
Advancements in the power of machine learning have brought with them major data privacy concerns. This is especially true when it comes to training machine learning models with data obtained from the interaction of users with devices such as smartphones.
So the big question is, how do we train and improve these on-device machine learning models without sharing personally-identifiable data? That is the question that we’ll seek to answer in this look at a technique known as federated learning.
Centralized Machine Learning
The traditional process for training a machine learning model involves uploading data to a server and using that to train models. This way of training works just fine as long as the privacy of the data is not a concern.
However, when it comes to training machine learning models where personally identifiable data is involved (on-device, or in industries with particularly sensitive data like healthcare), this approach becomes unsuitable.
Training models on a centralized server also means that you need enormous amounts of storage space, as well as world-class security to avoid data breaches. But imagine if you were able to train your models with data that’s locally stored on a user’s device…
Machine Learning on Decentralized Data
Enter: Federated learning.
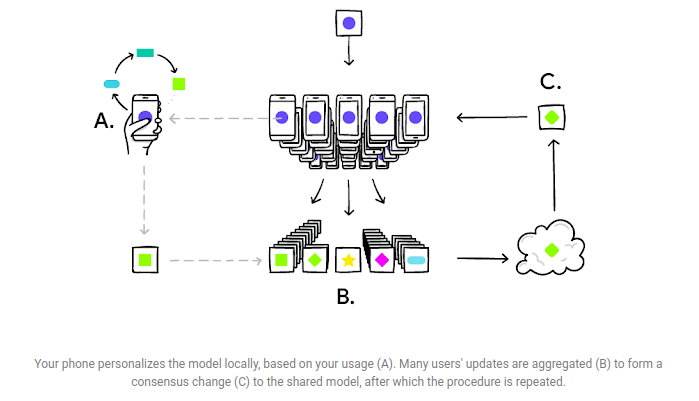
Federated learning is a model training technique that enables devices to learn collaboratively from a shared model. The shared model is first trained on a server using proxy data. Each device then downloads the model and improves it using data — federated data — from the device.
The device trains the model with the locally available data. The changes made to the model are summarized as an update that is then sent to the cloud. The training data and individual updates remain on the device. In order to ensure faster uploads of theses updates, the model is compressed using random rotations and quantization. When the devices send their specific models to the server, the models are averaged to obtain a single combined model. This is done for several iterations until a high-quality model is obtained.
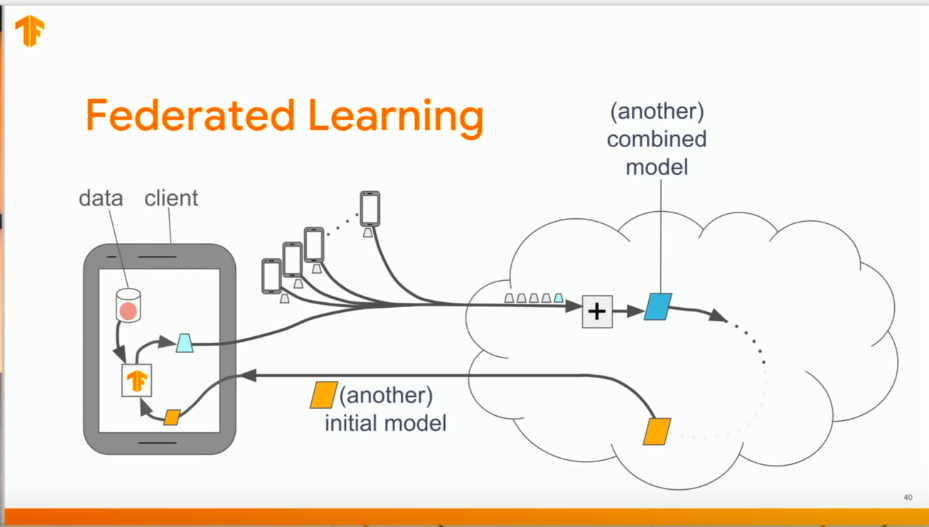
Compared to centralized machine learning, federated learning has a couple of specific advantages:
- Ensuring privacy, since the data remains on the user’s device.
