
In this post, we’re going to investigate the field of sign language recognition and its applications in the real world.
We are going to discuss the approaches adopted by a research paper on Indian Sign Language Recognition and try to understand the merits and demerits of these methods from a practical point of view.
So, let’s jump right in!
Kindly refer to the link given below for the complete research paper. The models in this post will be based on the approach used in this paper. I am thrilled to let my readers know that the research paper here discussed was written by me and my teammates and has been published in the International Journal of Neural Computing and Applications.😁
Note: Though the research paper focuses on Indian Sign Language recognition, it uses a generic approach that can be applied to other sign languages as well.
What is Sign Language Recognition?
Sign language is the mode of communication which uses visual ways like expressions, hand gestures, and body movements to convey meaning. Sign language is extremely helpful for people who face difficulty with hearing or speaking. Sign language recognition refers to the conversion of these gestures into words or alphabets of existing formally spoken languages. Thus, conversion of sign language into words by an algorithm or a model can help bridge the gap between people with hearing or speaking impairment and the rest of the world.
How is Indian Sign Language different?
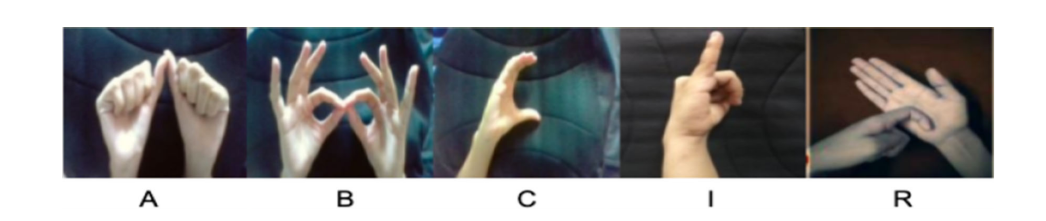
Indian Sign Language (ISL), unlike other sign languages, is a two hand gesture sign language, though some of the letters of the alphabet (c,i,j,l,o,u,v) only require one hand representation.
Issue with Indian Sign Language Recognition
The problem with ISL recognition is that, due to the involvement of both hands, there is feature occlusion and computer vision techniques like convex hull fail to capture the gesture effectively.
For example, let us imagine an algorithm that detects the location of the centre of palm and fingers to detect a gesture. Now, in the case of a gesture involving two hands, the algorithm would get confused since there would be two palms and 10 fingers and thus, result in a wrong prediction.
Techniques for Sign Language Recognition
Various techniques have been explored for the purpose of efficient sign language recognition over time. Some of the most effective ones are discussed below:
Hardware based recognition techniques
Some sign language recognition techniques consist of two steps: detection of hand gesture in the image and classification into a respective alphabet. Several techniques involve hand tracking devices (Leap Motion and Intel Real Sense) and use machine learning algorithms like SVM (Support Vector Machines) to classify the gestures. Hardware devices like kinetic sensors (by Microsoft) develops a 3D model of the hand and observes the hand movements and their orientations. A glove-based approach was another technique wherein the user was required to wear a special glove that recognized the position and orientation of the hand. Hardware techniques can be fairly accurate, but cannot be vastly used due to the initial setup cost.

Machine learning based recognition techniques
A few earlier techniques used computer vision techniques like the convex hull method used to determine the convexities in the image and detect the edge of the hand in the image. There are also contour based techniques which look for skin-like contours in the image to detect a hand. The detection is later followed by machine learning algorithms trained for the task of classifying these gestures into alphabets.
The technique used in the research paper being discussed in this post focuses on Neural Network based recognition.
Dataset
The dataset was created manually due to the lack of availability of a complete dataset for ISL which included all the 26 letters of the Roman/Latin alphabet. The dataset includes almost 10,000 images for each letter in different backgrounds and lighting conditions.
Data Augmentation
The images for each letter were augmented to enhance the size and efficiency of the dataset. The images were zoomed in and out, brightened, darkened, rotated, and shifted so as to provide a set of images for each letter which were diverse with respect to the background, orientation, and lighting conditions.

