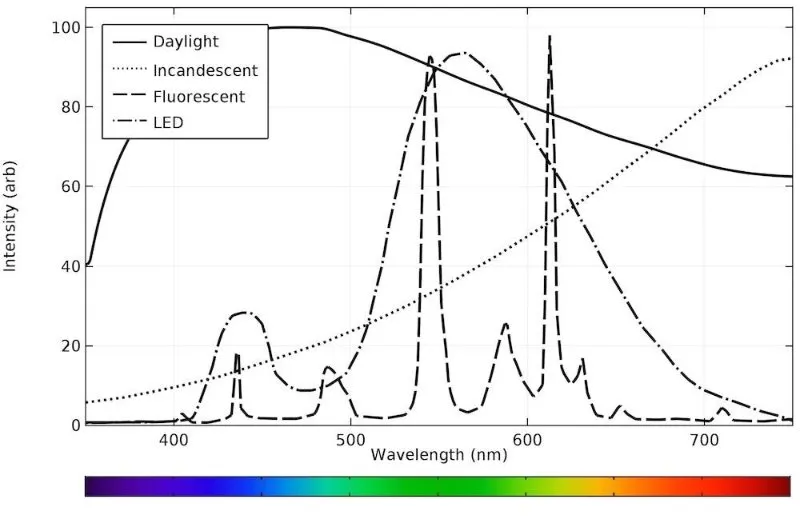
As you can see, sunlight contains all wavelengths, whereas bulbs have high amounts of more particular wavelengths.
We see objects as colors that are based on which wavelengths are reflected off them. A red bottle absorbs most wavelengths but reflects red, hence we see it as red.
The color of an object therefore depends on the light source. An object cannot reflect wavelengths that didn’t hit it in the first place, so its color will appear different in sunlight. Our brains judge the light source and compensate for this—which is part of what made this dress so famous!

Dive into that page (linked in the image source) and check out the scientific explanation discussing chromatic adaptation.
Color differences are particularly strange when objects are under fluorescent light, given that it appears to us as white light. Sunlight appears white and contains all wavelengths, whereas fluorescent light appears white but is missing many wavelengths, which therefore cannot be reflected.
Color Perception (Rods and Cones)
The photoreceptors in our eyes have different response curves, and cones have much more complex response curves (hence why rods don’t perceive color well).
There are three types of cones: short, medium, and long, which correspond to short (blue), medium (green), and long (red) wavelengths.
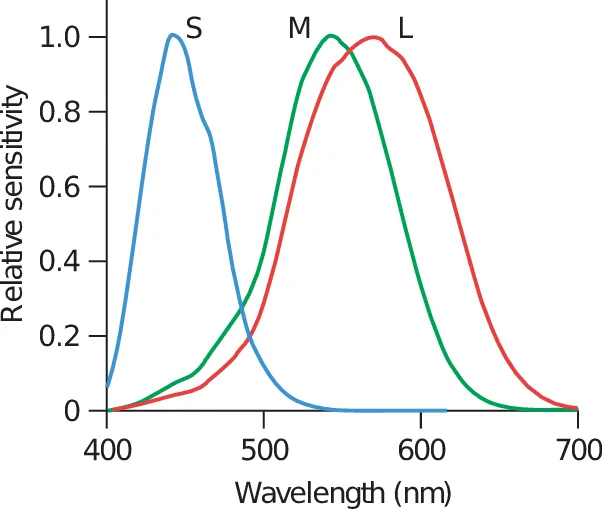
Long cones respond mainly to wavelengths very close to green but extend to red. This is why we can see more shades of green than any other color. We evolved this ability to spot hunting targets and dangers in forests and grasslands.
Our perception of color comes from these cones. Each cone has an output that is roughly calculated by multiplying the input wave by the response curve and integrating to get the area under the resulting curve. The color we see is then the relative activation of these three types of cones.

We have many more red and green cones then blue (another reason why we see a lot more shades of green than any other color), and this is why green also appears brighter than other colors.
You can also see from the image above that there are very few blue cones in the fovea (center of the image).
This is important to bear in mind when designing user interfaces, as this can sometimes make a significant difference. Reading green text on a black background, for example, is much easier than blue.

