
Neural Network (NN) Pruning is a task of reducing the size of a Neural Network by removing some of its parameters/weights.
Pruning is often performed with the objective of reducing the memory, computational, and energy bandwidths required for training and deploying NN models which are notorious for their large model size, computational expense, and energy consumption.
Particularly when deploying NN models on mobiles or edge devices, Pruning, and model compression in general, is desirable and often the only plausible way to deploy as the memory, energy, and computational bandwidths are very limited.
But, one can ask, why not use potentially infinite virtual memory and computational power from the cloud? While a lot of NN models are running on the cloud even now, latency is not low enough for mobile/edge devices which hinders utility and requires data to be transferred to the cloud, which raises several privacy concerns.
The year 2020 has been a great year for NN Pruning research and this article discusses six new approaches/insights published at premier peer-reviewed conferences ICLR, ICML, and NeurIPS in 2020.
Preliminaries of NN Pruning research
The workflow of a typical Pruning method: A set of parameters of a trained model are zeroed out according to a pre-defined score (usually absolute magnitude) and the network remained is trained again (retraining), thus approximating the accuracy of the original model with this sparse, pruned model requiring drastically lower, when compared to the original model, memory, computational and energy bandwidths because of the fewer parameters.
To understand the advances in Pruning research it helps to place new techniques as different types across different dimensions (ways to classify) and their unique strengths and weaknesses. The following are a few standard dimensions Pruning methods could be classified into:
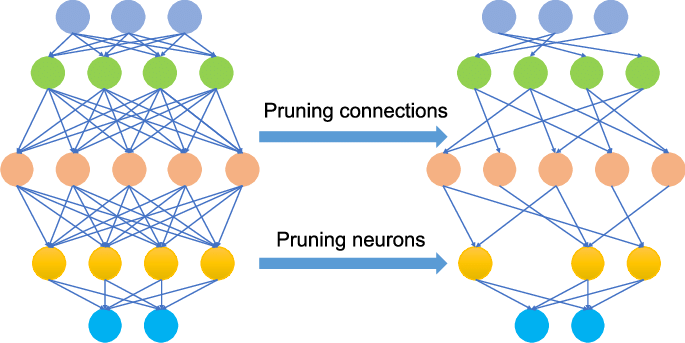
- Structured vs. Unstructured Pruning
If NN weights are pruned individually in the pruning process, then it is called Unstructured Pruning.
Zeroing out the parameters randomly gives memory efficiency (model stored in sparse matrices) but may not always give a better computational performance, as we end up doing the same number of matrix multiplications as before. Because matrix dimensions didn’t change, they are just sparse. Although we could get computational advantages by replacing dense matrix multiplications with sparse matrix multiplications, it is not trivial to accelerate sparse operations on traditional GPUs/TPUs.
Alternately, in Structured Pruning, the parameters are removed in a structured way to reduce the overall computation required. For example, some of the channels of CNN or neurons in a feedforward layer are removed, which directly reduces the computation.
2. Scoring of parameters
Pruning methods may differ in the method used to score each parameter which is used to choose one parameter over another. The absolute magnitude scoring method is the standard but one could come up with a new scoring method that would increase the efficiency of Pruning.
3. One-shot Vs Iterative
While performing Pruning, Rather than pruning the desired amount at once, which is called One-shot Pruning, some approaches repeat the process of pruning the network to some extent and retraining it until the desired pruning rate is reached, which is called Iterative Pruning.
4. Scheduling of pruning and fine-tuning
In the paradigm of Iterative Pruning, previous work showed that learning or designing when to prune and how much helps. A Schedule of pruning specifies the ratio of pruning after each epoch along with the number of epochs to retrain the model whenever the model is pruned.
Neuron-level Structured Pruning using Polarization Regularizer (NeurIPS 2020)
Outstanding problem: In one of the variants of Structured Pruning, to remove entire filters in CNN or all weights associated with a particular neuron, a learnable scaling factor is used for each filter/neuron which is multiplied by the weights of that filter/neuron in the forward pass.
