
Big data and machine learning, while two separate concepts, remain interwoven in many aspects. The ability to process vast piles of data for machine learning tasks is a requirement of the field.
Apache Spark is a great framework when it comes to large-scale data processing (and has been for a while), enabling you to work with a range of big data problems. Apart from supporting cluster computing and distributivity with various languages such Java, Scala, and Python, Spark offers support for a variety of ML capabilities via its native libraries. However, its selling point remains its potential for ETL processing with large scale datasets.
On the other hand, H2O is an open source machine learning platform that is centered on scalability. Designed to work with distributed data, it integrates seamlessly with big data frameworks such as Hadoop and Spark to build more efficient ML models.
H2O provides a range of supervised and unsupervised algorithms and an easy-to-use browser based interface in the form of a notebook called Flow. H2O.ai was one of the first to introduce automatic model selection and was named among the top 3 AI and ML solution providers in 2018.
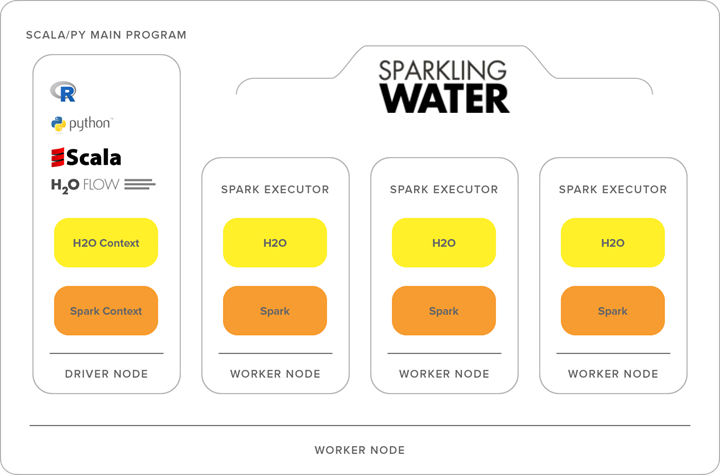
Best of Both Worlds: Sparkling Water
Sparkling Water combines the vast H2O machine learning toolkit with the data processing capabilities of Spark.
It’s an ideal solution for users who need to manage large data clusters and want to transfer data between Spark and H2O. By consolidating these two open-source frameworks, users can query big datasets using Spark SQL, feed the results into an H2O cluster to build a model and make predictions, and then reuse the results in Spark.
The end game here is deploying much more advanced machine learning algorithms with the existing Spark implementation. Results from the H2O pipeline can easily be deployed independently or within Spark, thus offering even more flexibility.
Automating ML with H2O
The process of automating machine learning, referred to as AutoML, is now a standard feature across various platforms such as Azure, Google Cloud, and so on. With AutoML, several steps in an end-to-end ML pipeline can be taken care of with minimal human intervention, without affecting the model’s efficiency.
Some of these steps where AutoML proves useful are data preprocessing tasks (augmentation, standardization, feature selection, etc.), automatic generation of various models (random forests, GBM etc.), and deploying the best model out of these generated models.
The current version of AutoML (in H2O, 3.16) trains and cross-validates a default random forest, an extremely-randomized forest, a random grid of gradient boosting machines (GBMs), a random grid of deep neural nets, a fixed grid of GLMs, and then two stacked ensemble models at the end. One ensemble contains all the models (optimized for model performance), and the second ensemble contains just the best performing model from each algorithm class/family (optimized for production use).
H2O’s AutoML is a useful tool for all kinds of ML developers—novices as well as experts. By automating a large number of modeling-related tasks that would typically require many lines of code, it allows devs more time to focus on other aspects of the ML pipeline.
The AutoML interface has so few parameters that need to be specified, that all the user needs to do is to point to their dataset, identify the columns needed for predictions, and specify a limit on the number of total models trained, if there is a time constraint for the pipeline.
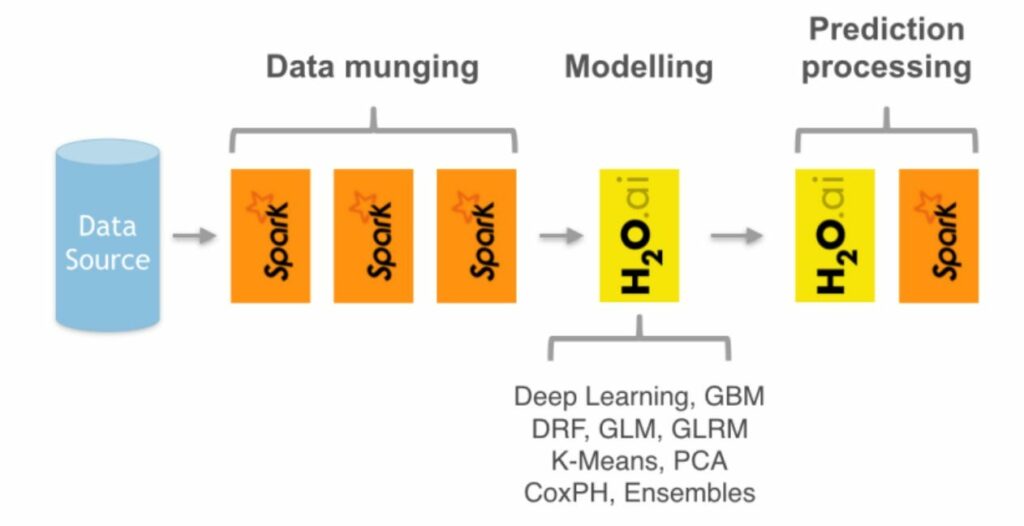
Deploying AutoML in Apache Spark
Let’s take a closer look at the Spark & H2O integration, where we’ll use Spark for data pre-processing tasks and H2O for the modeling phase, with all these steps wrapped inside a Spark Pipeline.