- Lower latency, because the updated model can be used to make predictions on the user’s device.
- Smarter models, given the collaborative training process.
- Less power consumption, as models are trained on a user’s device.
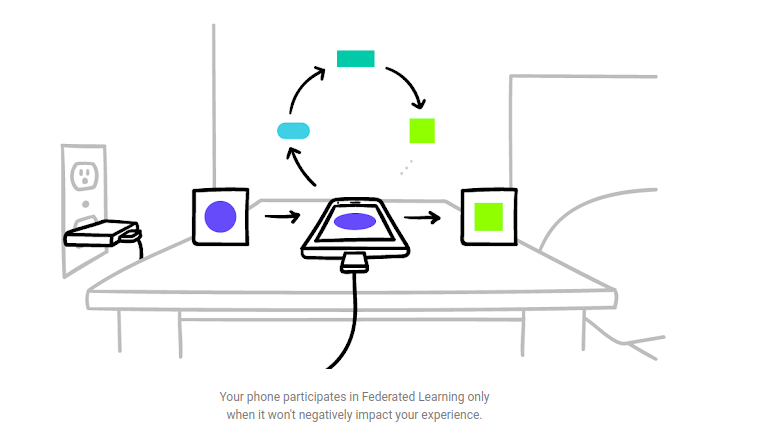
In order to ensure that an application’s user experience is not hampered, the model training happens when the user’s device is on free WiFi, is idle, and connected to a power supply.
TensorFlow Federated
TensorFlow enables the application of federated learning by leveraging its own framework.
TFF has two layers: the Federated Learning (FL) API and the Federated Core (FC) API. The Federated Learning (FL) API allows developers to apply federated training and evaluation to existing TensorFlow models.
The Federated Core (FC) API is the core foundation for federated learning. It is a system of low-level interfaces for writing federated algorithms in combination with distributed communication operations in strongly-typed functional programming environments.
An example application of federated learning is in Google’s Gboard keyboard.
In this case, a recurrent neural network language model is trained using decentralized on-device datasets. Its aim is to predict the next word on smartphone keyboards.
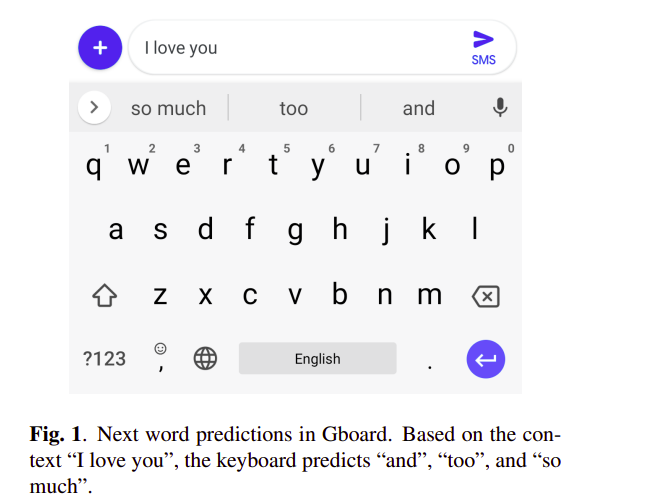
Training the model on client devices using the federated averaging algorithm is shown to perform better than server-based training using stochastic gradient descent. The algorithm is used on the server to combine updates from the clients and produce a new global model.
In this case, the use of federated learning led to a 24% increase in next-word prediction accuracy. Other improvements to the Gboard experience resulting from this are enhanced emoji and GIF predictions. This means that users are now seeing more relevant emojis and GIFs when using Gboard.
I hope this activates your interest in federated learning and its potential to drive a new wave of on-device training, application personalization, and increased data privacy.
Comments 0 Responses