
In 2015, Google established its first TPU center to power products like Google Calls, Translation, Photos, and Gmail. To make this technology accessible to all data scientists and developers, they soon after released the Cloud TPU, meant to provide an easy-to-use, scalable, and powerful cloud-based processing unit to run cutting-edge models on the cloud.
According to Google’s team behind Colab’s free TPU:
But before we jump into a comparison of TPUs vs CPUs and GPUs and an implementation, let’s define the TPU a bit more specifically.
What is TPU?
TPU stands for Tensor Processing Unit. It consists of four independent chips. Each chip consists of two calculation cores, called Tensor Cores, which include scalar, vector and matrix units (MXUs).

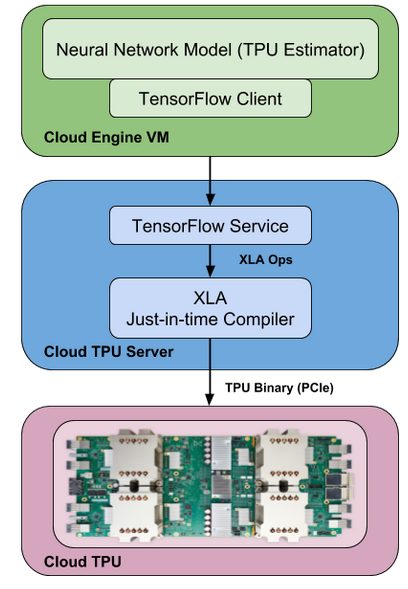
In addition, each Tensor Core, with 8 GB chip memory (HBM), has been unified. Each of the 8 cores on the TPU can execute user accounts (XLA ops) independently. High-bandwidth interconnection paths allow the chips to communicate directly with each other.
XLA is an experimental JIT (Just in Time) compiler for TensorFlow backend. The most important difference and feature from CPUs (Central Processing Units) and GPUs (Graphical Processing Units) is that the TPU’s hardware is specifically designed for linear algebra, which is the building block of deep learning. This is sometimes called a matrix or tensor machine.
Now that you have a bit better idea of what the TPU actually is, let’s take a look at how it compares to other common processing units.
Comparing CPU, GPU, and TPU: When should each be used?
🔮 CPU:
- Rapid prototyping requiring maximum flexibility
- Simple models that don’t take long to train
- Small models with small effective cluster sizes
- Models dominated by special TensorFlow operations written in C ++
- Available models with limited input/output or network bandwidth of the host system
🔮 GPU:
- TensorFlow models with an external tool that require high processing power
- Models that are too resource-free or too difficult to change
- Models with a significant number of special TensorFlow operations that must be run at least partially in CPUs
- TensorFlow ops models not available in Cloud TPU (see list of available TensorFlow ops)
- It’s used in larger models with larger effective cluster sizes.
🔮 TPU:
- Models with dense matrix calculations
- Models without special TensorFlow operations in the main training cycle
- Models lasting weeks or months to train
- Very large models with very large effective cluster sizes

Google Colab TPU Free Service 🚀
Using Google’s Colab TPU is fairly easy. Using Keras, let’s try several different and classic examples. And then we can evaluate the results!