And to prune the model, all the filters/neurons with scaling factor less than a threshold are removed, thus accomplishing the Structured Pruning.
While training, an L1 regularizer is added to the main training loss to push all the scaling factors to zero with the aim of having scaling factors above the threshold only for filters/neurons that are absolutely necessary.
This work shows that the L1 regularizer is not efficient in contrasting between useful and not useful filters/neurons and tries to address this inefficiency.
Proposed solution: L1 regularizer tries to push all scaling factor values to zero which is not consistent with the intuition that only some of the filters are not useful while others are useful. It is hard to pick a threshold value that would clearly separate useful filters among other filters as seen in the left plot of the figure below.
This work proposes Polarization Regularizer, which pushes the scaling factors towards the extremes, either 0 or 1, which aligns better with the objective of removing some of the filters and while retaining others.
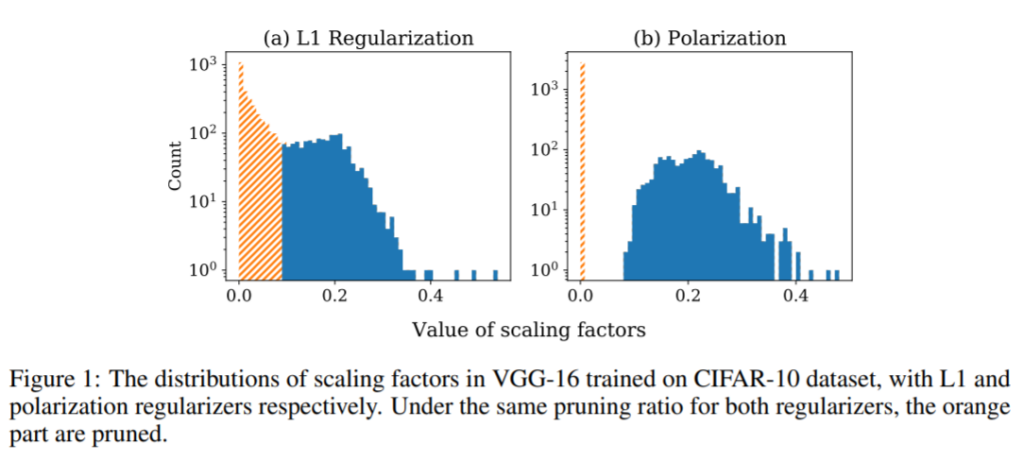
Specifically, this work adds a term to L1 regularizer which is maximum when all scaling factors are near to each other, pushing scaling factors towards two extremes.
