
Generally speaking, human beings can recognize objects without too much effort or consideration. However, recognizing objects in images can be a very difficult task in the field of computer vision.
There are many use cases in which this difficulty becomes evident. One specific use case involves license plate detection—it’s particularly a big challenge because of the differences inherent in the plates (i.e. the objects) themselves: different sizes and styles, the conditions and lighting under which the images of the plates are captured, etc.
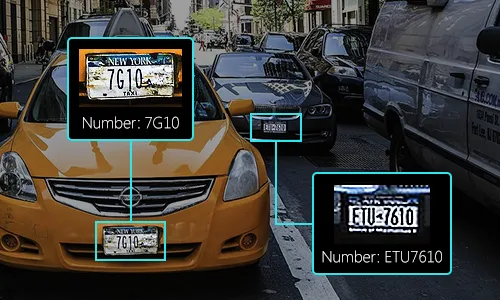
Nowadays, there are many commercial systems that involve license plate recognition, and it can be used in many use cases such as:
- Finding stolen cars: This kind of system can be deployed on the roadside, and makes a real-time comparison between passing cars and the list of stolen cars. When a match is found, an alert is issued to inform the police officer of the car detected and the reasons for stopping the car.
- Parking: The detected license plate number is used in car parks in order to calculate parking fees by comparing entry and exit times.
- Toll: The car number is used to calculate travel costs on a toll road, or used to re-check tickets.
- Access control: The automatic opening of a door for authorized members in a safety zone. This kind of system is set up to help security officers. Events are stored on a database and can be used to search event history when needed.
In this article, I’ll create a model that can detect and extract license plate text on an iOS application.
In this article:
What is object detection?
Artificial intelligence is a science that helps machines interact in the same way humans do—or at least it tries to do as much. A large part of this vast and exciting area is dedicated to computer vision.
Object detection is a very active area of research that seeks to classify and locate regions/areas of an image or video stream. This domain is at the crossroads of two others: image classification and object localization.
Indeed, the principle of the detection of objects is as follows. For a given image, one seeks the regions which could contain an object. For each of these discovered regions, one extracts and classifies them using an image classification model.
Regions of the original image with good classification results are retained and others are discarded. Thus, to have a good method of object detection, it’s necessary to have a strong sense of region detection and a good image classification algorithm.
The key to success is held in the image classification algorithm. Since the results of the 2012 ImageNet challenge, deep learning (especially convolutional neural networks) has become the number one method for solving this kind of problem. Object detection research has, of course, incorporated image classification models, which has led to the creation of state-of-the-art networks such as SSD (single-shot detector) and R-CNN (the R here means Region).

We can observe above that several objects can be discovered and located in the same image using these approaches.
YOLO Network Architecture:
Object detection is an image processing task at its core. This is why most pre-trained deep learning models to solve this problem are CNN networks. The model used in this tutorial is the small model YOLOv2, a more compact version of the original YOLOv2.
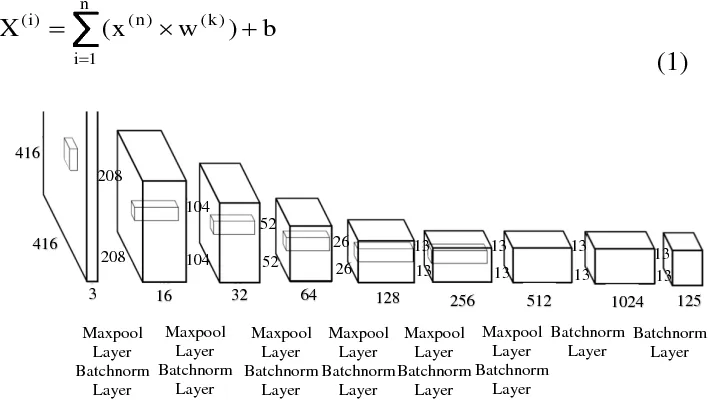
Tiny YOLOv2 consists of 15 layers that can predict 20 different classes of objects. Since Tiny YOLOv2 is a condensed version of the original YOLOv2 model, a trade-off is made between speed and accuracy. The different layers that make up the model can be visualized using tools like Netron. The model inspection produces a mapping of the connections between all the layers that make up the neural network, where each layer contains the name of the layer as well as the dimensions of the respective input/output.
