
In this article, we’ll see how we can use the Luminoth library to detect objects in pictures or videos. Luminoth is an open source computer vision library built in Python and based on TensorFlow and Sonnet. This library was developed by Tryolabs. You can learn more about Luminoth and some of their other projects here:
Sonnet is a TensorFlow-based neural network library. Luminoth is a fairly new library in its alpha-quality release stage. One of the things we’ll do is illustrate how to use Luminoth to detect objects in images as in the picture shown below.
Installation
We can install Luminoth via a quick pip install command:
Luminoth provides pre-trained checkpoints we can use. It is, however, possible to adapt our own dataset and train it. Let’s dive right in.
The beauty of this library is that it makes the work of object detection easy. Let’s work through a simple example with this image.

In order to do this, we’ll need to first fire up our terminal. Predicting the objects in an image is fairly easy. However, before we can start making predictions, we have to download a checkpoint so we’ll have consistent starting points for those predictions. Luminoth provides the lumi command that we’ll use for most of the operations.
Managing checkpoints is done using the lumi checkpoint command, which will download pre-trained models that we’ll use to make predictions. This is such a big advantage—it takes a long time and a lot of computing power to train image recognition models. It is, however, possible to do your own training using cloud infrastructure (Google Cloud, AWS, etc.).
Let’s now look at our downloaded checkpoints. This is done via the lumi checkpoint list command.

We can clearly see that we have two checkpoints:
- Faster R-CNN w/COCO — An object detection model trained on the Faster R-CNN model. Uses the COCO dataset.
- SSD w/Pascal VOC—An object detection model trained on the Single Shot Multibox Detector (SSD) model. Uses the Pascal dataset.
We’ll now use Luminoth’s Command Line Interface to predict the objects in the image we showed above.
This command outputs the predictions in JSON command.

You and I can agree that this output isn’t visually appealing, to say the least. Luckily for us, the good people from Luminoth provide a way to output an image with the objects in the images as labels.
In order to do this, we’ll first create a directory called predictions to hold the JSON output and the predicted image. Remember that we’re still working on the terminal.
Once this is done, we can run the command that will make the predictions and return the images with the labeled objects.
This command might take a couple of minutes to run. Once it’s done we’ll see the output shown below in our predictions folder.

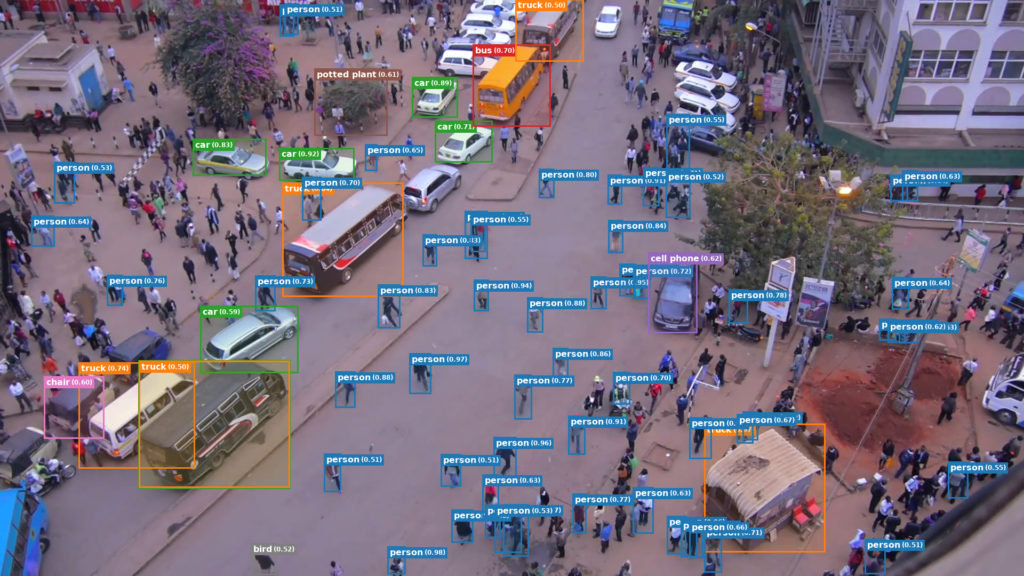
We can see that it predicted that the objects in the image are motorcycles with an accuracy of up to 100%. It was also able to predict the car behind the fence. Pretty cool, right?
Luminoth also allows us to runs predictions using specific checkpoints. Let’s proceed to check the Fast checkpoint and use it. We can do this using either its ID or alias.
or
Let’s use this checkpoint to predict the objects in the motorcycle image.
We’ll get a prompt to download the checkpoint locally, and when it’s downloaded the predictions will happen. We see that it was able to predict the motorcycle but wasn’t able to identify the car behind the fence.

Luminoth allows us to do these predictions on a web interface. To open the web interface run the following command.
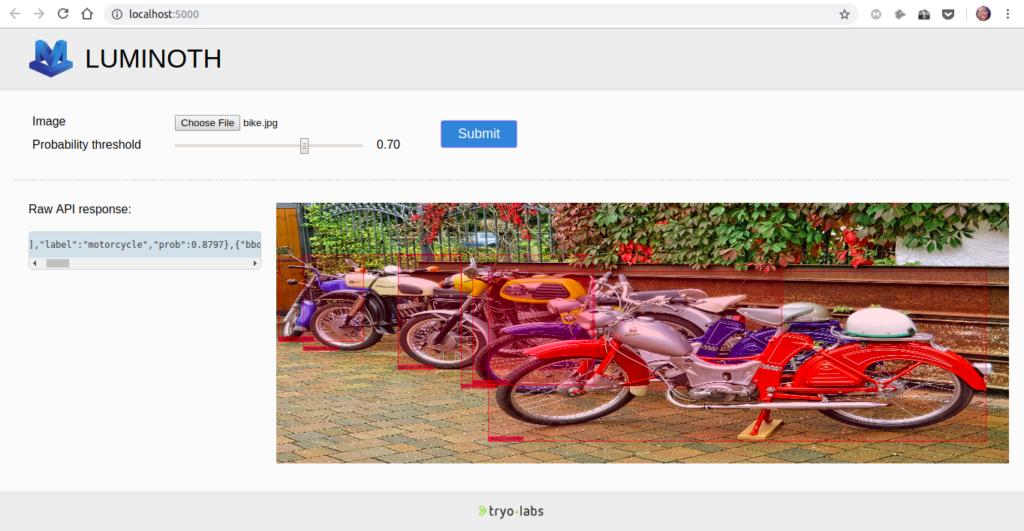
After that head over to http://localhost:5000/ to access the web interface.
All we have to do is browse for an image on our computer and hit the submit button. We can play around with the probability threshold. Increasing the threshold will give us fewer images with a higher probability, and decreasing it will give us more images with lower probability.
Another awesome thing we can do with this library is detect objects in a video. This process will take a while depending on the processing power of the computer.
Conclusion
There are very many computer vision tools out there. What makes Luminoth unique is how easy it is to implement. It also provides trained models that we can plug and play in our work. To learn more about this library check out the official docs.
Comments 0 Responses