Approaches for Indian Sign Language Recognition
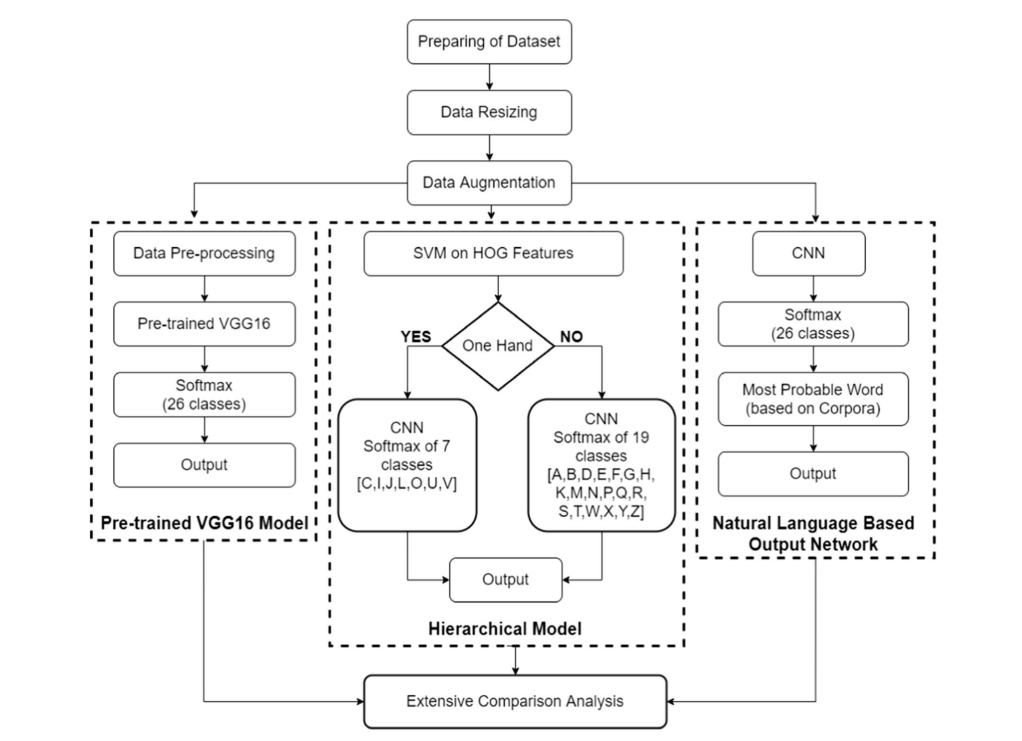
Three approaches were developed for the problem statement at hand and a comparative analysis was performed on these models based on their training statistics and results.
Pre-trained and Fine-tuned models
A pre-trained VGG16 model was employed for training on the dataset of ISL alphabets. The training was done using transfer learning and fine-tuning techniques, thereby establishing a baseline for comparing the models. The last layer (the softmax layer) of the initial VGG16 model was removed since it was designed as per the Imagenet dataset. Two fully-connected layers were then appended followed by a new softmax layer having 26 classes, one for each letter of the alphabet.
Natural Language based model
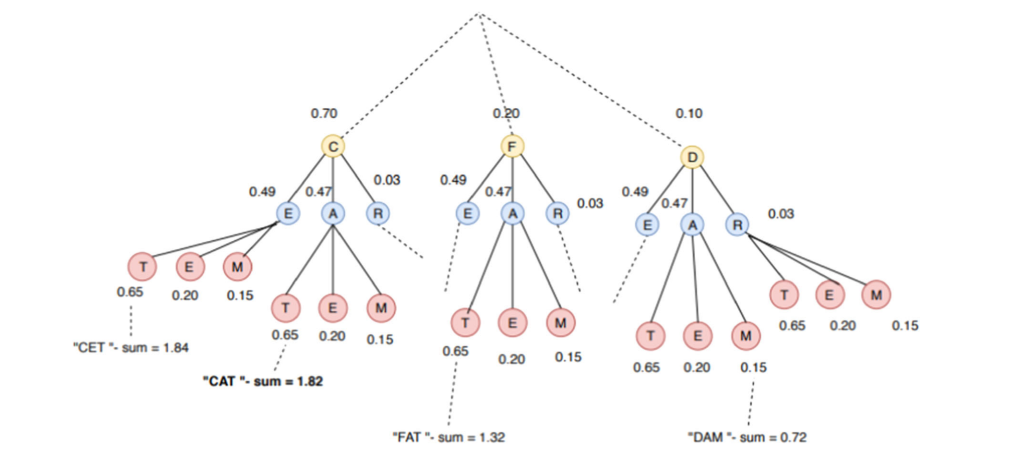
As a part of this model, a Deep Convolutional Neural Network (DCNN) with 26 classes was developed. Later, the output was fed to an English Corpora-based model for eradicating any errors during classification due to noise or model error. This process was based on the probability of the occurrence of the particular word in the English vocabulary. For example: if a person makes a gesture for “C-A-T” and it gets classified as “C-X-T”, then the model can convert this X into A based on the fact that CAT is a much more frequent word and there isnt’ any word like CXT. Only the top three accuracy scores provided by the neural network were considered in this model.
Hierarchical Neural Network Model
To eradicate the feature occlusion issue due to the presence of both one-handed and two-handed gestures, a segmented approach was adopted. An SVM model was used to classify the images into two categories: images having one hand or two hands, thus performing binary classification. After that, these images were fed into their respective neural networks designed for one and two hand features separately.
Model Architecture
- Extracting HOG Feature matrix: Binary classification is performed by an SVM model to classify into images that contain one-handed or two-handed gestures. Before feeding the images into the SVM, we applied Histogram of Oriented Gradients (HOG) on these images which gave us a feature representation of these images. HOG is a feature descriptor and extractor which works on gradient-based edge detection and can be very helpful to detect hand features in noisy and dark backgrounds. The gradients along x and y directions of an image can be very important around edges and corners and helps us to identify sudden intensity changes. To learn about HOG in depth, please refer to this article.
