
Over the years, many activation functions have been introduced by various machine learning researchers. And with so many different activation functions to choose from, aspiring machine learning practitioners might not be able to see the forest for the trees. Although this range of options allows practitioners to train more accurate networks, it also makes it harder to know which one to use.
In this post, I’ll demonstrate a little research project I did to see how each of the activation functions performs on the MNIST dataset. I’ll start by providing a quick overview of the theory behind each function. If you already know what activation functions are, feel free to skip to the last section to see the benchmarks.
What even is an activation function?
In the most abstract sense, a neural network is built of multiple tensor multiplications. But if these multiplications only consisted of addition and multiplication, they would be linear systems, meaning they couldn’t represent any nonlinear function. In other words: the whole network could be replaced by a single matrix multiplication (or layer for that matter).
To solve this problem, neural networks use so-called activation functions. These functions introduce nonlinearities into the networks, making deep neural networks possible.
In the last couple of years, many activation functions have been introduced. Below are the most popular choices.
Some popular activation functions
ReLU (and softmax)
A rectified linear unit, or ReLU, is a very simple activation function. It returns 0 when the input is smaller than 0, or the value if it’s greater than or equal to 0. In a formula:
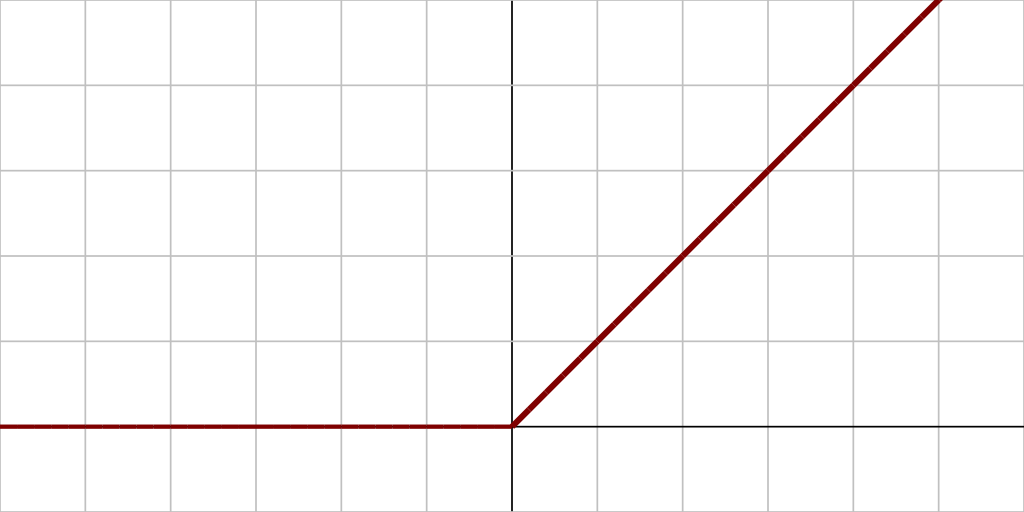
Almost every neural networks outputs values between 0 and 1 — the probability of an input belonging to some class. Since ReLUs allow values far greater than 0, the values need to be scaled.
The way this is usually done is by applying the softmax activation function. Mathematically, it’s defined as
with k as the number of inputs.
This function might seem complex, but the idea is quite simple. Basically, softmax scales the output to range 0 to 1, with all the numbers adding up to 1. This is reasonable because it means the neural network is 100% certain that the input image one of the output categories (note that if there are images in a dataset without a label, they should be labeled as ‘unclassified’ or ‘other’).
Another thing softmax does is scale the numbers based on the input value. The scaled value of the output node with the highest value will be much higher than the node with the second highest output.
ReLU activation functions are a very popular choice among deep learning practitioners because they are very cheap to compute.
Sigmoid
Sigmoid is another one of the classic activation functions. The sigmoid function is 0.5 at the y-axis and has two asymptotes at 0 and 1.
The mathematical formula is

Tanh
Tanh is very similar to sigmoid. The key difference is that tanh has asymptotes at -1 and 1 instead of 0 and 1.

