
Deep Learning with JavaScript

This series of articles I’ll be writing over the coming weeks will focus on using JavaScript and the deep learning framework TensorFlow.js. Though I’ll try to make these articles as easy as possible, I’m making the following assumptions about you, the reader.
You have:
- Basic knowledge of JavaScript, either as a frontend or backend engineer.
- Basic knowledge of JavaScript package managers (npm or yarn).
- Basic knowledge of deep learning. Maybe you’re from a Python background and have built deep learning models with TensorFlow/Keras.
- Basic knowledge of GitHub and version control.
If you don’t fall into all the categories, not to worry. I promise that you’ll definitely still learn some valuable insights from this series.
But first, why JavaScript for deep learning?
JavaScript is the most popular language in the world right now. It’s already used practically everywhere, and the good news is that you can also efficiently use JavaScript for deep learning and machine learning tasks. Below, we list several reasons why you should consider it for your next project:
- Simplified deployment: Most deep learning engineers build and train their models with Python and then embed them in web applications for deployment. Using JavasScript keeps your stack as uniform as possible. That is, you use JavaScript for everything, including UI, the backend, model building and training, and also inference.
- Easier Inference and Privacy: With JavaScript, inference is easier, as it happens locally—both in terms of getting data (camera, videos, audio), and the fact that data is local to the client. That is, data never leaves the client-side. Plus one for privacy.
- Cross-platform support: Your model can run anywhere JavaScript can run…and that’s a lot of platforms/devices.
- Zero-install user experience: Since your model can run in the browser, users don’t need to install any specific package or tool in order to use your deep learning application. Another plus one for the user experience.
Some other reasons include:
- Javascript runs everywhere. It runs on mobile phones, laptops, desktops, palmtops, and so on. And wherever you have your browser, you have JavaScript!
- There is an abundance of data visualization and analytical tools like d3.js, plotly.js, chart.js, anycharts and so on.
- There’s a robust, active, and talented community of JavaScript developers around the world. This means deep learning applications built with JavaScript can easily maintained and improved over time.
Why Use TensorFlow.js

The simple answer is that TensorFlow.js is more popular, mature, and well-established than any of its alternatives.
Another reason is the fact that the API is very similar to Keras’s API. If you understand Keras, then you understand TensorFlow.js.
TensorFlow.js was created by Nikhil Thorat and Daniel Smilkov at Google. It initially started as deeplearn.js, before it was rebranded to mimic the Keras API and later named TensorFlow.js.
TensorFlow.js has numerous practical advantages over other JavaScript deep learning libraries:
- It supports both web browsers (frontend) and Node.js (backend). That is, it can be run both from the frontend over a CDN using the WebGL of the browser, and also using higher resources from the backend with Node.js.
- It has GPU support using WebGL in browsers and CUDA kernels in Node.js.
- It supports easy conversion/porting between models built with JavaScript to Python and vice versa. This is definitely one of the best features.
- Supports saving and reloading of saved models.
- Has built-in support for ingesting data.
- And finally, it has support for model visualization and evaluation.
Still in doubt? Then check out this amazing collection of applications built with JavaScript and TensorFlow.js.
So what are we building in this part?
In this first article, we’ll start small. I’ll show you how to build a simple regression model with TensorFlow.js to predict areas of forest that have been burned by fire. Hopefully, you can learn enough here to follow along in future articles.
Link to full code here:

Implementation
Here we begin a hands-on approach, where I explain the concepts on a need-to-know basis (or, as we use them). Also, I’ll try as much as possible to provide intuitive explanations behind concepts and neglect low-level details.
If you need low-level explanations, there are numerous articles online that cover these topics properly and in more depth. Also, you can check out my tutorial on building a neural network from scratch here. Although it’s implemented in Python, the explanations and mathematical concepts around it are written in English, obviously.
Understanding the Data
The dataset we’re working with is a relatively small one. I got it from the UCL dataset repository, and according to the authors:
To make our work more efficient, I’ve downloaded the dataset, label encoded the two categorical features (month and day), split the data into train and test sets, and finally uploaded it to GitHub.
The data will be downloaded over the internet when we need to train our model. I will explain why shortly.
The full description of all data attributes is also available on the dataset page on UCL. From there, we can also see some important characteristics of the data, like whether there are missing values (none in this case), the data types of the attributes, the number of attributes, and so on.

The task is a regression task; that is, we want to predict real-valued numbers. The predicted value is the area of land burned by fire in a particular region, given all other details.
Now that we’ve secured our dataset, let’s set up our application directory and start building.