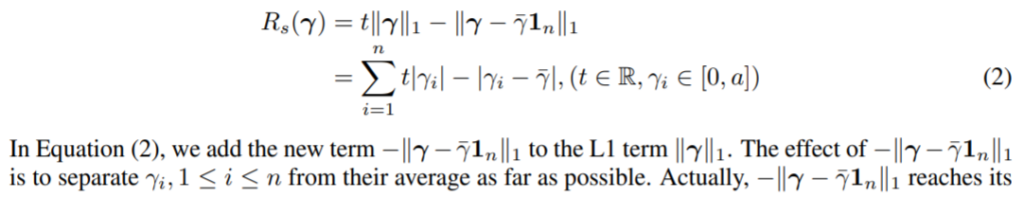
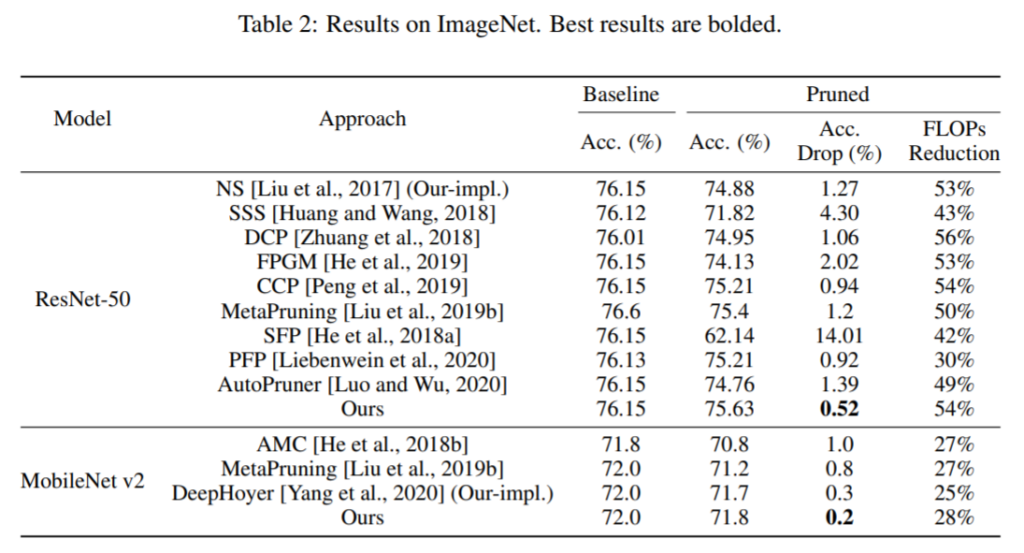
Results and conclusions: The proposed method is better than a lot of methods by reducing the FLOPs required by ResNet-50 by 54% with just a 0.52 drop in accuracy. The authors even show that they can prune already efficient MobileNet V2 by 28% with just a 0.2 reduction in accuracy.
It also allows for aggressive pruning, where structured pruning methods are not effective, without compromising on the accuracy compared to existing models.
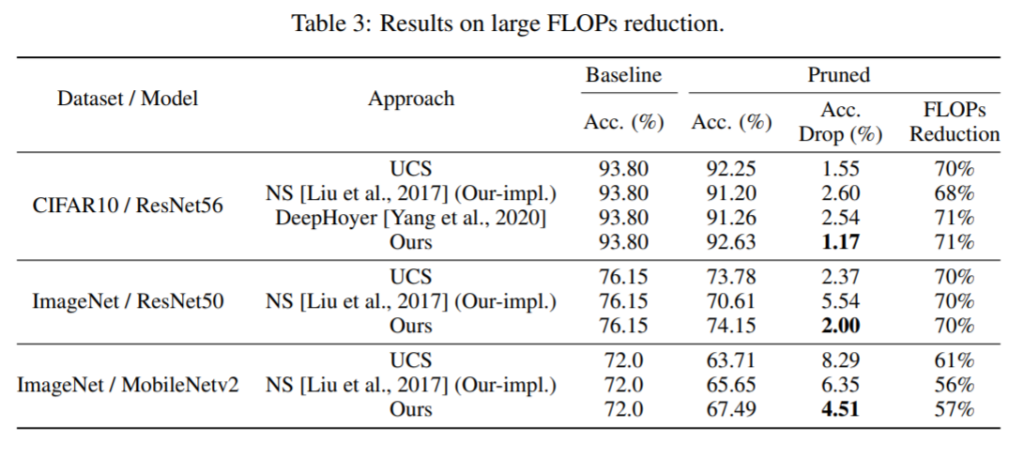
Comparing Rewinding and Fine-tuning in Neural Network Pruning (ICLR 2020)
Outstanding problem: After training and pruning, there is no evidence from the literature as to which form of retraining is most efficient: Rewinding or Fine-tuning.
Proposed solution: This work performs comprehensive empirical studies evaluating the efficiency of Rewinding and Fine-tuning and finds that Rewinding is more efficient.
After training and pruning, if the remaining network is retrained with the trained network, then it is called Fine-tuning. Note that while fine-tuning we will continue using the same learning rate schedule as though it is further training.
