
Text embeddings always play an important role in natural language-related tasks. The quality of text embeddings depends upon the size of the dataset that the model is trained on which improves the quality of features extracted. Instead of training the model completely from scratch, one can use pre-trained models like Google’s Universal Sentence Encoder which is discussed in this story ahead.
What is Transfer learning?
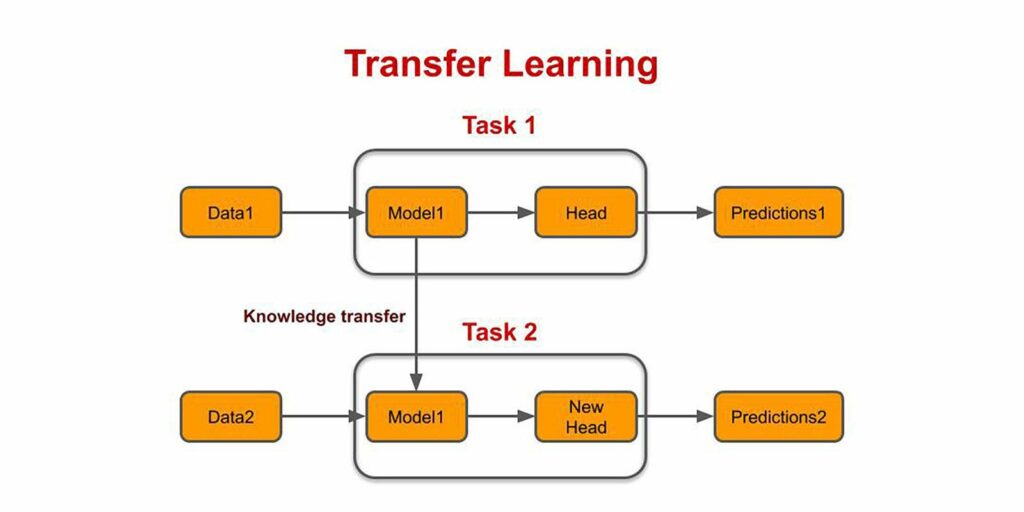
Transfer learning is is a machine learning technique in which a network that has been trained for one task is restructured/reused for another task, using the previous as the starting point.