Setting up your application
Before we start creating directories, it’s important to conceptualize how the application will function. This will help us properly modularize our code in a reusable way.
Since our application is small, it will perform all training in the browser. That means we need a UI that displays intermediate training statistics as well as interactive buttons to perform specified functions.
Next, we’ll need data ingestion functionality. This will retrieve the data from a specified source (local or over the internet), and make it available to the model.
Next, we’ll need to perform data transformations and other miscellaneous tasks. This can be packaged into another utils or misc script to keep our code clean.
Below is the directory structure I’ll be using.
├── index.html
├── index.js
├── data.js
├── utils.js
├── ui.js
├── package.json
Let’s understand what each file represents:
- index.html: This is the home page of our app, and it will hold our HTML UI elements, including buttons and divs to display charts.
- index.js: This is the base JavaScript file. It will contain code to define and train the neural network.
- data.js: As the name implies, it will performing data ingesting over the internet, and convert the data from CSV format to Javascript arrays.
- utils.js: This will hold any extra functions we need to properly prepare our data and model.
- ui.js: This file will handle everything relating to updating the UI interface during and after training.
- package.json: This fileis used by our package manager (npm or yarn). It holds the details about the application, including the name, author, package dependencies, and so on.
Now, go ahead and create a package directory that will hold all your files. I called mine forestfire. We’ll go through all the files individually, and I’ll explain each block of code.
Tell me about your application (package.json)
Create a package.json file, copy the code below, and if you want to, edit the name and description section.
{
"name": "forest-fire-predictor",
"version": "0.0.1",
"description": "A simple Neural Network to predict burnt forest area",
"main": "index.js",
"engines": {
"node": ">=8.9.0"
},
"dependencies": {
"@tensorflow/tfjs": "^1.3.2",
"@tensorflow/tfjs-vis": "^1.0.3",
"papaparse": "^4.5.0"
},
"scripts": {
"watch": "cross-env NODE_ENV=development parcel index.html --no-hmr --open"
},
"devDependencies": {
"@babel/core": "^7.0.0-0",
"@babel/plugin-transform-runtime": "^7.9.6",
"babel-polyfill": "^6.0.16",
"babel-preset-env": "^1.7.0",
"babel-preset-es2015": "^6.0.15",
"babel-preset-stage-0": "^6.0.15",
"cross-env": "^5.1.6",
"parcel-bundler": "^1.12.4"
}
}
The package.json file is used by our package manager to understand what our application needs in terms of external packages, the name and description of our application, and scripts we can run to build the application. This is similar to the requirements.txt file in Python.
- The dependencies section holds three important packages we’ll be using. TensorFlow.js, a visualization tool from the creators of TensorFlow, and PapaParse, a package for reading and loading CSV files.
- The scripts section maps the term watch to a set of commands. What this basically does is create a new private environment for our application, set the environmental variable to development, parse the index.html file, build it, and continuously monitor the package for changes.
- The devDependencies are extra packages that help convert our code to pre-ES6 format. This ensures backwards compatibility of JavaScript in current and older browsers or environments.
Show me your face (Index.html)
Next, let’s build the frontend of our application. We’ll keep things simple but good looking.
Forest Fire Prediction
Forest Fire Area Prediction Using a Neural Network
The index.html file contains two major divs. The first is inside the col-md-5 class and holds two text tags that will be updated during app initialization and model training, and a button that starts model training.
The second div with an id of chart will hold the training and validation loss curves during training.
Every other tag is a basic HTML tag for initializing bootstrap (a little styling, right!) and also, we add the source to our start script (index.js)
Let’s get our data (data.js)
Now let’s get down to business. Create a data.js script and copy the code below:
const PAPA = require('papaparse');
const BASE_PATH = "https://raw.githubusercontent.com/risenW/tfjs-data/master/forestfire/";
const TRAIN_DATA = "forestfire_train.csv";
const TEST_DATA = "forestfire_test.csv";
const TRAIN_TARGET = "forestfire_train_target.csv";
const TEST_TARGET = "forestfire_test_target.csv";
export const FEATURE_NAMES = ['X','Y','month','day','FFMC','DMC','DC','ISI','temp','RH','wind','rain']
/**
* Parse the CSV Object into an array of array of numbers
*/
const convert_to_array = async (csv_file) => {
return new Promise(resolve=>{
let data = csv_file.map((row)=>{
return Object.keys(row).map(key=> row[key])
});
resolve(data)
})
}
/**
* Reads the dataset from the specified path
*/
export const read_csv = async (csv_file) => {
return new Promise(resolve => {
const file_path = `${BASE_PATH}${csv_file}`;
console.log(`Loading from ${file_path}`);
PAPA.parse(file_path, {
download: true,
header: true,
dynamicTyping: true,
complete: (results) => {
resolve(convert_to_array(results['data']));
}
})
})
}
/**
* Helper class for loading train and test data
*/
export class ForestDataset {
constructor(){
this.Xtrain = null;
this.Xtest = null;
this.ytrain = null;
this.ytest = null;
}
get dataShape(){
return this.Xtrain[0].length;
}
async loadAllData(){
this.Xtrain = await read_csv(TRAIN_DATA)
this.Xtest = await read_csv(TEST_DATA)
this.ytrain = await read_csv(TRAIN_TARGET)
this.ytest = await read_csv(TEST_TARGET)
}
}- The first part of the code does some variable initialization. We require the PapaParse libraries for downloading our CSV data over the internet. Next, we set the base path to the dataset (remember, it’s hosted on GitHub), and we set the names of the train and test sets with their corresponding targets, as saved on the GitHub repo.