If the remaining network is retrained with the weights at initialization (by rewinding) rather than trained weights, it is called Rewinding. Note that while Rewinding, as the weights are actual initialization weights of the network before training, the learning rate schedule starts afresh like it is the start of the training, only now with the small pruned network.
Also, the authors propose a new retraining technique called Learning Rate Rewinding to replace standard weight rewinding and is shown to out-perform both Rewinding and Fine-tuning. Learning Rate Rewinding is a hybrid of Fine-tuning and rewinding, where trained weights are used to retrain as in Fine-tuning but the learning rate schedule is rewinded as in Rewinding.

Results and conclusion: It is shown that learning rate schedule and Rewinding is more efficient than Fine-tuning on CIFAR-10, ImageNet, and WMT16 datasets with standard architecture. This behavior is shown to be consistent whether it is structured or unstructured pruning, and whether it is one-shot or iterative pruning.
Pruning Filter in Filter (NeurIPS 2020)
Outstanding problem: Unstructured Pruning achieves more sparsity with minimal accuracy drop but achieving computational efficiency with this method is not straightforward, as sparse weights don’t necessarily reduce the number of matrix multiplications and sparse matrix multiplications are not usually accelerated by the standard GPUs/TPUs.
On the other hand, Structured Pruning, which is removing entire filters or channels, reduces computation but doesn’t afford enough sparsity compared to Unstructured Pruning methods.
Balancing the tradeoff between structure and sparsity is not fully exploited. This work shows the importance of this with an observation that only some parts of a particular filter are useful. The authors prove that taking away the entire filter is not efficient.
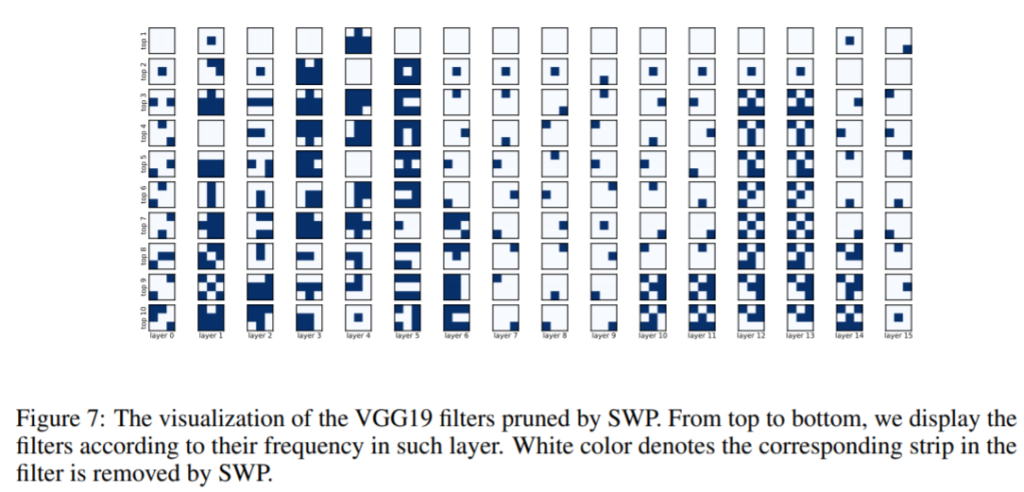
Proposed solution: This work proposes a method called Filter Skeleton which is a strip-wise pruning method that is more granular than Structured Pruning, but could be reduced into fewer matrix multiplications, thus giving more sparsity while retaining the computational advantages of Structured Pruning methods.