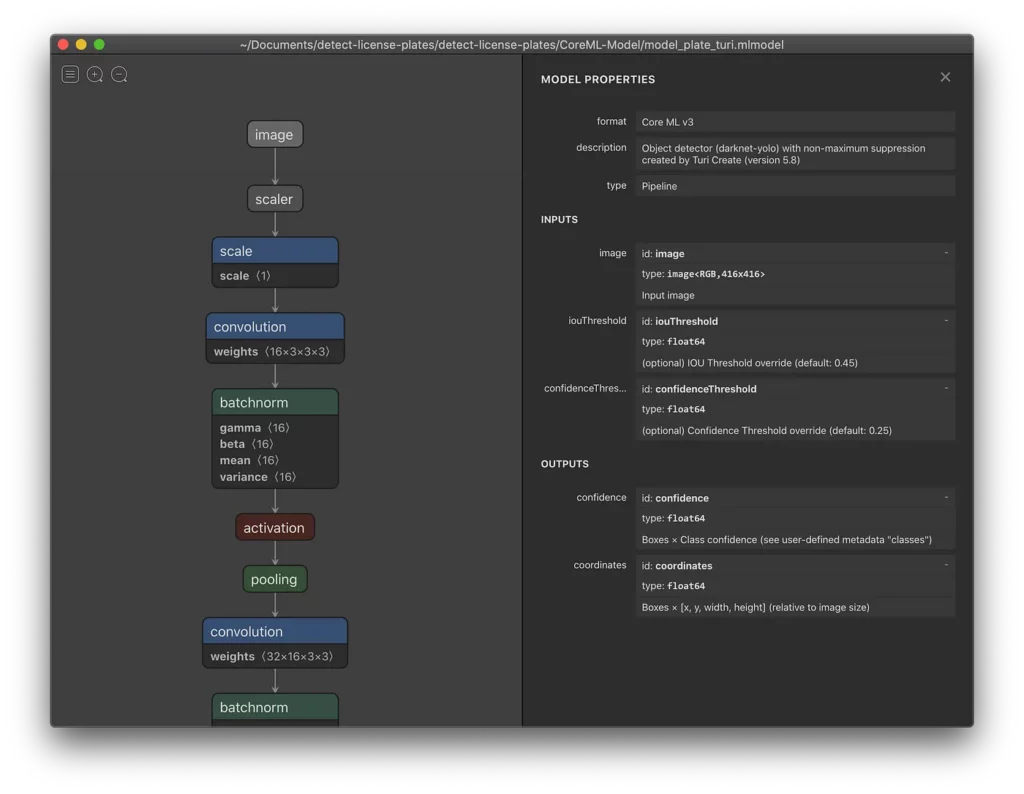
The data structures used to describe the inputs and outputs of the model are called tensors. Tensors can be considered as containers that store data in N dimensions. In the case of Tiny YOLOv2, the name of the input layer is image and it expects a tensor of dimensions 3 x 416 x 416. The name of the output layer is grid and generates an output tensor of dimensions 125 x 13 x 13.
Thanks to Turi Create, Apple’s library for machine learning, we won’t need to worry a lot about training and translating a custom Tiny YOLOv2 model—Turi Create will do a lot of the heavy lifting for us.
Apple’s API for text recognition
Since WWDC 19, Apple announced a dedicated API for Optical Character Recognition — OCR in short. This library is part of Apple’s Vision Framework for everything related to image and video processing. Text recognition allows us to detect and recognize text in images or even videos (processed frame-by-frame).
