
Machine learning models are often black boxes to end users. Without access to the underlying model architecture and parameters, they are nearly impossible to reconstruct with inputs and outputs alone.
Hosting a model in the cloud effectively prevents access to these underlying structures. Without breaching the hosting servers, an attacker has no access to the model: they can’t look at the layers, get the trained weights, or even see the framework it’s running on.
For many companies, this is a feature, not a bug. Models contain a treasure trove of intellectual property. Large amounts of training data are required to build any machine learning model. The value of those training datasets is embedded in the resulting ML model.
A company may spend large amounts of resources compiling a training set for a ML model, and it doesn’t want to just give that trained model away.
Whai is Core ML?
Apple’s machine learning framework for iOS, Core ML, creates new opportunities for product development. Application developers can use machine learning models to create great experiences for users without having to rely on laggy network requests.
They can build models on high-bandwidth data such as streaming video or audio that would be impractical to send to the cloud for inference. But when a Core ML model is running inside of an app, an attacker can potentially look inside the black box.
When a developer deploys a machine learning model to a mobile device, they lose control over how the model is accessed or used. In this post, we’ll look at how Core ML models are stored inside of apps and show how it’s possible to reconstruct the original model from compiled Core ML resources.
The original .mlmodel file
The .mlmodel file is a compact representation of a model that Apple uses for Core ML. There are many tools that can be used to generate an .mlmodel file. The coremltools Python package converts Keras and Caffe models.
There are also many other tools for converting different model formats to the Core ML format (such as TensorFlow, mxnet, etc.).
The Core ML model .mlmodel file contains the entire model specification. Our friend Matthijs Holleman, has a great blog post describing the .mlmodel file format here. I highly recommend checking it out.
Gaining access to the original .mlmodel file is enough to have access to the internals of the black box—IP that companies and developers wish to protect. But it turns out, during the app build phases, the original .mlmodel file is compiled and a different format is packed into the app bundle.
The compiled Core ML model
When a Core ML model is compiled it generates an output folder containing different files used by Core ML to actually run the model in an app.
Here is the output file structure:
- model.espresso.shape: Shape parameters for the model. It’s not immediately clear how this is used.
- model.espresso.net: Model layer parameters.This contains the model architecture used during inference.
- model.espresso.weights: Binary file containing the biases and weights for layers.
- Binary files that contain metadata such as output labels.
The model.espresso.net file gives us the most insight into how the model is constructed. Let’s take a look the output from compiling a Keras model with a convolution layer:
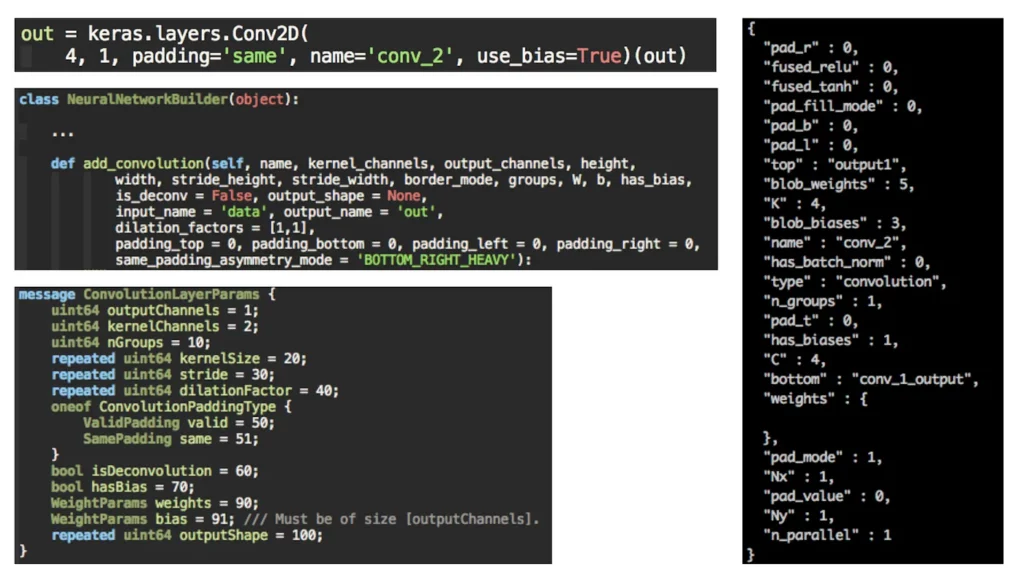
The picture above shows where a layer in the model.espresso.net file comes from. Taking a Keras layer as an input, coremltools creates a protobuf message with a standardized format for each layer type.
The Core ML compiler then compiles the protobuf message into the format used on device. If we can rebuild each protobuf layer from the .net file, then we can recreate the original model.
I won’t go into all of the details here, but with a little deductive reasoning it’s not too difficult to construct most of the input parameters. However, some important fields are missing: what about weights and bias?