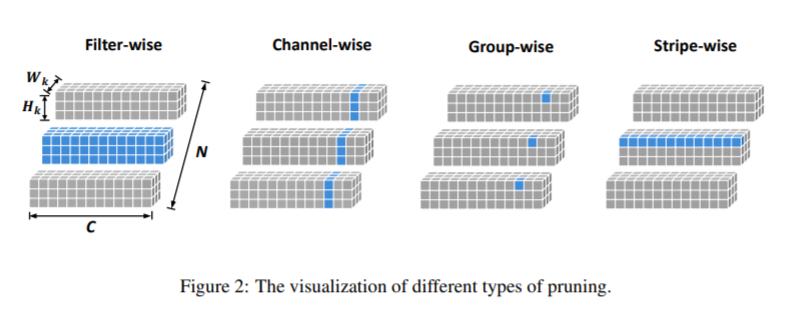
Results and conclusion: Stripe-wise pruning outperforms an existing method of Group-wise pruning which is also a Structured Pruning method with more granularity. See fig. below.
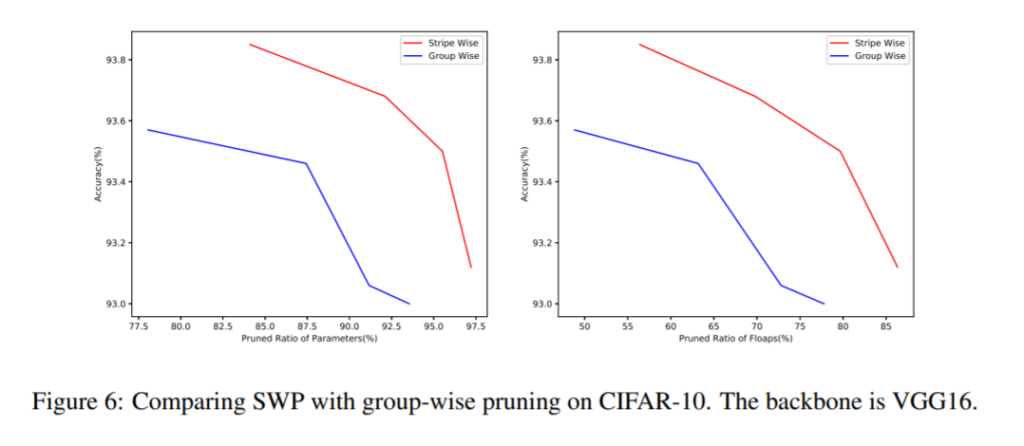
The method proposed reduces the required FLOPs of ResNet-18 on ImageNet dataset by 50.4% while increasing the accuracy by 0.23%.
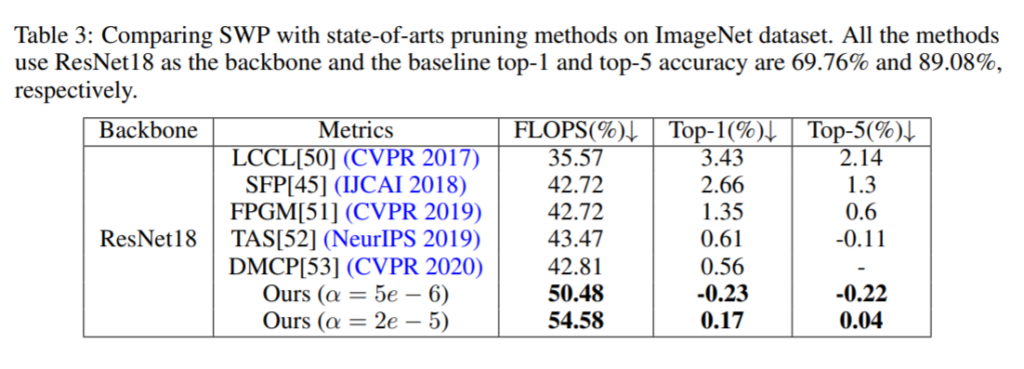
Pruning neural networks without any data by iteratively conserving synaptic flow (NeurIPS 2020)
Outstanding problem: Methods for Pruning at initialization without any training what-so-ever are not efficient.
This work identifies that the problem with current methods for Pruning at initialization is Layer-dropping, where a method prunes a particular layer completely, making the networks untrainable. This will occur when the sparsity we want to achieve is higher than the layer-drop threshold. In the figure below, layer-drop happens in all the methods except in the proposed method, Syn-Flow.