Learning a new task relies on previous learned tasks. For example, ImageNet is a dataset that contains millions of images of different classes. Suppose we have a CNN trained on ImageNet which applies convolutions and further compressess the feature maps to feed it into a fully connected dense layer to predict three different classes. We can use the same inner layers and freeze this part of the network and transfer knowledge from this network to another network which is being trained on another set of data.
Need of pre-trained models
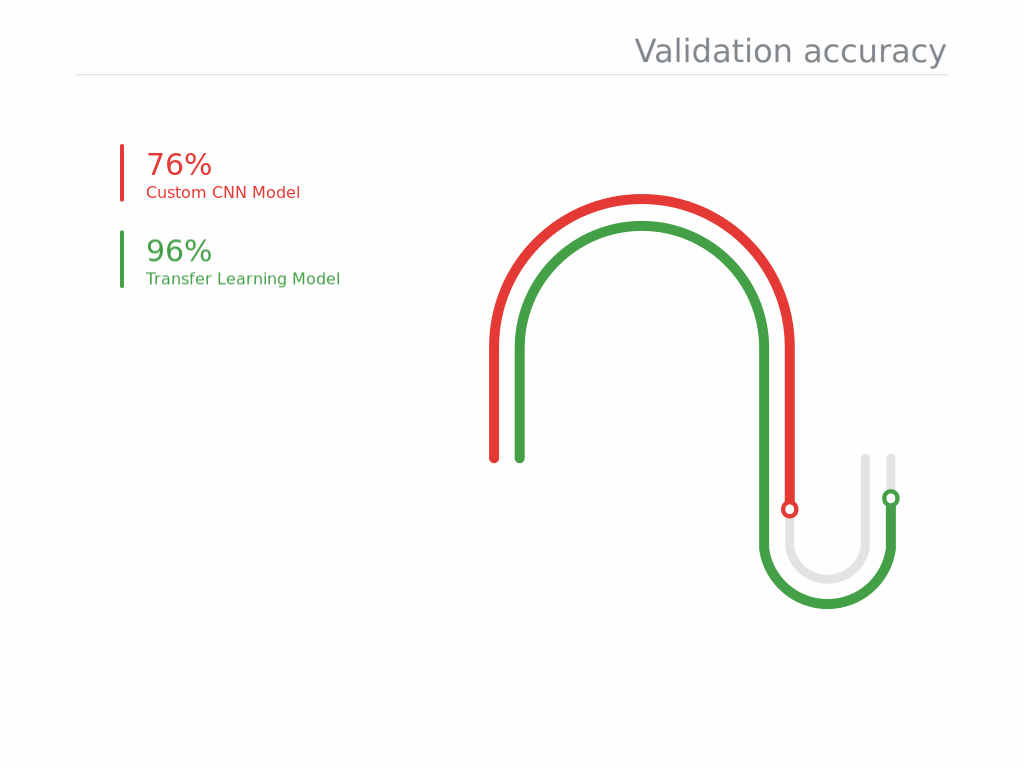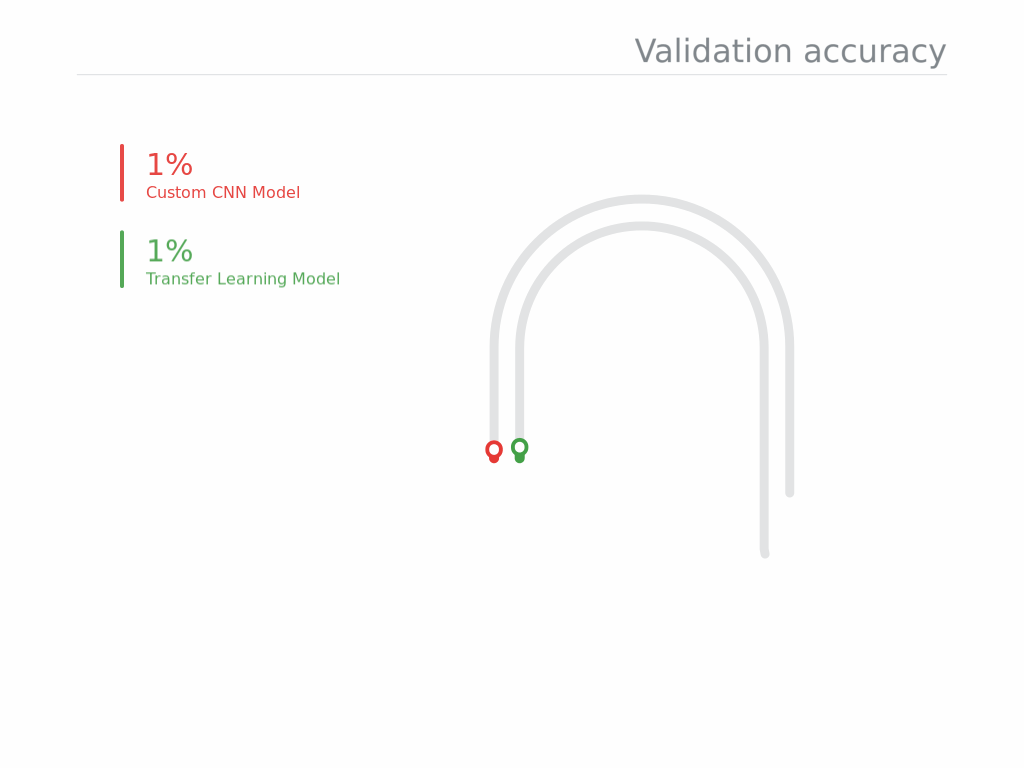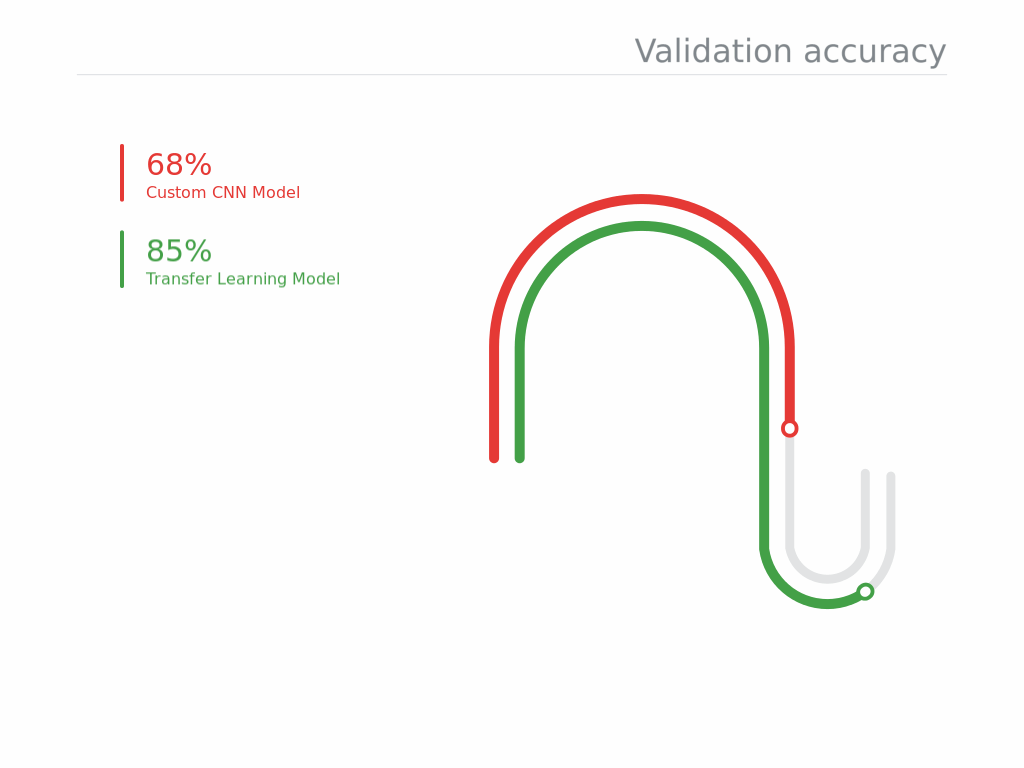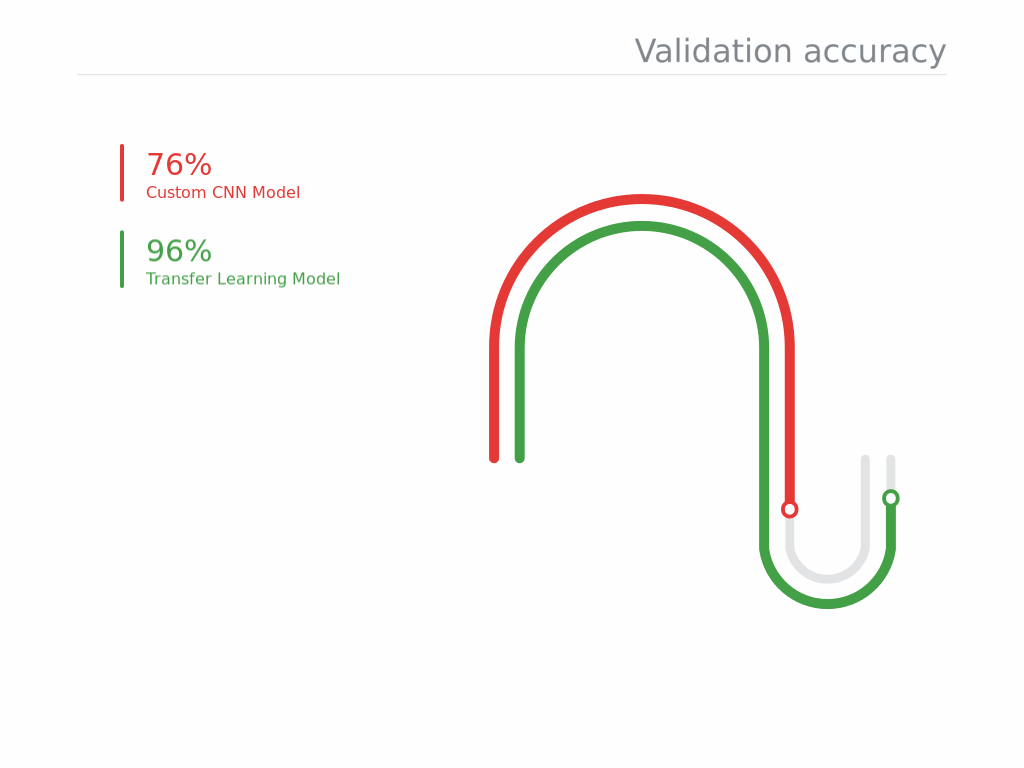
- Development time of model is less while utilizing knowledge from a pre-trained model as compared to one being built from scratch.
- Requires less training data.
- Better performance of the model.
Universal Sentence Encoder model
The universal sentence encoder model encodes textual data into high dimensional vectors known as embeddings which are numerical representations of the textual data. It specifically targets transfer learning to other NLP tasks, such as text classification, semantic similarity, and clustering. The pre-trained Universal Sentence Encoder is publicly available in Tensorflow-hub.