The .net file gives us a clue as to where we can find those with the fields blob_weights and blob_biases. To better understand where we might find these values, let’s turn to the model.espresso.weights file.
model.espresso.weights
The weights file is a binary file that most likely contains all of the weights for the model. Using xxd I was able to figure out the structure of the file:
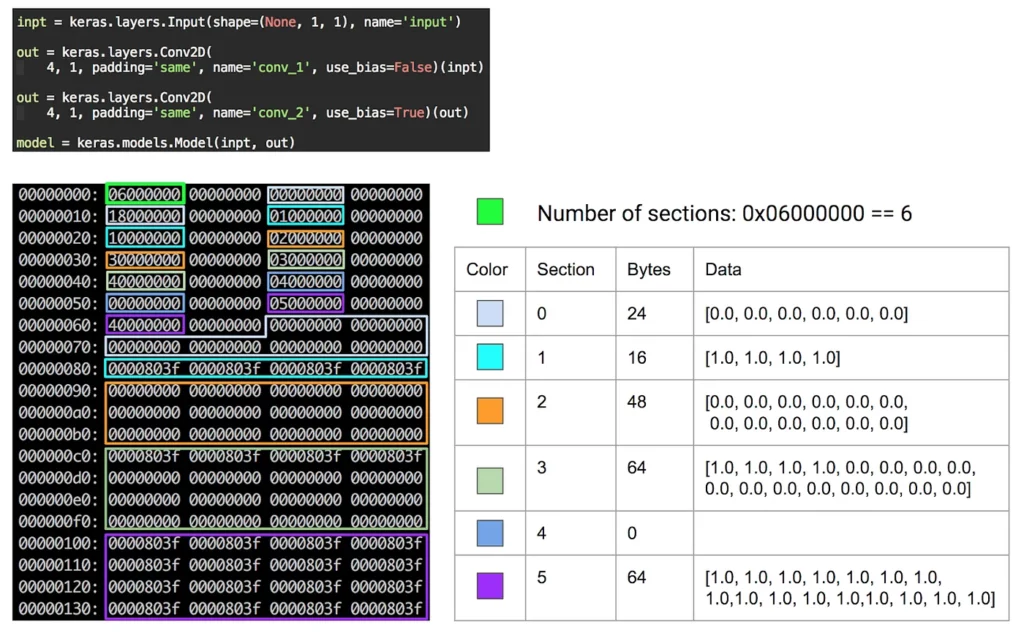
The weights file seems to be split into three parts: total number of sections, each section’s size in bytes, and the section data. In the second part, each section is described by an integer representing how many bytes of data the section has.
In the table above you can see how the values were obtained by matching the color of the section in the table with the highlighted binary values. From there, after reading all of the section descriptions, we can just load each of the section’s data. The weights are stored as floats. Here is the code for reading the weights file:
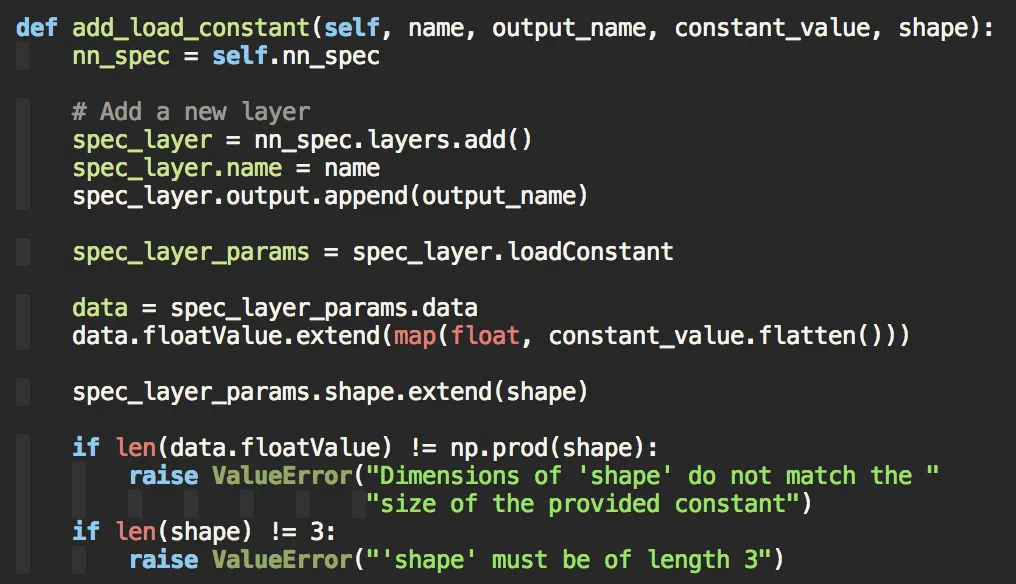
def read_compiled_weights(mlmodelc_path):
"""Read a compiled model.espresso.weights file.
Args:
mlmodelc_path (str): location of mlmodelc folder.
Returns: dict[int, list[float]] of section to list of weights.
"""
layer_bytes = []
layer_data = {}
filename = os.path.join(mlmodelc_path, 'model.espresso.weights')
with open(filename, 'rb') as f:
# First byte of the file is an integer with how many
# sections there are. This lets us iterate through each section
# and get the map for how to read the rest of the file.
num_layers = struct.unpack(' | Bytes in layer | |
while len(layer_bytes) < num_layers:
layer_num, _, num_bytes, _ = struct.unpack(' It turns out that the blob_weights and blob_biases entries correspond to the section numbers we found reading the binary file. We can then reshape the data in the appropriate size and successfully rebuild the convolution layer!
Your model isn’t safe!
This process is manual and tedious. A lot more work still needs to be done to create a generalized Core ML decompiler. But simply compiling a Core ML model does not protect it against IP theft.
Attackers with an iPhone can read the contents of an app and, with some work, rebuild the original model. Data stored on the client is inherently vulnerable, but stay tuned for ways to offer some layers of protection to on-device models.
Comments 0 Responses