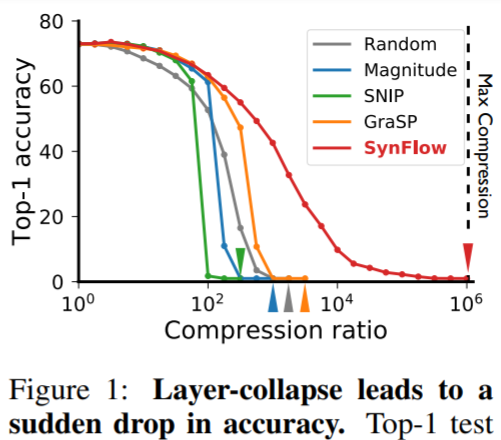
Proposed solution: This work theoretically understands that Iterative Magnitude Pruning avoids Layer-drop with iterative training and pruning by achieving a property which they call Maximal Critical Compression. With these insights, they propose a method that achieves Maximal Critical Compression without any data.
Results and conclusion: Syn-Flow consistently outperforms previous methods for Pruning at initialization in 12 combinations of datasets and models. See the figure below.
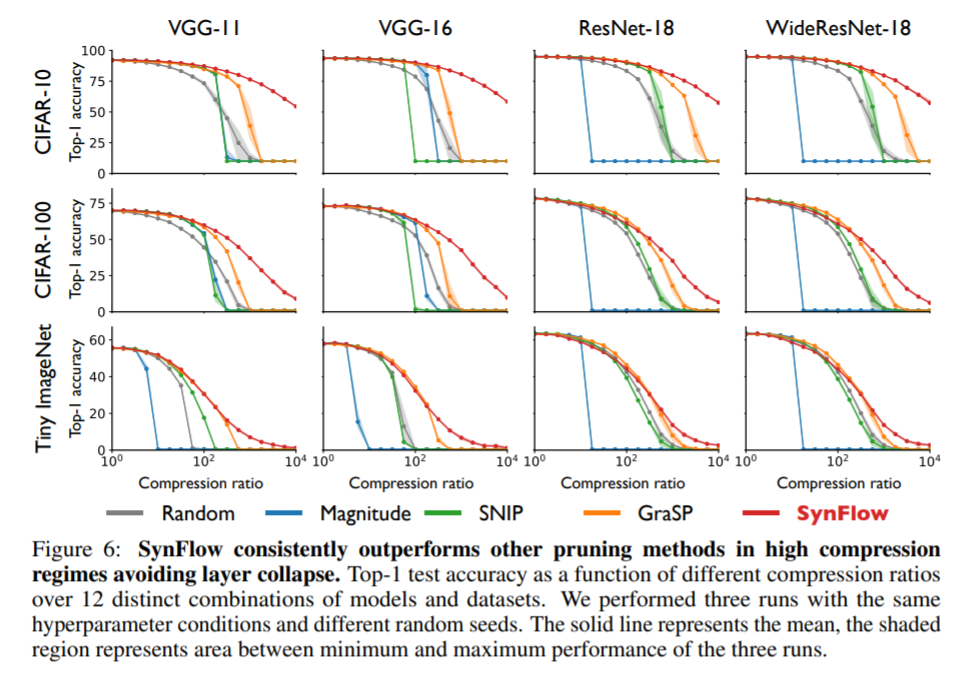
The Lottery Ticket Hypothesis for Pre-trained BERT Networks (NeurIPS 2020)
Outstanding problem: Lottery ticket hypothesis says that there is a sub-network within the original, complete network that could be trained to achieve the same performance as the entire network. These sub-networks are called Lottery tickets. These lottery tickets are represented by binary masks that tell which of the weights should be zeroed out.
Proposed solution: The authors used Iterative Magnitude Pruning (IMP) and tried to find lottery tickets from the pre-trained BERT model.
