
This is part 3 of an ongoing series on language models, starting with defining neural machine translation and exploring the transformer model architecture, and then implementing GPT-2 from scratch.
Specifically, in the first part of the series, we implemented a transformer model from scratch, talked about language models in general, and also created a Neural Machine Translator.
And in the second part, we implemented GPT-2, starting with the transformer model code from the part 1. And we also learned how to actually generate text using the GPT-2 model.
In part 3, we’ll be creating a language model using Hugging Face’s pre-trained GPT-2.
Since we’ve discussed what GPT-2 is, and since we’ve explored the model structure and attributes in part 2, I won’t be discussing this again—if you need a refresher on what GPT-2 is all about, check out part 2!
Goals:
- Create an end-to-end approach to generate text using fine-tuned GPT-2 from Hugging Face.
In this section of this series, I’ll try to go straight to the point as much as possible.
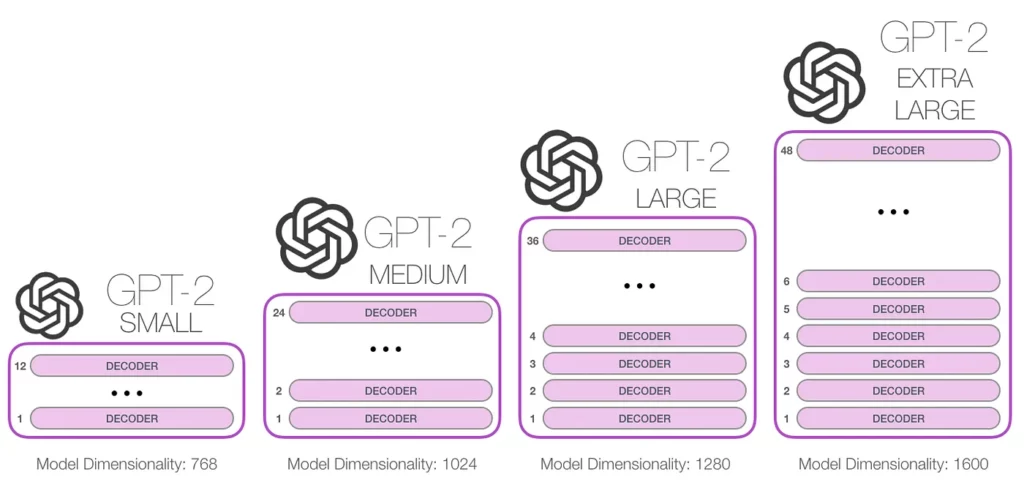
Hugging Face has a few different versions of GPT-2 based on their model size, each with an approximate size in millions of parameters.
We’ll be using the smallest GPT-2 called GPT-2 Small since we don’t have the required hardware to run the bigger model (for demo purposes, I assume you’ll be using Google Colab to train your model).
First, install the Hugging Face Transformers library:
Once the Transformers package is installed, we’re good to initialize our model:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
device = 'cpu'
if torch.cuda.is_available(): #check if GPU device is available
device = 'cuda' # assign the gpu to the device
tokenizer = GPT2Tokenizer.from_pretrained('gpt2') # initialize the gpt2-tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2') # initialize the gpt2-small
model = model.to(device) # bind the model to the GPU device
From the code above:
- First, we check if GPU is available
- Download and initialize the pre-trained gpt2 tokenizer
- Download and initialize the pre-trained gpt2-small model
- And then we bind the model to the GPU device
Without training, we can start generating text.
Lucky for us, we don’t have to write the code to generate the text for us— different types of text decoders come ready to use with the model.
In parts 1 and 2, we’ve been using greedy decoders, but now we have access to different types of decoders, such as:
- Top-k decoder
- Beam search
To learn more about different types of decoders used to generate text, check out the article below:
Let’s try to generate some text with the pre-trained model:
tokens = tokenizer.encode("the fabric of the universe", return_tensors='pt')
tokenizer.decode(model.generate(tokens.cuda(), do_sample=True,
max_length=100,
top_k=50)[0],skip_special_tokens=True)In the code above:
- First, we tokenizes the text, using the pre-trained gpt-2 tokenizer.
