
If our data isn’t good enough, there’s no machine learning tool, platform, or framework that exists that will work well—no matter how good the algorithm is.
So while debugging machine learning models, we also need to make sure our input data is prepared properly. For example the input data may not be a valid data type for a particular feature. Like in case of gender the allowed values are M or F, while the input data may contain other letter values for this feature.
For this, we can employ the following three methods:
- Validate our input data
- Test our input data
- Ensure our data is split properly
If we carry out the above three checks, we can ensure, to a large extent, that we’re good with our input data, at least from a debugging perspective.
1. Validate input data

When thinking about validating input data, we can write certain rules called schema that the input data must satisfy.
CSV File Validation
Invalid CSV files can create issues while building data pipelines. CSV Validator is a CSV validation and reporting tool that implements CSV Schema Language. csvlint.com is a service that checks CSV files against user-defined validation rules cell-by-cell.
JSON Schema
JSON schema is a JSON validation tool for representing the structure of data in a JSON document. It’s a quite powerful and effective (and simple) type of data validation.

TensorFlow Data Validation
TensorFlow Data Validation (TFDV) can analyze training and serving data to infer a schema and detect data anomalies.
2. Test input data

Even though our input data can be validated using the schema and tools above, we also need to do some engineering on our input data before feeding it to our machine learning model.
For example, the input data may be in GBP or another currency, while we want all data to be in USD while only allowing the value to be more than one USD. Since engineered data is different than input data, we need to check our engineered data as well. One of the ways to check engineered data is by using unit tests.
We need to write unit tests to discover bugs. For example, there might be a bug in data scaling code that’s returning null. These bugs are related to code that we write for the data pre-processing steps of our machine learning pipeline.
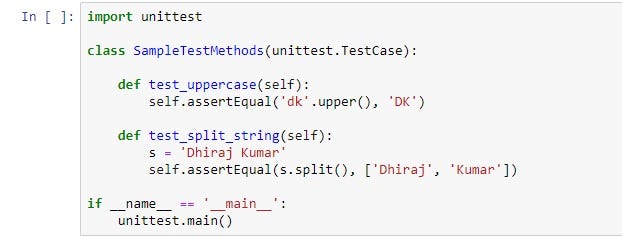
Python has its unittest unit testing framework, which may help you in this case.
3. Ensure data is properly split

For training and testing, we need to split out data into two sets, where our training set generally represents 75% of the all the data, and the test set includes around 25%. While splitting the data into train and test sets, we must ensure that both parts after the split are equally representative of the complete dataset.
The key concept to note here is that if the test and training datasets aren’t the same statistically, the model’s predictions in real-world settings will not be accurate. In other words, we need to verify that the ratio of data points in each split stays constant, and each split should represent a true subset of data from a statistical point of view.
There is a library in sklearn called train_test_split that may help you in this case.
Concluding Thoughts
The quality of data largely controls a machine learning model’s performance. While debugging a machine learning model, we must ensure that we have checked for the possibility of low-quality data using the above methods and tools.
Happy machine learning 🙂
Comments 0 Responses