IMP trains a network, removes weights with lower magnitude, and then repeats this process until the required sparsity is achieved. It uses Rewinding where the weights of the pruned network are reverted back to their initialization weights, here pre-trained BERT weights.
The lottery ticket here is the subnetwork of the original pre-trained BERT model which shows similar performance. Note that the weights of the lottery ticket and the pre-trained BERT model are the same where the lottery ticket is not pruned because of the Rewinding in IMP.
Results and conclusion: This work shows that the lottery ticket hypothesis holds for pre-trained BERT models as well. It also found subnetworks at 40% to 90% sparsity for a range of downstream tasks.

In a work similar to this one, it is shown that lottery tickets exist for NLP and RL as well. See the paper Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP.
HYDRA: Pruning Adversarially Robust Neural Networks (NeurIPS 2020)
Outstanding problem: In resource-constrained and safety-critical environments, both robustness and compactness are required at the same time. It is shown that to increase the robustness of a Neural Network, we have to increase the size of the network. So, robustness with fewer parameters is very desirable.
This work conjectures and shows evidence that even low-magnitude weights are important for robustness. As most of the dedicated pruning techniques remove low-magnitude weights, this could hinder robustness accuracy. This shows that dealing with robustness and pruning at the same time leads to more efficient methods, of which the current method is a great example.
Proposed solution: This work proposed a pruning method, HYDRA, which decides which weights to remove while decreasing the desired loss, here the loss derives from the robustness training objective.