- Set the return_tensors argument to pt, which is used to notify the tokenizer to generate a PyTorch tensor. And to generate a TensorFlow tensor, we make use of tf.
- The generated token is passed into the tokenizer.decode method alongside the model. But first, we bind the token tensor to the GPU using tokens.cuda()
- We also set the maximum length of text to generate, using the top 50 next words.
For the model, I provided the input text below.
and then received the following model output:
Fine-tuning our model
The pre-trained model is really good on its own, but maybe we’d like to tune it a bit to fit our own tastes.
Based on your choice, you can use it to generate lyrics, jokes, news, etc. All you need is to work with your desired dataset in order to fine-tune the model.
Using any dataset of your choice, it’s a good practice save as a text file—hence the text file can be read as:
With the data (list of texts), we will create a PyTorch custom data class, which will be infused with the data loader:
#inspired by
#https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_language_modeling.py
#https://gist.github.com/cdpierse/3ad19852efa7324cc16f4d83b9191176#file-script_dataset-py
class Data(Dataset):
def __init__(self, tokenizer, df, block_size=512):
block_size = block_size - (
tokenizer.max_len - tokenizer.max_len_single_sentence
)
tokenized_text = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(df))
self.examples = []
for i in range(0, len(tokenized_text) - block_size +1, block_size):
self.examples.append(
tokenized_text[i : i + block_size] + [tokenizer.eos_token_id]
)
def __len__(self):
return len(self.examples)
def __getitem__(self, item):
return torch.tensor(self.examples[item], dtype=torch.long)Remember that in the previous part, we made mention of GPT-2 taking a maximum token size of 1024. In order to prevent exceeding this size, we’ll split our text into blocks.
We use a block size of 512—that means the maximum number of each token will be 512. Hence, if a token exceeds 512, it will be cut off at 512 and the remaining token will be a set of new tokens.
valid = Data(tokenizer," ".join(data[:800]))
train = Data(tokenizer," ".join(data[800:]))
batch_size = 1
train_loader= DataLoader(train,shuffle=False,batch_size=batch_size,)
valid_loader =DataLoader(valid,shuffle=False,batch_size=batch_size,)To make the tokenization easy, we convert the list of text into a complete text using ” “.join(data) .
The list is split into training and validation sets. The data generated is then passed into a data loader.
We make use of a batch size of one, due to how slow the training is. And I still kept running out of memory while training on Google Colab.
Now that the data loader is set, let’s prepare the model for training:
epochs = 10
learning_rate = 0.0002
warmup_steps = 2000
optimizer = AdamW(model.parameters(), lr=learning_rate)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=-1)
After setting the optimizer, we’re good to train:
model.train()
for epoch in range(epochs):
print(f"Epoch {epoch} started")
sum_loss = 0
val_loss = 0
model.train()
for data in train_loader:
output = model(data.cuda(), labels= data.cuda())
loss, logits = output[:2]
loss.backward()
sum_loss += loss.item()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# model.eval()
# for data in valid_loader:
# output = model(data.cuda(), labels= data.cuda())
# loss, logits = output[:2]
# val_loss += loss.item()
print(f"training loss { sum_loss / len(train_loader)}")
The validation method in the training is commented out, since it’s taking too long to train the model.
Now that the model is fine-tuned to your taste, you can test it out by using the same decoder method, like this:
tokens = tokenizer.encode("the fabric of the universe", return_tensors='pt')
tokenizer.decode(model.generate(tokens.cuda(), do_sample=True,
max_length=100,
top_k=50)[0],skip_special_tokens=True)Conclusion
In this tutorial, we’ve been able to create a prototype that can work for any document you have.
Comments 0 Responses