
The steady rise of mobile Internet traffic has provoked a parallel increase in demand for on-device intelligence capabilities. However, the inherent scarcity of resources at the Edge means that satisfying this demand will require creative solutions to old problems. How do you run computationally expensive operations on a device that has limited processing capability without it turning into magma in your hand?
The addition of TensorFlow Lite to the TensorFlow ecosystem provides us with the next step forward in machine learning capabilities, allowing us to harness the power of TensorFlow models on mobile and embedded devices while maintaining low latency, efficient runtimes, and accurate inference.
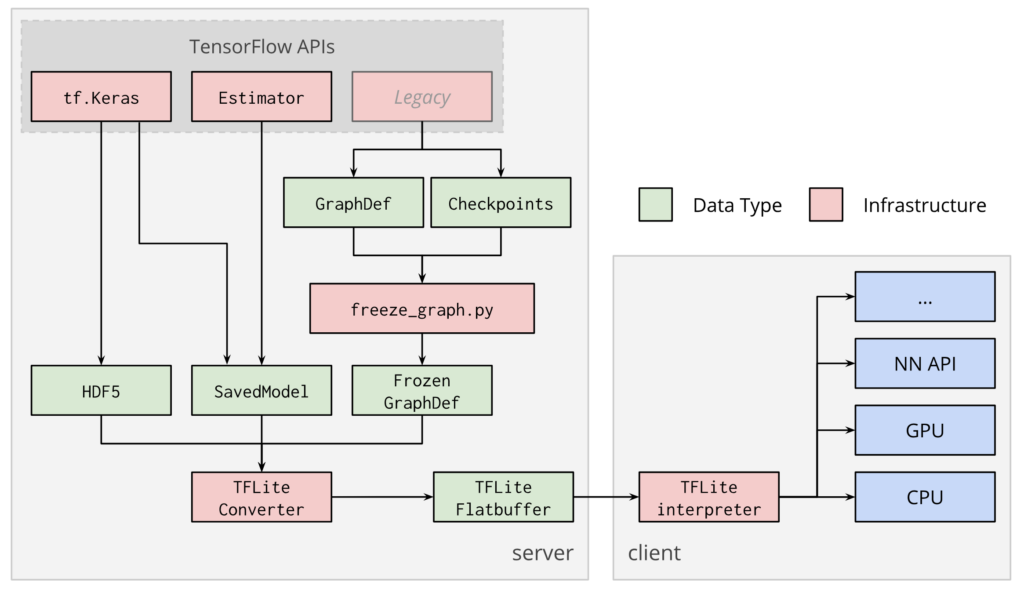
TensorFlow Lite provides the framework for a trained TensorFlow model to be compressed and deployed to a mobile or embedded application. Interfacing with the TensorFlow Lite Interpreter, the application can then utilize the inference-making potential of the pre-trained model for its own purposes.
In this way, TensorFlow Lite works as a complement to TensorFlow. The computationally expensive process of training can still be performed by TensorFlow in the environment that best suits it (personal server, cloud, overclocked computer, etc.).
TensorFlow Lite takes the resulting model (frozen graph, SavedModel, or HDF5 model) as input, packages, deploys, and then interprets it in the client application, handling the resource-conserving optimizations along the way.
If you’re familiar with the TensorFlow ecosystem, you might ask “Doesn’t TensorFlow Mobile already address this use-case?” And you would be right… sort of. TensorFlow Mobile was the TensorFlow team’s first solution for extending model functionality to mobile and embedded devices.
However, TensorFlow Lite offers lower latency, higher throughput, and a generally lighter weight solution that will be the focus of the TensorFlow team for 2019 and beyond. Magnus Hyttsten, a Developer Advocate on Google’s TensorFlow team makes a clear statement on the difference between the two:
TensorFlow Lite functionally differs from TensorFlow Mobile in the degree to which it has been optimized to support this process of transformation, deployment, and interpretation. TensorFlow Lite has been leveraged at every level from the model translation stage to hardware utilization to increase the viability of on-device inference while maintaining model integrity.
Below, we take a look at a few of the key optimizations across the components of TensorFlow Lite.

Model Conversion
The TensorFlow Lite Converter (TOCO) takes a trained TensorFlow model as input and outputs a TFLite (.tflite) file, a FlatBuffer-based file containing a reduced, binary representation of the original model.
FlatBuffers play an essential role in efficiently serializing model data and providing quick access to that data while maintaining a small binary size. This is particularly useful for model files that are heavily populated with numerical weight data that can, by virtue of their size, create a lot of latency in read operations.