It is trained on a variety of data sources to learn for a wide variety of tasks. The sources are Wikipedia, web news, web question-answer pages, and discussion forums. The input is variable length English text and the output is a 512 dimensional vector. It has shown excellent performance on the semantic textual similarity (STS) benchmark.
Training procedures followed
Two variants of the TensorFlow model allow for trade-offs between accuracy and computing resources.
1. Transformer
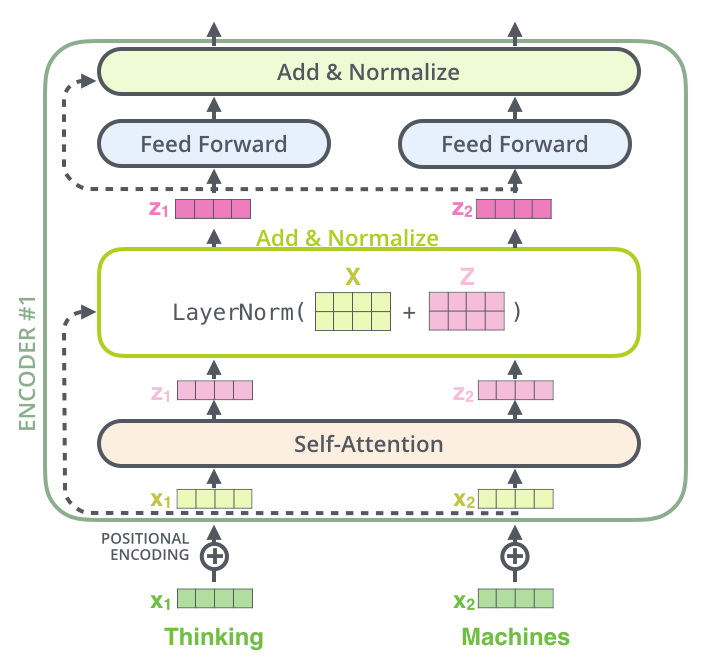
Each sentence has separate tokens/words that are converted into numerical data by the encoder.
- Multi-headed attention: This module processes self-attention which allows the model to associate each individual word to other words of the sentence. This helps the model to learn about the structure of the sentence. It produces attention weights for input and produces an output vector with information on how each word should be associated with others.
- Residual Connections: The multi-headed attention vector is added to the original input which is called the residual connection. This module helps the network train by allowing gradients to flow through the network directly.
- Layer Normalization: The output of the residual connection which goes to layer normalization. This module is used to stabilize the network.
- Pointwise Feed Forward: The output of the above module is fed to Pointwise feed forward network for further processing. These are a couple of linear layers with ReLu activation function giving the features a richer representation.
The above mentioned modules are repeated N times to finally output the embeddings. This technique performs better at the cost of computation time as the network is trained on multiple tasks.
2. Deep Averaging Network
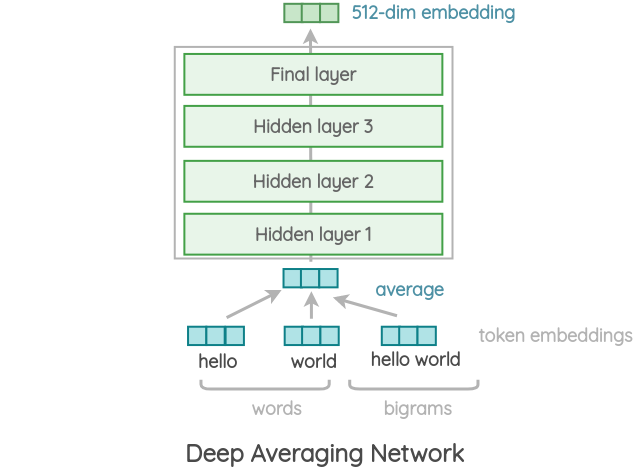
The input embeddings for words and bi-grams are first averaged together and then passed through a feedforward deep neural network (DNN) to produce sentence embeddings. It follows the same strategy of the transformer encoder. The primary advantage of this network is that the training time is less and almost linear in terms of the length of the input sentence.
How is this model different?
Earlier sentence embeddings were calculated by averaging all the embeddings of the words in the sentence, however, just adding or averaging had limitations and was not suited for deriving true semantic meaning of the sentence. The Universal Sentence Encoder makes getting sentence level embeddings easy.
Hands-on experience of using Universal Sentence Encoder
After knowing how universal sentence encoder works, it’s best to have hands-on experience starting from how to load the pre-trained model to using the embeddings in getting similarity measure between sentences. Below are a few examples of how to use the model.