Finding an optimal pruning mask is formulated as importance-score-based optimization where score values for different weights could have a floating-point importance score between 0 and 1. After the optimization, weights with lower importance scores are removed.
Results and conclusion: The proposed pruning technique prunes the network while showing less degradation in robustness accuracy compared to the dedicated pruning technique LVM.
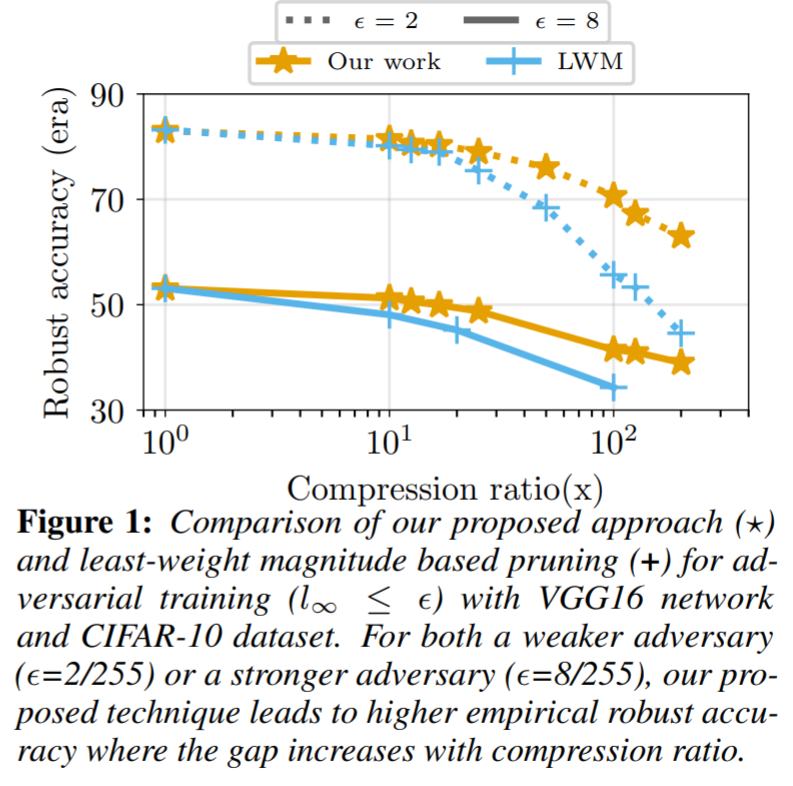
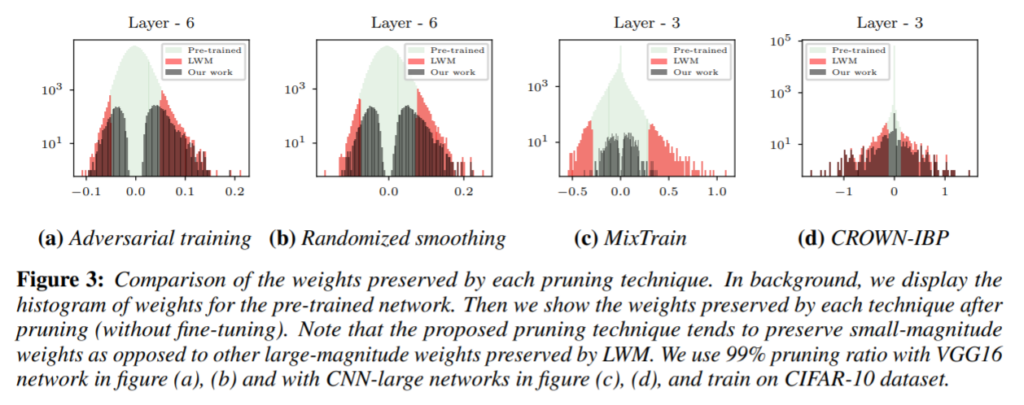
The authors also observe that the proposed method retains low-magnitude weights while retaining better robustness accuracy which shows the importance of low-magnitude weights towards robustness.
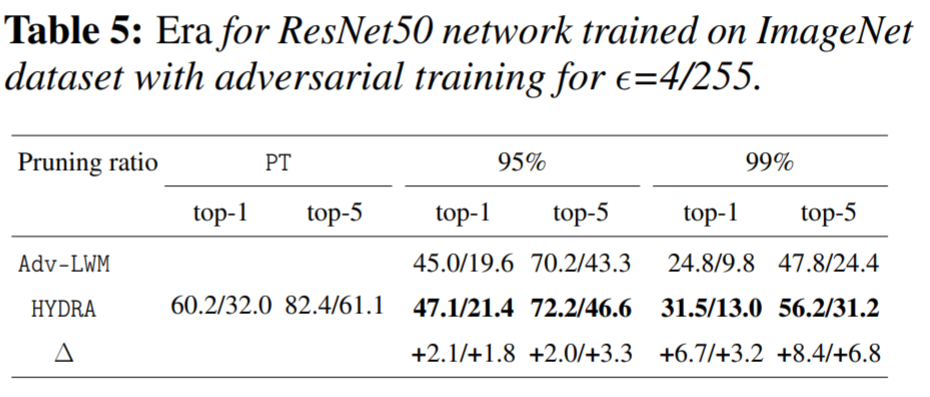
This method shows state-of-the-art performance with ResNet50 on ImageNet with adversarial training.
Conclusion and Future work
Neural Network Pruning research is evolving to be more scientific and rigorous. One of the reasons is, undoubtedly, the interaction between the wide adoption of deep learning methods in Computer Vision & NLP and elsewhere and the increasing amount of memory, energy, and computational resources required for the state-of-the-art methods.
Going into 2021, we know how to prune a network efficiently without any data, how to strike a balance between Structured and Unstructured Pruning methods while retaining the benefits of both worlds, how to find lottery tickets (pruned networks) in diverse domains and how to best retrain them, and how to prune a model even when adversarial robustness is needed.
And as with any field which is scientific and rigorous, Pruning research is poised to become more objective/authoritative (as opposed to having very little comparative analysis), with validation of new techniques over diverse datasets, architectures, and domains not just on, as seen in many cases, ImageNet dataset with a ResNet variant. This will inform us plenty about how to work with deep learning methods across different tasks even in low-resource environments.
Comments 0 Responses