Using the TensorFlow + Keras library to assess Google Colab TPU performance, we can consider two well-known datasets and basic deep learning methods:
🔵 Convolutional Neural Network (CNN) trained on the MNIST dataset
🔵 Visualization and Deploying a TPU-trained CNN (MNIST) with ML Engine
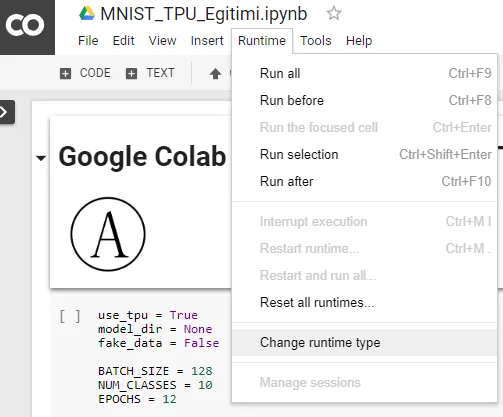
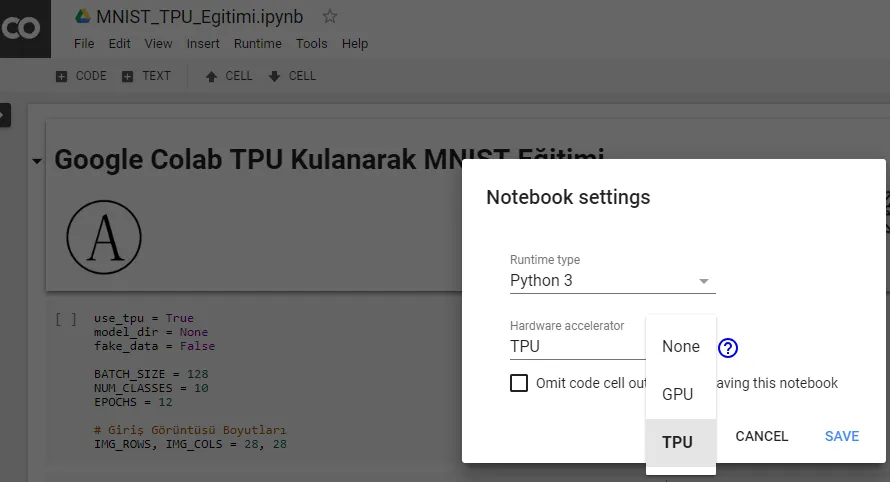
You’ll need to make the TPU selection on Google Colab first by using the Runtime tab. Clicking on the Change runtime type will allow you to select the TPU via the Hardware accelerator drop-down menu.
Basic TensorFlow Functions Required To Use TPU
First, you’ll need to create a TPU model using Keras:
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(
tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)TPU Estimator:
Estimators should be added at TensorFlow’s model level. Standard estimators can run models on CPUs and GPUs. But you need to use tf.contrib.tpu.TPUEstimator to train a model using the TPU.
my_tpu_estimator = tf.contrib.tpu.TPUEstimator(
model_fn=my_model_fn,
config=tf.contrib.tpu.RunConfig()
use_tpu=False)TPU Operation Configurations:
my_tpu_run_config = tf.contrib.tpu.RunConfig(
master=master,
evaluation_master=master,
model_dir=FLAGS.model_dir,
session_config=tf.ConfigProto(
allow_soft_placement=True, log_device_placement=True),
tpu_config=tf.contrib.tpu.TPUConfig(FLAGS.iterations,
FLAGS.num_shards),
)TPU Optimization:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
if FLAGS.use_tpu:
optimizer = tf.contrib.tpu.CrossShardOptimizer(optimizer)🔵 Convolutional Neural Network: CNN Trained on MNIST Dataset
When learning the basics of deep learning, it’s a good idea to compare training times on a well-known dataset (MNIST, in this case) with a simple CNN model—a relatively common introductory project for beginners—with Google Colab’s GPU and TPU.