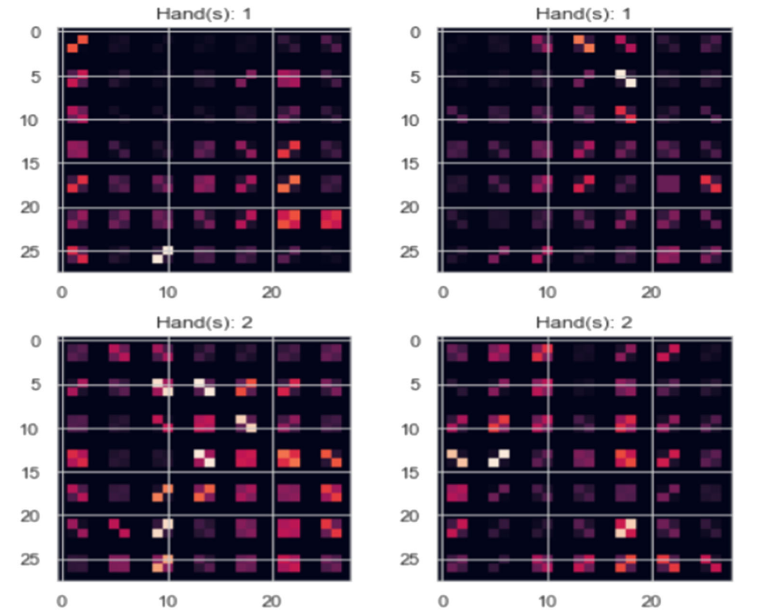
HOG feature representation of images
2. Data Pre-Processing for SVM: After extracting the HOG features, we got a 24339*2028 matrix which is quite huge to be fed to SVM. Thus, standardization and scaling was performed and then Principal Component Analysis (PCA) was done to get the most information out of this huge matrix and compact it into 1500 features for each image. To learn more about PCA, please refer to this article.
3. SVM for Binary Classification: The principal component features were finally fed into the SVM model with a linear kernel. The output of the SVM depicted two classes, ‘0’ for one-hand and ‘1’ for two-hand gestures. To learn more about SVM, kindly go through this article. The model produced an accuracy of 96.79%
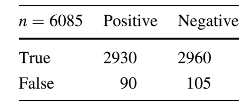
Confusion matrix for SVM
4. Neural Network for one hand features: If the output of the SVM turns out to be “0,” it means it is a one hand feature and is thus fed to a convolutional neural network based on VGG19 architecture. At last, two fully connected layers with 128 nodes each were appended followed by a softmax having 7 classes, one for each one-handed gesture (C,I,J,L,O,U,V).
5. Neural Network for two hand features: If the output of the SVM turns out to be “1,” it means it is a two hand feature and is thus again fed to a different convolutional neural network based on VGG19 architecture. At the end of the VGG19 architecture, two fully connected layers with 256 nodes each were appended which were followed by a softmax layer of 19 classes, one for each two-handed gesture (A,B,D,E,F,G,H,K,M,N,P,Q,R,S,T,W,X,Y,Z).
Training Parameters
The Hierarchical Model was trained on 150,000 images, approximately. The SVM model was trained on PCA features extracted from 6085 images. For each of the neural networks following the SVM, Adam optimizer was used with a learning rate of 0.0001 in the case of one hand, and 0.0005 in case of two hand gestures.
Results
The results of all the three models are summarized in the next subsection. However, we are interested in the Hierarchical Network approach, which has proven to be a significant improvement over the existing architectures for Indian Sign Language recognition. The hierarchical model provided a training loss of 0.0016, thus translating to a training accuracy of 99% and a validation accuracy of 98.52% for categorizing one-handed features. For two-handed features, the training and validation accuracies were 99 and 97%, respectively.


Comparative Analysis
Here is a tabular comparison between the three models discussed in the research paper.
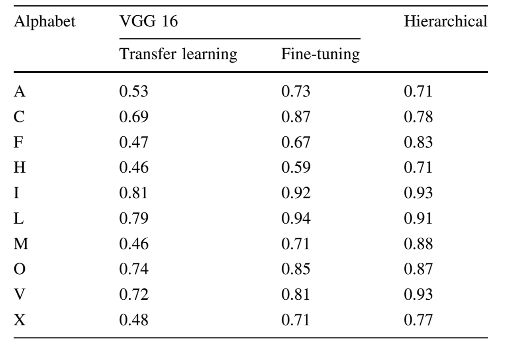
Accuracies for a few alphabets with different approaches

Comparative analysis for the three approaches
Conclusion
In this post, we discussed Sign Language Recognition techniques and focused on a Hierarchical Neural Network based approach. Sign language recognition can help bridge the gap between people with hearing or speech impairment or who use sign language, and the rest of society who haven’t learned sign language. This leads to enhanced communication for all.
All feedback is welcome and appreciated — I’d love to hear what you think of this article!
Comments 0 Responses