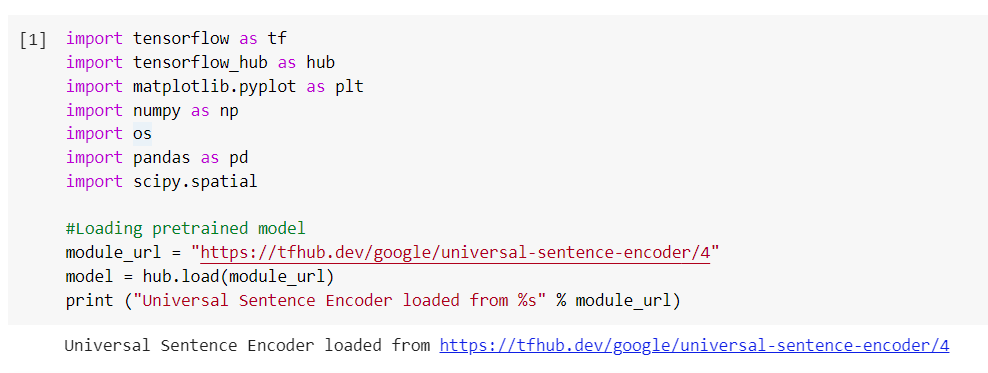
- Loading the pre-trained model:
- Getting embeddings for a sentence:
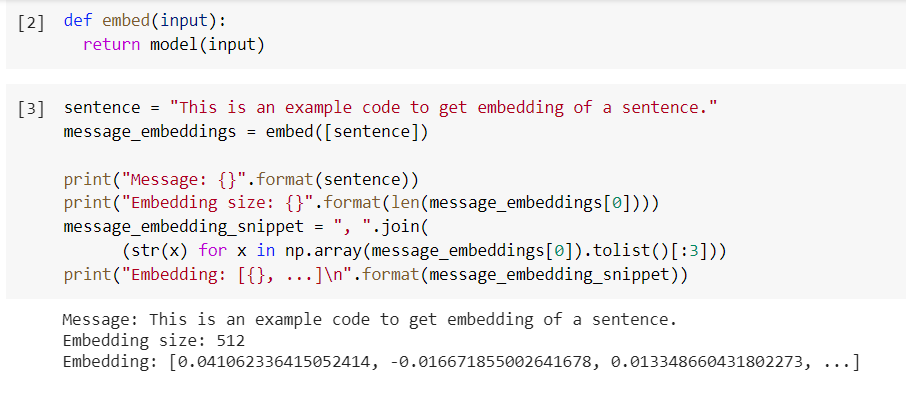
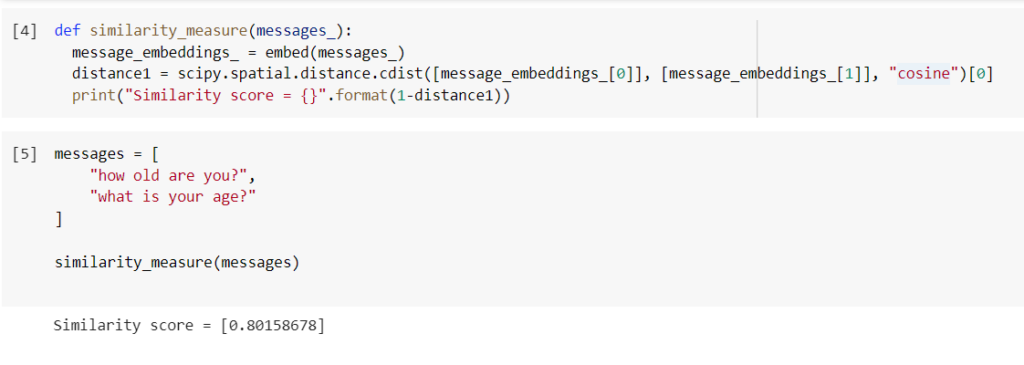
- Measuring textual similarity: Embeddings can be listed as continuous numerical representations of the textual data and contain important features. If two embeddings are closer, the sentences are said to be semantically similar. Thus, embeddings generated from this model can be used in measuring semantic similarity score as a use-case.
Conclusion
We have seen how transfer learning has made our life easy by providing pre-trained models to help us in scenarios where less training data is available or higher performance is to be achieved. We can fine-tune this pre-trained model with our own data by freezing some layers of the existing model or adding new layers according to our needs. For more information, one can refer to this paper.
Happy learning!
Comments 0 Responses