- Next, we create an asynchronous function convert_to_array. This function takes the object (parsed CSV) from PapaParse and converts it into an array of arrays. This is will be converted to tensors before we start training.
- Next, we create a function read_csv that accepts a CSV file name, download it from the internet, and call the convert_to_array function for each of them. This is where we use the PapaParse library. Note that we set the header to true because our data has headers. We also set dynamicTyping. This instructs Papa{arse to automatically convert each feature to its correct data type.
- Finally, and most importantly, we wrap everything in a simple class called ForestDataset. This class loads each dataset over the internet asynchronously and sets the train and test set properties.
Let’s make it speak (ui.js)
Now let’s prepare a function to help update the UI during initialization and training.
import { CreateNeuralNetwork, train } from '.'
const status_bar = document.getElementById("status_bar");
const training_bar = document.getElementById("training_bar");
export function updateStatus(msg) {
status_bar.innerHTML = msg
}
export function updateFinalResult(curr_epoch, EPOCHs) {
let msg = `EPOCH: ${curr_epoch + 1} of ${EPOCHs} completed...`
training_bar.innerHTML = msg
}
export function updateTrainingStatus(train_loss, val_loss, test_loss) {
let msg = `Final Training Loss: ${train_loss.toFixed(4)}
Final Validation Loss: ${val_loss.toFixed(4)}
Final Test Loss: ${test_loss? test_loss.toFixed(4): '...'}
` //check if loss is undefined
training_bar.innerHTML = msg
}
export async function setUp() {
const trainModel = document.getElementById('trainModel')
trainModel.addEventListener('click', async () => {
const model = CreateNeuralNetwork();
await train(model);
}, false)
}
The first line imports two functions that initializes and trains our neural network. We’ll create these functions in the index.js module shortly. But first, let’s understand the other aspects of the code.
- The first function updateStatus simply updates the status bar in the UI with any message passed to it. This is called during data downloads and model initialization.
- The second function updateFinalResult is similar to updataStatus. It accepts the current epoch number and the total epoch and displays training progress.
- The third function updateTrainingStatus simply displays the train, validation, and test set loss values. This is called after model training and testing.
- Finally, the setUp function is used to create the neural network and start model training. This function will be linked to the train button in the index.js file as soon as the application is loaded.
Now the main point (index.js)
The index.js is the main entry point of our application. It is also the specified entry point for our app in the package.json file. This means when we run our app, this will be the first script executed. Let’s take a look at the code below:
import * as tf from '@tensorflow/tfjs';
import * as tfvis from '@tensorflow/tfjs-vis';
import { ForestDataset, FEATURE_NAMES } from './data';
import { normalizeData } from './utils'
import * as ui from './ui';
const forestdata = new ForestDataset();
const tensors = {}
const LEARNING_RATE = 0.01
const EPOCHS = 100
const BATCH_SIZE = 32
/**
* Convert Array of Arrays to Tensors, and normalize the features
*/
export function arrayToTensor() {
tensors['Xtrain_tf'] = normalizeData(tf.tensor2d(forestdata.Xtrain))
tensors['Xtest_tf'] = normalizeData(tf.tensor2d(forestdata.Xtest))
tensors['ytrain_tf'] = normalizeData(tf.tensor2d(forestdata.ytrain))
tensors['ytest_tf'] = normalizeData(tf.tensor2d(forestdata.ytest))
}
export function CreateNeuralNetwork(){
const model = tf.sequential();
model.add(tf.layers.dense({
inputShape: [forestdata.dataShape],
units: 20,
activation: 'relu',
kernelInitializer: 'leCunNormal'
}));
model.add(tf.layers.dense({
units: 10, activation:'relu', kernelInitializer: 'leCunNormal'}));
model.add(tf.layers.dense({units: 1}))
model.summary();
return model;
}
/**
* Trains the neural Network and prints the result
*/
export async function train(model){
let trainingLogs = [];
let chartbox = document.getElementById('chart')
model.compile({
optimizer: tf.train.sgd(LEARNING_RATE),
loss: 'meanSquaredError'
});
ui.updateStatus("Training started....")