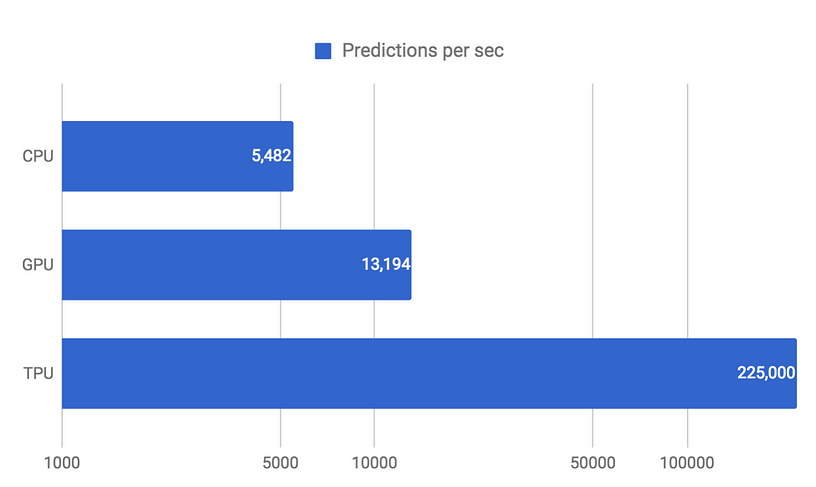
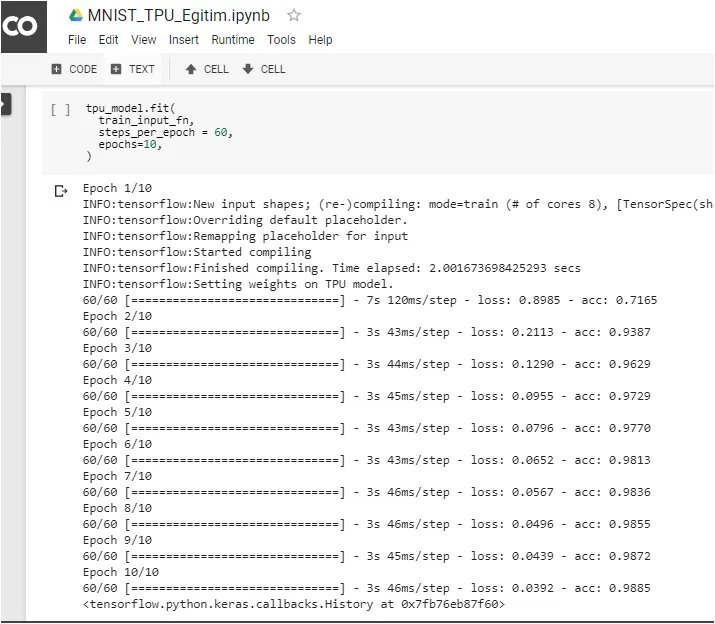
🏆 At the end of this example, you can see that every epoch takes only 3 seconds using the TPU, as compared to Google Colab’s GPU (Tesla K80), where every epoch takes 11 seconds. Turns out, our model trains roughly 4 times faster.
After the necessary library installation is completed, you’ll need to perform the following TPU addressing process:
try:
device_name = os.environ['COLAB_TPU_ADDR']
TPU_ADDRESS = 'grpc://' + device_name
print('Found TPU at: {}'.format(TPU_ADDRESS))
except KeyError:
print('TPU not found')When the process finishes smoothly, you should see:
We complete loading the MNIST dataset, separating data into training and testing, setting parameters, creating a deep learning model, and optimization methods.
Then it’s necessary to use tf.contrib.tpu.keras_to_tpu_model to make the model suitable for TPU usage during training.
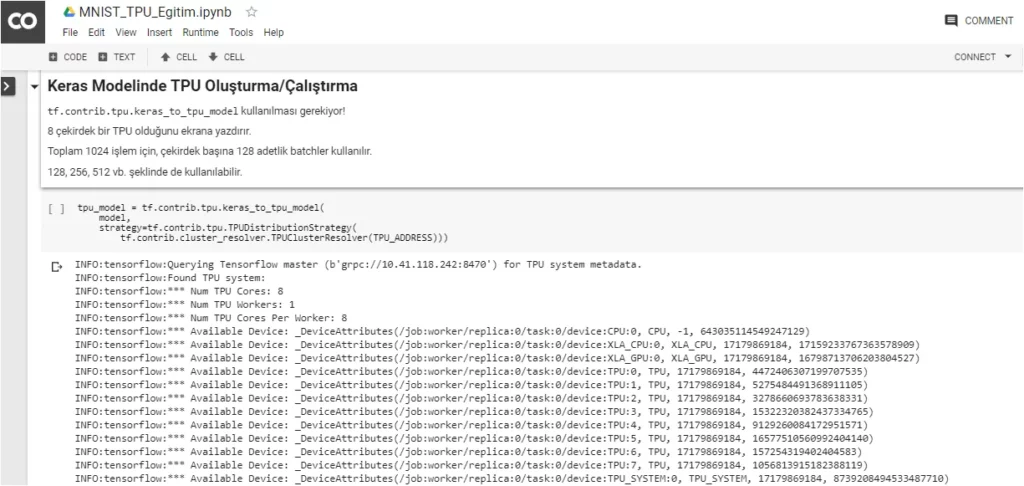
To view the structure of the model that will run on Google Colab’s TPU:
When we start the training process:
To save the trained model weights:
🔵Visualization and Deploying a TPU-trained CNN (MNIST) with ML Engine
Here we can see that the accuracy and loss for training and validation sets achieve good results in a very short time. Also, 168 sample validation digits out of 10000 resulted in bad predictions and are shown in red and sorted first in the second image below.