Find the dataset and annotate the images
There are many ways to gather an interesting dataset. Let’s say you want to only recognize license plates that are used in a specific state—you’d have to explicitly and only used car images with license plates of that given state.
Now, my goal here is to recognize plates in general, which means I’ll be using images of cars from different states.
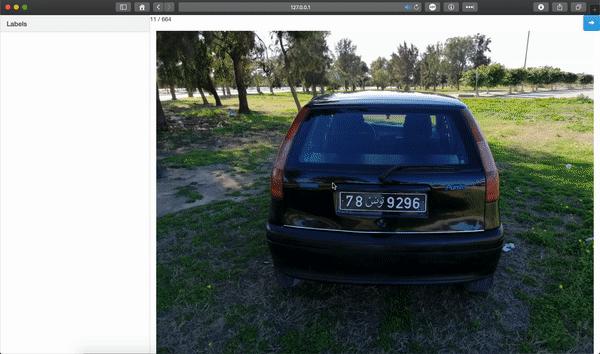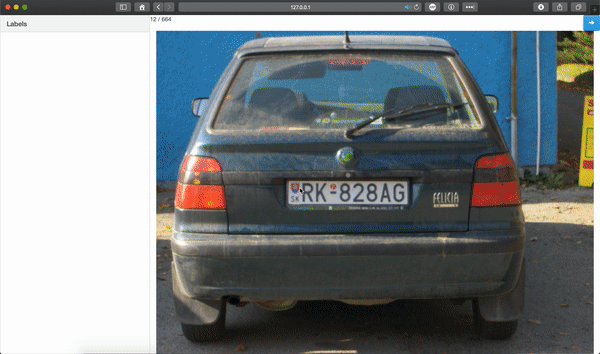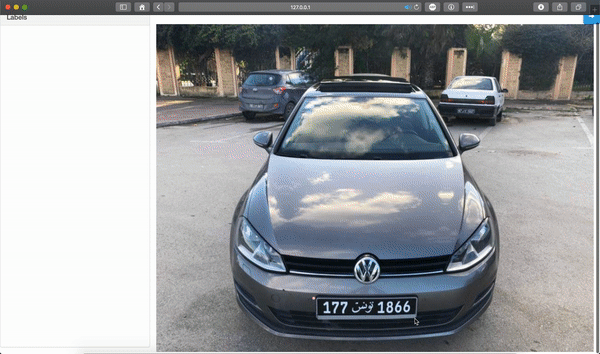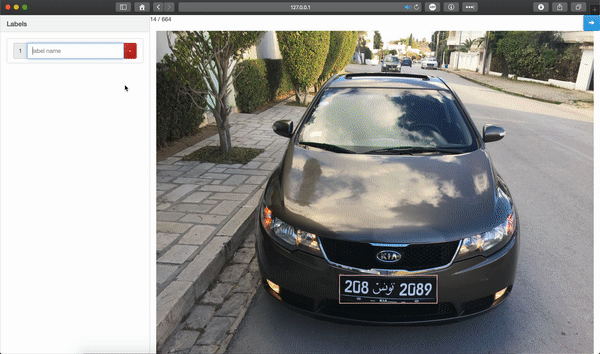
The first dataset will be based on Achraf KHAZRI’s dataset that I found on Kaggle. Based on the images included, I can guess that they were taken in Tunisia and are labeled, but we won’t be using the XML file since we’ll be annotating the dataset ourselves.

I also downloaded images on Google Images, with a total of 664 images.
Annotate the images:
To annotate the images, we’ll be using Sebastian G. Perez’s GitHub repository. It’s a simple Flask application that handles image annotation and generates a .csv file with 7 columns formatted in a way that can easily be used with Turi Create.
To train a model, we need a .csv file with 7 columns that contain the following information:
- image -> name of the image file
- id -> id of the annotation
- name -> label name (plate)
- xMin -> min x value of the bounding box*
- xMax -> max x value of the bounding box
- yMin -> min y value of the bounding box
- yMax -> max y value of the bounding box
Train the model
Training is pretty simple and straightforward.