await model.fit(tensors.Xtrain_tf, tensors.ytrain_tf,{
batchSize: BATCH_SIZE,
epochs: EPOCHS,
validationSplit: 0.2,
callbacks:{
onEpochEnd: async(curr_epoch, logs)=>{
await ui.updateTrainingStatus(curr_epoch, EPOCHS)
trainingLogs.push(logs);
//plot the training chart
tfvis.show.history(chartbox, trainingLogs, ['loss', 'val_loss'])
}
}
});
ui.updateStatus("Evaluating model on test data")
const result = model.evaluate(tensors.Xtest_tf, tensors.ytest_tf, {
batchSize: BATCH_SIZE,
});
const test_loss = result.dataSync()[0];
const train_loss = trainingLogs[trainingLogs.length - 1].loss;
const val_loss = trainingLogs[trainingLogs.length - 1].val_loss;
await ui.updateTrainingStatus(train_loss, val_loss, test_loss)
};
//Download and convert data to tensor as soon as the page is loaded
document.addEventListener('DOMContentLoaded', async () => {
ui.updateStatus("Loading Data set and Converting to Tensors....")
await forestdata.loadAllData()
arrayToTensor();
ui.updateStatus("Data Loaded Successfully....")
document.getElementById('trainModel').style.display = 'block'
// tf.print(tensors.Xtrain_tf)
await ui.setUp()
}, false);
- Since this is the main entry point of our application, we import and require all other modules and packages. Notably, we import TensorFlow.js and the TensorFlow visualization tool.
- Notice the normalizeData import? It’s imported from the utils.js module, which we’ll create shortly. It’s used to normalize the dataset to range between 0 and 1. This helps our neural network train well.
- Next, we initialize a new dataset class from ForestDataset, a new tensor object to hold our dataset that’s been converted to tensors, and then we initialize the learning rate, number of epochs, and batch size.
- Next, we write the function arrayToTensor. This function converts each dataset (data and target) into 2D tensors. This is important, as TensorFlow models can only work with tensors and not JavaScript arrays. The new tensors are then passed to the normalize function, and finally, are saved to the tensors object we initialized earlier.
- Next, we create our neural network. Here we create a 3-layer network with two hidden layers. The TensorFlow.js API for creating a neural network is very similar to the Keras Python API. So if you have familiarity with that API, you can easily understand what’s going on here. To be more explicit, we:
- The next function we create is called train. This function compiles the model, trains it, and calls the function to update the UI. Let’s understand what this function does:
- The final code block simply sets an event listener for when the index.html page is loaded. This calls the function to download and convert the dataset to tensors. Then the train button is then made visible for the user to start training.
Clean-up functions (utils.js)
The last and smallest module in this application is the utils.js file. This file holds all the code to help pre-process the dataset. Also, all helper functions can be added here. In this application, we have just one function, the min-max normalization function. Below is the formula for the min-max normalization:
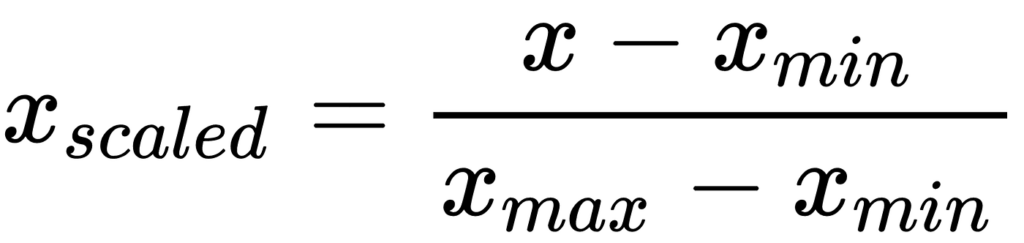
This min-max normalization function compresses values passed to it to a range between 0 and 1. This has numerous advantages in deep learning such as faster training time and better weight updates during backpropagation.