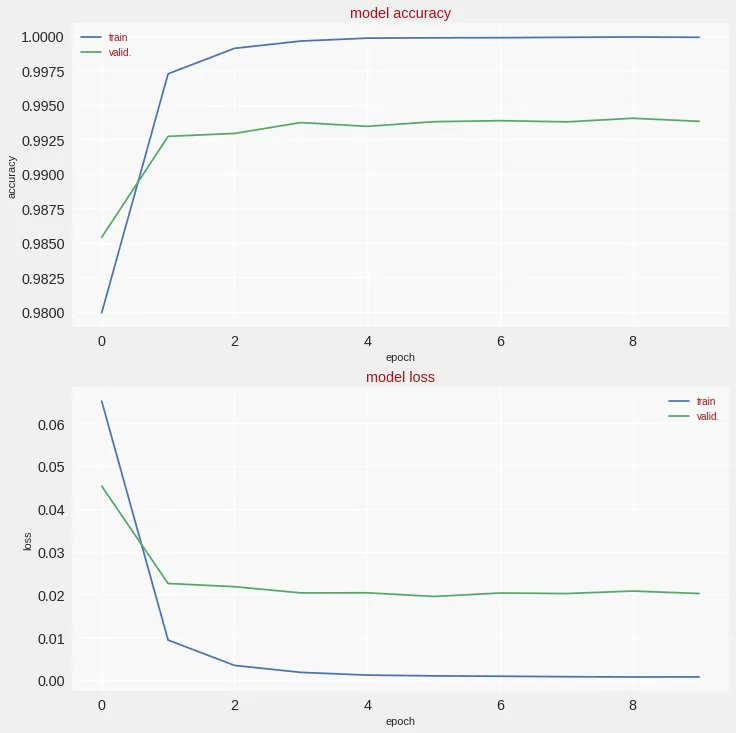

We’ve covered a very quick implementation of what we can do with the TPU in Google Colab. In the next step, we can try to train larger models with larger datasets to fully utilize the power of the TPU.
🌊 Source Codes
There are other common models and implementations with Colab notebooks that you can use with the TPU.
They include:
🔵Convolutional Neural Network (CNN) trained on the Fashion MNIST dataset
🔸 If a similar speed comparison is performed for Fashion MNIST, the situation will not be very different!
Each epoch takes approximately 7 seconds, and the result is only 102 seconds on for training 15 epochs with the TPU.
With the GPU it takes 196 seconds, and for the CPU, 11,164 seconds (~ 3 hours). This shows that the TPU is about 2 times faster than the GPU and 110 times faster than the CPU.
🔵Long-Short Term Memory (LSTM) network trained on the Shakespeare dataset
🔵 Visualization and Deploying a TPU-trained CNN (MNIST) with ML Engine
🐰 Full GitHub Repo for This Project:
Thanks to Martin Görner for letting us publish the work in Turkish! (Translation team: Başak Buluz, Yavuz Kömeçoğlu and I)
If you’d like to train ANNs using Google Colab’s TPU, here’s another extremely useful resource:

🎉 Thanks and References
I would like to thank Yavuz Kömeçoğlu for his contributions. 🙏
Comments 0 Responses