I’ve been training with the free Tesla K80 GPU offered by Google, and it’s still a lot of calculation. What’s interesting is that the training time will increase linearly with the number of images and labels, which is good.
It took some time to force Turi Create to use the GPU on Colab, but it’s working perfectly now.
Build the iOS Application:
Create a new project:
To begin, we need to create an iOS project with a single view app. Make sure to choose Storyboard in the “User interface” dropdown menu (Xcode 11 only):
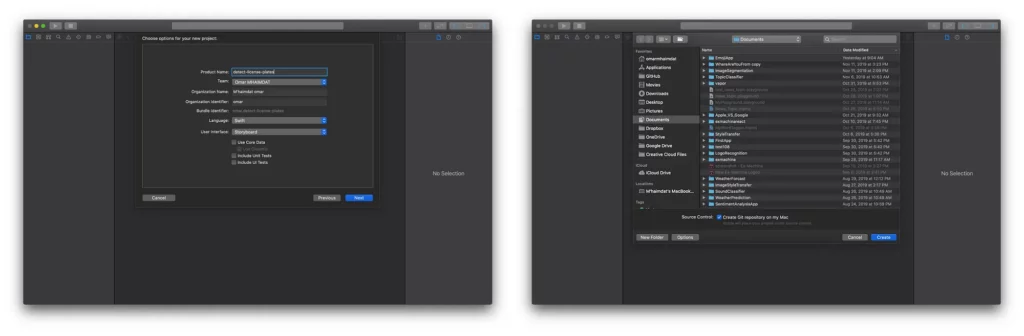
Now we have our project ready to go. I don’t like using storyboards myself, so the app in this tutorial is built programmatically, which means no buttons or switches to toggle — just pure code 🤗.
To follow this method, you’ll have to delete the main.storyboard and set your SceneDelegate.swift file (Xcode 11 only) like so:
func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) {
// Use this method to optionally configure and attach the UIWindow `window` to the provided UIWindowScene `scene`.
// If using a storyboard, the `window` property will automatically be initialized and attached to the scene.
// This delegate does not imply the connecting scene or session are new (see `application:configurationForConnectingSceneSession` instead).
guard let windowScene = (scene as? UIWindowScene) else { return }
window = UIWindow(frame: windowScene.coordinateSpace.bounds)
window?.windowScene = windowScene
window?.rootViewController = ViewController()
window?.makeKeyAndVisible()
}With Xcode 11, you’ll have to change the Info.plist file like so:
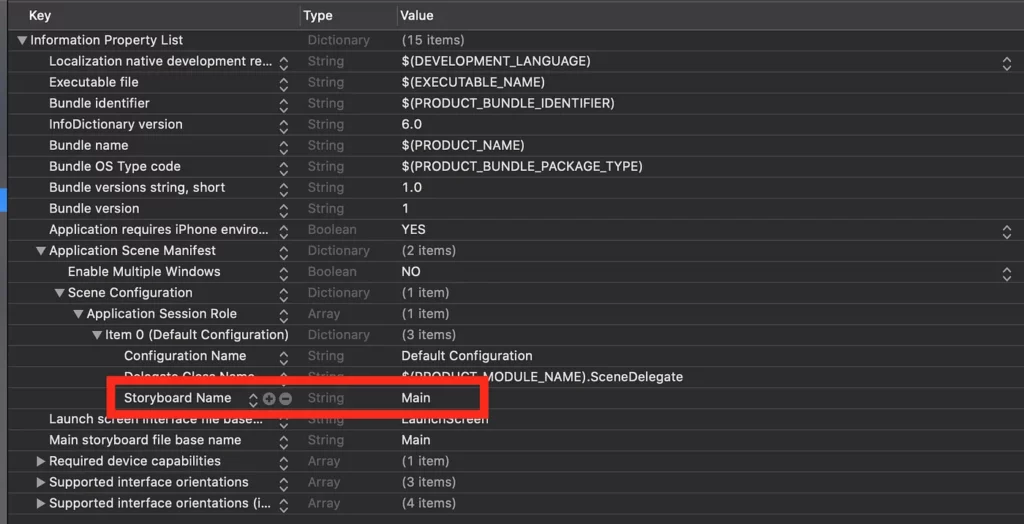
You need to delete the “Storyboard Name” in the file, and that’s about it.