Using FlatBuffer protocols as the basis for this transformation, TensorFlowLite can bypass a lot of the traditionally expensive file parsing and un-parsing that contributes to slower execution.
Interpreter Core
The Interpreter Core is responsible for executing Lite models in client applications using a reduced set of TensorFlow’s operators. By limiting the default operators, libraries, and tools required to run the Lite models, the Interpreter Core has been trimmed to a lean ~100kb alone or ~300kb with all supported kernels.
TensorFlow Mobile on the other hand required ~1.5MB. That said, if you find your model requires operators outside the provided set, TensorFlow Lite allows for the implementation of custom operators. This opinionated dependency handling is key to keeping TensorFlow lean and light.
Hardware acceleration
TensorFlow Lite optimizations reach all the way down to the hardware. Working within the tight constraints of mobile and embedded devices means that processors must be utilized at a hyper-efficient standard.
The Android NDK contains a Neural Network API (NNAPI) that provides access to hardware-accelerated inference operations on Android devices. The NNAPI interfaces with TensorFlow Lite to seek out paths for model operations to leverage advantageous hardware where available. With the expectation of machine learning hardware becoming more available on Edge devices, the advantages of the NNAPI framework will become more apparent.
Additionally, on January 16, 2019, the TensorFlow team released support for a GPU backend that will allow for a subset of models and operations to selectively utilize GPUs on mobile devices. The update will benefit models with excess parallelizable work and those that suffer from quantization precision-loss, giving them increases in speed and efficiency (up to 7x for some neural nets).
The TensorFlow team promises to increase the set of models and operators currently supported to provide more comprehensive coverage in the future.
Quantization
Quantization is an increasingly important component of neural networks that deserves its own in-depth discussion (several, really), so I’ll just touch on the main points as they relate to the TensorFlow Lite and link to dedicated discussions at the end.
Generally, quantization refers to the process of reducing a continuous set of numbers to a smaller set of continuous numbers without losing the descriptive character of the initial set. In the context of neural networks, this typically means reducing operation precision from 32-bit floating point numbers to 8-bit values.
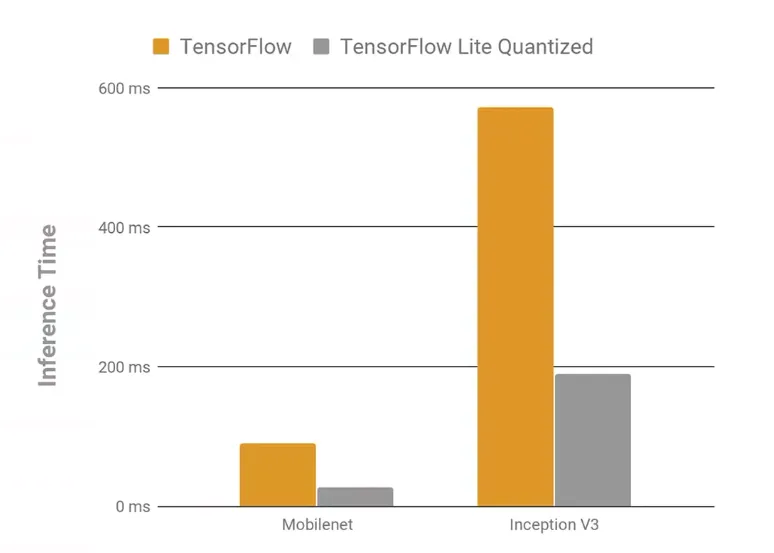
Post-training quantization is encouraged in TensorFlow Lite and is provided as an attribute of the TOCO converter during the conversion step. Benchmarking has shown that compressed model inference latency can be reduced up to 3x while maintaining a negligible drop in inference accuracy.
Aggregated, these core optimizations provide us a reliable framework within which we can continue to probe the frontiers of on-device machine learning. The impending release of TensorFlow2.0 and expected updates to TensorFlow Lite should encourage us to stay up-to-date with the decisions of the TensorFlow team as they both look ahead and reflect on the direction of the mobile machine learning ecosystem.
Further Reading
Quantization
- Manis Sahni’s very digestible piece on Quantization
- Quantization and Neural Nets
- TensorFlow Lite Post-Training Quantization recommendations
TensorFlow Lite Resources
- Google I/O 2018 presentation on TensorFlow Lite
- TensorFlow Lite Docs
- FlatBuffer Docs
- Basic Neural Net on TensorFlow Lite tutorial.
Comments 0 Responses