Most humans have these three cones, but there’s a lot of variation in nature. Some animals have more and can therefore perceive even more colors than we can!

Every additional cone allows the eye to perceive 100 times as many colors as before.
As mentioned, rods don’t really contribute to our perception of color. They are fully saturated during the day, so don’t contribute to our day vision at all. This doesn’t mean they’re useless by any means—they just serve very different purposes.
Color blindness is generally a missing type of cone or a variant in cone wavelength sensitivity. For example, if the red and green cones are even more similar than usual, it becomes very difficult for the person to distinguish between red and green (a very common form of color blindness).
Recreating Color on a Screen
If printers and TVs had to duplicate the reflecting wavelengths of a color accurately, they would be extremely hard to make! They instead find metamers that are easier to produce.
Finding easy-to-produce metamers allows us to recreate colors by selectively stimulating cones.
To show that metamers could be created, a group of subjects were gathered and given primary light controls. These controls consisted of three dials that modified the amount of red, green, and blue light (RGB), and the subjects were given a target color.
The task was to see if the subjects could faithfully reconstruct the target color by only controlling three primary colors. This was easy for many colors, but a touch more complicated for others, as negative red light had to be added to recreate some colors.
It was concluded that, given three primary light controls, people can match any color, and additionally, people choose similar distributions to match the target color. This means that light can be easily reproduced using combinations of individual wavelengths.
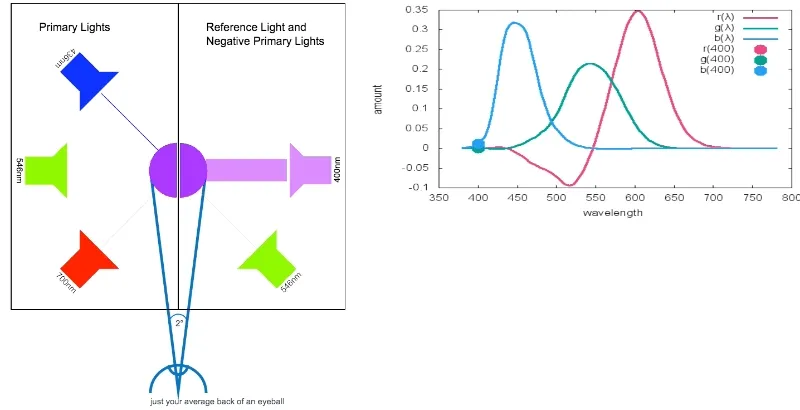
Using this information, a color map of all humanly visible colors was made. To represent colors on a screen however, your images need to be represented by a color space (of which there are many).
The most commonly used is sRGB, developed by Microsoft in 1996. But wider color spaces have been developed since then.
Adobe RGB was developed two years later and is used in tools such as Photoshop. ProPhoto RGB was created by Kodak and is the largest current color space, extending even beyond what our eyes can see.
So why don’t we all use this?
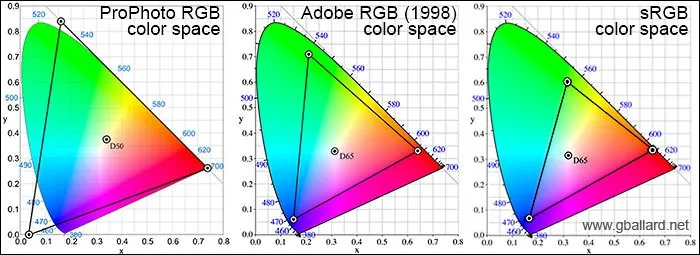
If you want to store an image as a jpeg, view your image in a browser, or print an image on a non-specialist printer, you’ll have to use sRGB.
ProPhoto RGB is simply too specialized for day-to-day use, so standard equipment and workflow tools don’t support it.
Even Adobe RGB images in a browser will often be converted to sRGB first, which is why sRGB is still the most used today.
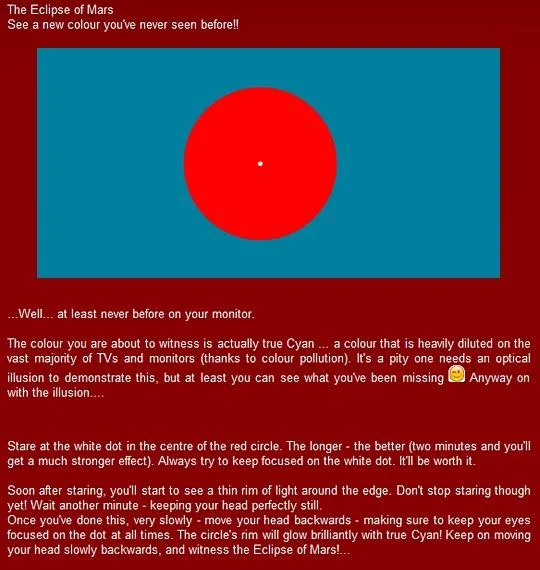
Printers use more primaries, but even so, some colors cannot be reproduced Unless in an illusion:
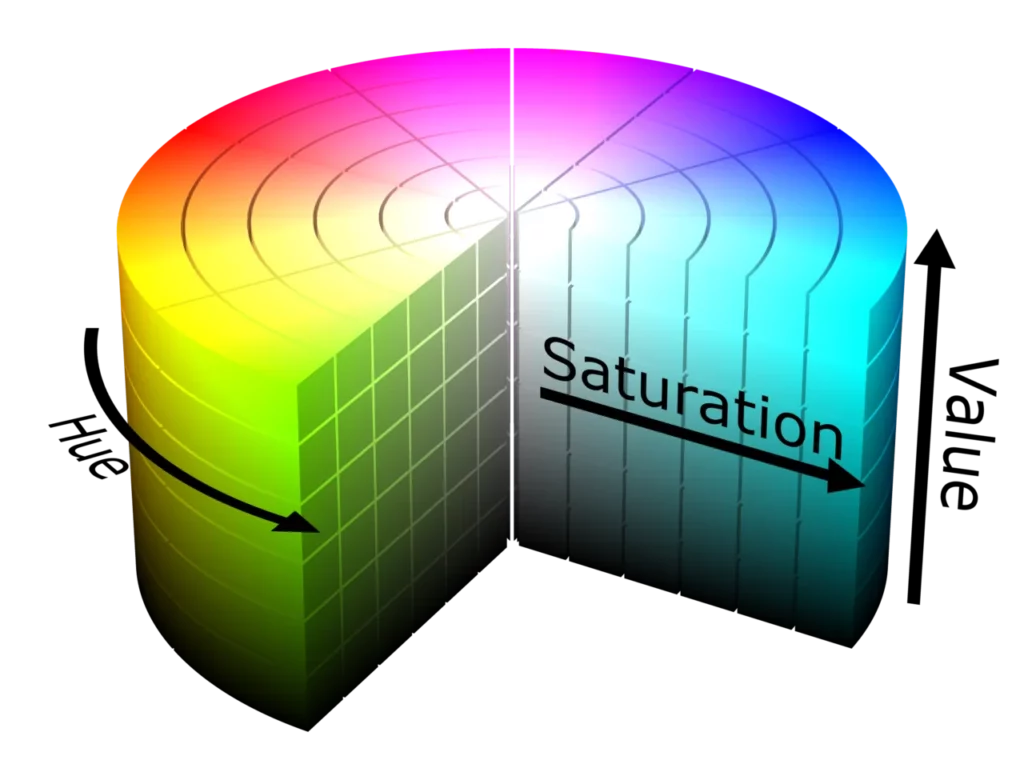
Finally, people have mapped color spaces into cubes:

and (more human-like as hue, value, saturation) cylinders:
Conclusion
Hopefully you’re convinced that sight is incredible and computer vision is no straightforward challenge!
In the next post in this series, I’ll cover Joseph’s lecture on basic image manipulation.
Comments 0 Responses