Main ViewController
Our main UIViewController will host these elements:
- Video Capture View -> taking a live camera preview
- DrawingBoundingBoxView -> drawing the bounding boxes
- UILabel -> displaying the license plate number
Video Capture View
I’m using a VideoCapture class made by Eugene Bokhan, which is available in his Awesome-ML repository .
Here’s an explanation:
- Create a UIView instance to host the VideoCapture
- Start the VideoCapture in the viewWillAppear view cycle function
- Stop the VideoCapture in the viewWillDisappear view cycle function
- Setup the VideoCapture with the number of frames per second as well as the video quality. I’d recommend VGA 640×480 to get a steady FPS
- Set the VideoCapture delegate to conform to AVCaptureVideoDataOutputSampleBufferDelegate
var videoCapture: VideoCapture!
let semaphore = DispatchSemaphore(value: 1)
let videoPreview: UIView = {
let view = UIView()
view.translatesAutoresizingMaskIntoConstraints = false
return view
}()
override func viewWillAppear(_ animated: Bool) {
super.viewWillAppear(animated)
self.videoCapture.start()
}
override func viewWillDisappear(_ animated: Bool) {
super.viewWillDisappear(animated)
self.videoCapture.stop()
}
// MARK: - SetUp Camera preview
func setUpCamera() {
videoCapture = VideoCapture()
videoCapture.delegate = self
videoCapture.fps = 30
videoCapture.setUp(sessionPreset: .vga640x480) { success in
if success {
if let previewLayer = self.videoCapture.previewLayer {
self.videoPreview.layer.addSublayer(previewLayer)
self.resizePreviewLayer()
}
self.videoCapture.start()
}
}
}
extension ViewController: VideoCaptureDelegate {
func videoCapture(_ capture: VideoCapture, didCaptureVideoFrame pixelBuffer: CVPixelBuffer?, timestamp: CMTime) {
if !self.isInferencing, let pixelBuffer = pixelBuffer {
self.isInferencing = true
self.predictUsingVision(pixelBuffer: pixelBuffer)
}
}
}Bounding Box View
Create an instance of DrawingBoundingBoxView made by tucan9389.
This view will be the highest layer in the subview and will draw the bounding boxes:
let BoundingBoxView: DrawingBoundingBoxView = {
let boxView = DrawingBoundingBoxView()
boxView.translatesAutoresizingMaskIntoConstraints = false
return boxView
}()Create a UILabel to show the license plate number:
let identifierLabel: UILabel = {
let label = UILabel()
label.backgroundColor = .black
label.textAlignment = .center
label.translatesAutoresizingMaskIntoConstraints = false
label.textColor = .green
label.font = UIFont(name: "Avenir", size: 30)
return label
}()Set the layout and add it to the subview
override func viewDidLoad() {
super.viewDidLoad()
view.backgroundColor = .black
setUpModel()
setupLabel()
setupCameraView()
setUpCamera()
setupBoundingBoxView()
}
fileprivate func setupCameraView() {
view.addSubview(videoPreview)
videoPreview.bottomAnchor.constraint(equalTo: identifierLabel.topAnchor).isActive = true
videoPreview.leftAnchor.constraint(equalTo: view.leftAnchor).isActive = true
videoPreview.rightAnchor.constraint(equalTo: view.rightAnchor).isActive = true
videoPreview.topAnchor.constraint(equalTo: view.safeAreaLayoutGuide.topAnchor).isActive = true
}
fileprivate func setupBoundingBoxView() {
view.addSubview(BoundingBoxView)
BoundingBoxView.bottomAnchor.constraint(equalTo: videoPreview.bottomAnchor).isActive = true
BoundingBoxView.leftAnchor.constraint(equalTo: videoPreview.leftAnchor).isActive = true
BoundingBoxView.rightAnchor.constraint(equalTo: videoPreview.rightAnchor).isActive = true
BoundingBoxView.topAnchor.constraint(equalTo: videoPreview.topAnchor).isActive = true
}
fileprivate func setupLabel() {
view.addSubview(identifierLabel)
identifierLabel.bottomAnchor.constraint(equalTo: view.bottomAnchor, constant: -32).isActive = true
identifierLabel.leftAnchor.constraint(equalTo: view.leftAnchor).isActive = true
identifierLabel.rightAnchor.constraint(equalTo: view.rightAnchor).isActive = true
identifierLabel.heightAnchor.constraint(equalToConstant: 200).isActive = true
}Handle the CoreML model
This is the part where we handle the model as well as the text recognizer.