Now, let’s put this in code. Below, we create a function normalizeData that turns this formula into Tensorflow code.
/**
* Normalize data set using min-max scaling
*/
export function normalizeData(tensor){
const data_max = tensor.max();
const data_min = tensor.min();
const normalized_tensor = tensor.sub(data_min).div(data_max.sub(data_min));
return normalized_tensor;
}First we calculate the maximum and minimum values, then we subtract the calculated minimum from every element in the tensor, and then divide by the result of the minimum value subtracted from the maximum.
Building and running the application
Now that we have all our files and scripts, let’s build our application and see it in action. I’ll be using yarn package manager. Feel free to use anyone you’re comfortable with. Complete the steps below to run the application.
- Open a terminal in your application’s root directory, and run the following command to build your application.
This builds your application by downloading all the relevant dependencies and automatically opens your browser with the index.html page loaded.

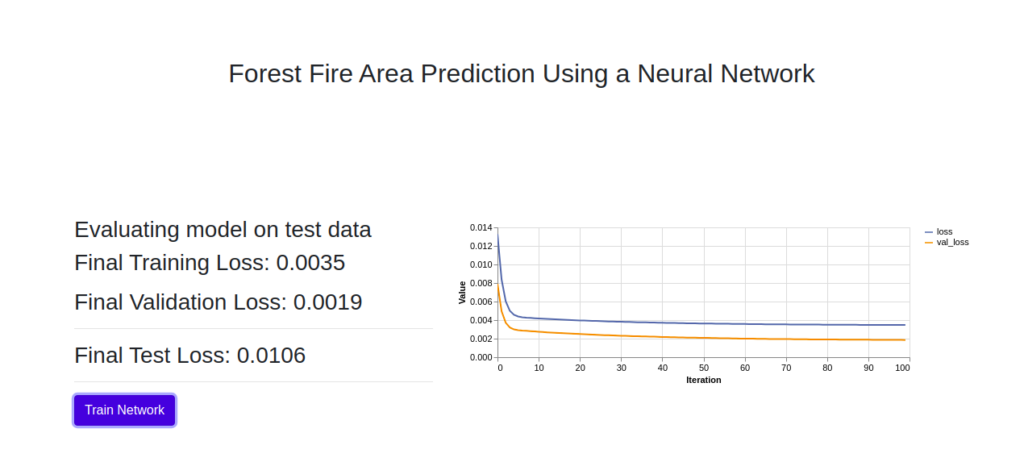
Next, click the train network button to start training. This starts the network training and updates the training and validation loss at the end of every epoch.
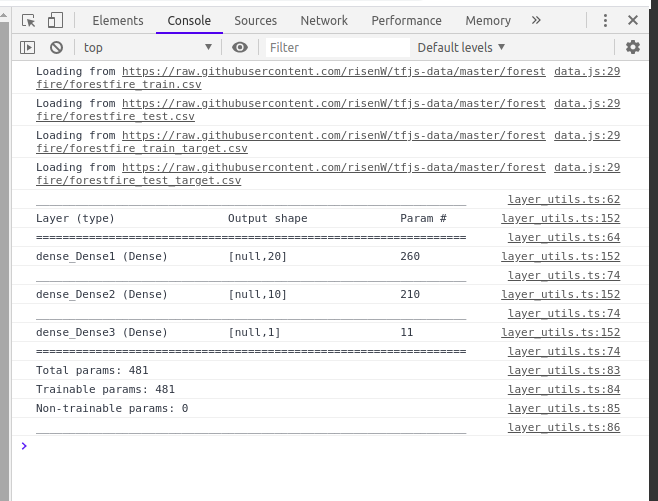
If you open your browser console (CTRL + SHIFT + I) in Chrome before you start training, you will find the model summary, containing the model architecture and trainable parameters.
Also, your loss might be slightly different from mine. This is due to some randomness, especially in weight initialization.
And that’s it! You have successfully trained a neural network on your browser to predict forest fire area using TensorFlow.js. Everything happened on the client-side, and I’m sure you’ve begun to see the power and numerous possibilities of deep learning with JavaScript!
I’ll leave you with a little exercise. Create an input to accept the features in the frontend, convert these features to tensors, and make predictions on them. Do share links to your improvements—I’d love to see what you build.
In my next post for this series, we’ll build a multi-class, image classification model to predict handwritten digits, drawn on a canvas, in the browser.
If you have any questions, suggestions, or feedback, don’t hesitate to use the comment section below. Stay safe for now, and keep learning!

Connect with me on Twitter.
Connect with me on LinkedIn.
Comments 0 Responses