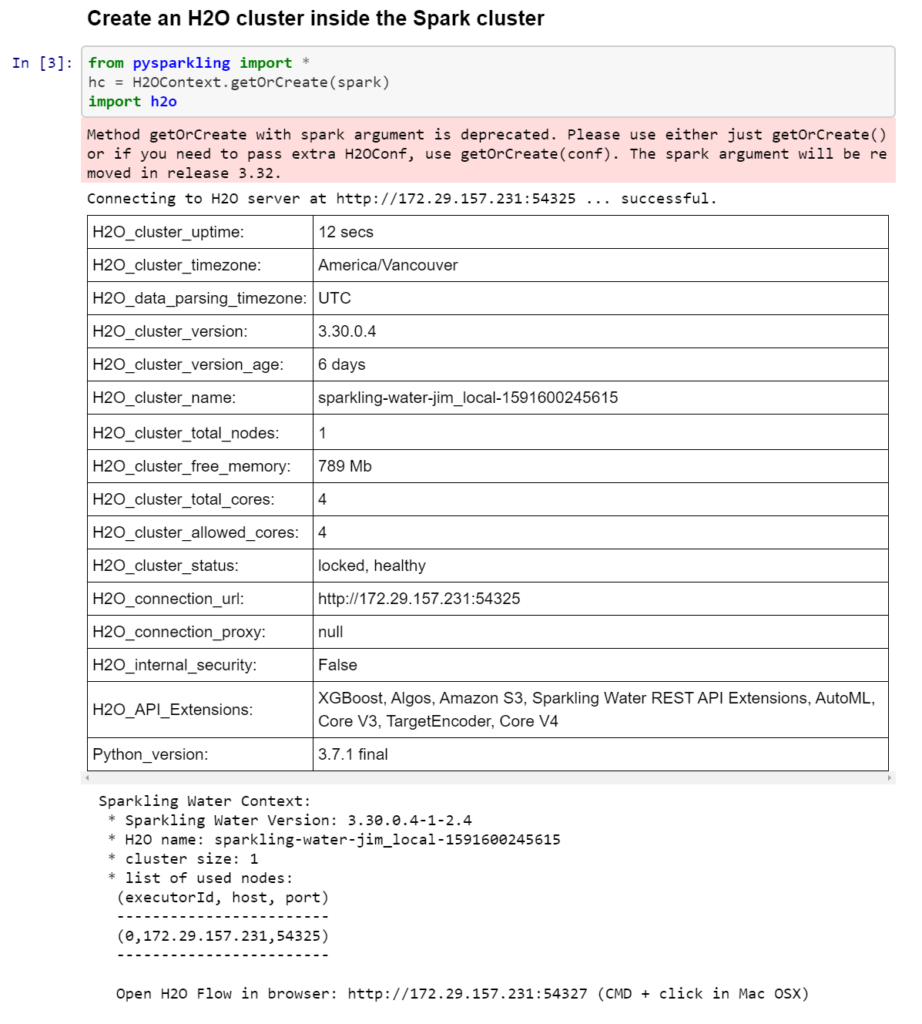
To use H2O with Spark, we need to first download the Sparkling Water package. This package allows us to use both Spark and H2O side-by-side, but first we need to make H2O available inside the Spark cluster. For Python users, this can be achieved by with pysparkling, as shown in this image below:
H2O has its own way of working with datasets, and the corresponding version of a Spark dataframe is an H2O frame. Sparkling Water provides a method to interchange Spark dataframes with H2O frames, and vice versa. Here’s a snippet to convert a Spark frame to H2O and describe it:
An H2O+Spark pipeline means a lot of data transformations such as this, and allowing each module their own chance to do what they do best. While this increases the scope for error, Sparkling Water has some great documentation and helpful videos to better manage your data pipeline.
To define the Spark pipeline containing H2O AutoML, we need a few imported packages before we can start building the pipeline stages:
The estimator stage is where we build the H2O model using the H2O AutoML algorithm. This estimator is provided by the Sparkling Water library, but we can see that the API is unified with the other Spark pipeline stages:
This call goes through all the pipeline stages, and in the case of estimators, creates a model. So as part of this call, we run the H2O AutoML algorithm and find the best model given the search criteria we specified in the arguments.
The model variable contains the whole Spark pipeline model, which also internally contains the model found by AutoML. The H2O model stored inside is stored in the H2O MOJO format. That means that it’s independent from the H2O runtime, and therefore, it can be run anywhere without initializing an H2O cluster. This model can then be saved, exported, or deployed to production.
Summary
AutoML is a useful feature when it comes to automating some of the more mundane and time-consuming tasks in a machine learning pipeline, such as feature selection, hyperparameter tuning, and more.
Working in tandem, ML developers and AutoML can get tasks done much faster and more efficiently. With H2O’s AutoML offering, big data processing with Apache Spark provides a wider range of AI capabilities and functionality to choose from than native libraries.
H2O’s AutoML also reduces the amount of human effort required in a machine learning workflow, with things like the automatic training and tuning of many models within a user-specified time-limit. With a wide range of cutting edge ML algorithms, the integration of H2O and Spark make way for more efficient, open-source, distributed computing.
Comments 0 Responses