Here’s an explanation:
- Create a request to handle our .mlmodel with a special completionHandler
- Create a request to recognize the text with a special completionHandler
- Call the vision handler to perform both requests
- Get the prediction from the model and drawing the boxes
- Handle the images to get the text and updating the label with recognized text
// MARK: - Setup CoreML model and Text Request recognizer
func setUpModel() {
if let visionModel = try? VNCoreMLModel(for: model_plate_turi().model) {
self.visionModel = visionModel
request = VNCoreMLRequest(model: visionModel, completionHandler: visionRequestDidComplete)
OcrRequest = VNRecognizeTextRequest(completionHandler: visionTextRequestDidComplete)
request?.imageCropAndScaleOption = .scaleFill
} else {
fatalError("fail to create vision model")
}
}
extension ViewController {
func predictUsingVision(pixelBuffer: CVPixelBuffer) {
guard let request = request else { fatalError() }
guard let OcrRequest = OcrRequest else {fatalError()}
OcrRequest.recognitionLevel = .fast
// vision framework configures the input size of image following our model's input configuration automatically which is 416X416
self.semaphore.wait()
let handler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer)
try? handler.perform([request, OcrRequest])
}
// MARK: - Post-processing
func visionRequestDidComplete(request: VNRequest, error: Error?) {
if let predictions = request.results as? [VNRecognizedObjectObservation] {
DispatchQueue.main.async {
self.BoundingBoxView.predictedObjects = predictions
self.isInferencing = false
}
} else {
self.isInferencing = false
}
let request = VNRecognizeTextRequest { (request, error) in
guard let observations = request.results as? [VNRecognizedTextObservation] else { return }
for currentObservation in observations {
let topCandidate = currentObservation.topCandidates(1)
if let recognizedText = topCandidate.first {
DispatchQueue.main.async {
self.identifierLabel.text = recognizedText.string
}
}
}
}
request.recognitionLevel = .fast
self.semaphore.signal()
}
func visionTextRequestDidComplete(request: VNRequest, error: Error?) {
guard let observations = request.results as? [VNRecognizedTextObservation] else { return }
for currentObservation in observations {
let topCandidate = currentObservation.topCandidates(1)
if let recognizedText = topCandidate.first {
DispatchQueue.main.async {
self.identifierLabel.text = recognizedText.string
}
}
}
self.semaphore.signal()
}
}
Conclusion
This is only a small example of what you can achieve with very little effort. License plate readers do exists but are still used in a very controlled environment. What makes this task hard and very challenging is the whole pipeline architecture that will handle the video stream, the text recognition, and exploiting the data to make a decision based on the output.
You can imagine how hard it will be to trust a license plate detection model — which isn’t always accurate—and may prompt some mistakes and false positives.
Nevertheless, you can still improve the model with more and cleaner data, but you can also improve your pipeline.
If you liked this tutorial, please share it with your friends. If you have any questions don’t hesitate to send me an email at [email protected].
This project is available to download from my GitHub account.
Comments 0 Responses