Since the value of tanh can be smaller than 0, it is recommended to use a softmax function in the output layer.
elu
elu stands for exponential linear unit. This unit is similar to both ReLU and tanh. For x<0, it looks like tanh, and for x>1 it’s more similar to ReLUs.

Like tanh, an elu can output values lower than 0, so for tanh, it’s recommended to use softmax in the output layer as well.
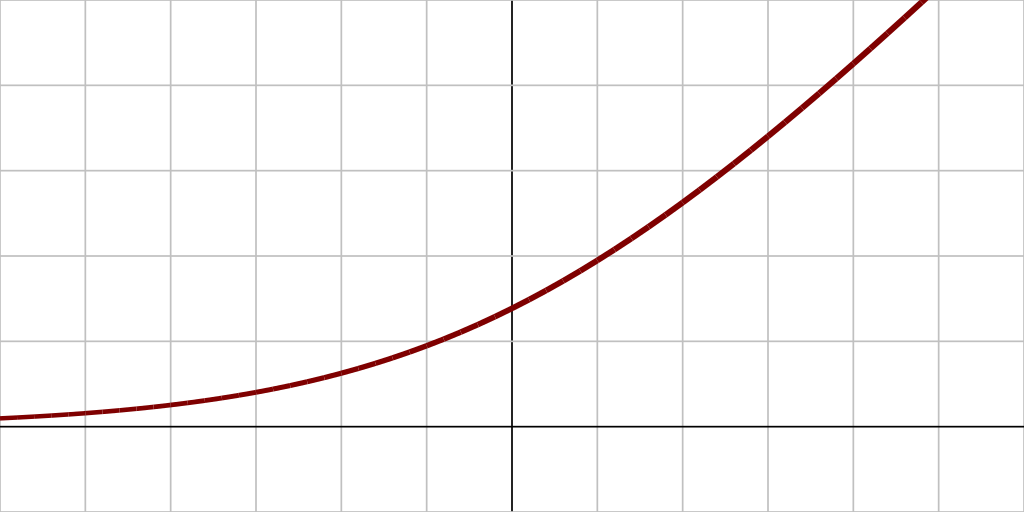
softplus
Softplus is similar to elu, but it’s value is always greater than 0.
Some benchmarks
If some of the above sounds abstract to you, don’t worry — mathematics is abstract by design. Let’s put it into perspective and see how activation functions and optimizers perform in a real world application.
The following graphs show the training phase of a 3-layer neural network trained for 10 epochs on MNIST with an Adam optimizer. The hidden layer has 150 neurons. The first activation function was used in the input and hidden layer. The second activation function was used in the last layer.
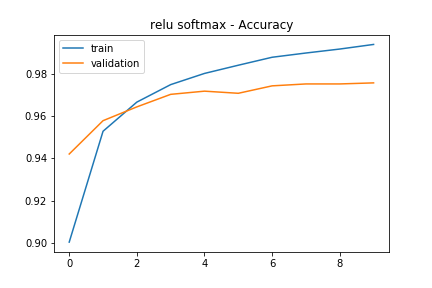
ReLU-softmax
The ReLU-softmax network had a final training accuracy of 99.56% and a validation accuracy of 97.56%. The training accuracy being higher than the validation accuracy indicates an overfit network. As you can see, continuing training after the third epoch didn’t make the model more accurate.
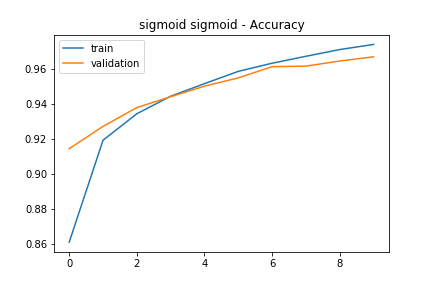
sigmoid-sigmoid
The sigmoid-sigmoid network had a final training accuracy of 97.78% and a validation accuracy of 96.76%. The train/validation accuracy is particularly good for this network, even though the accuracy is slightly lower than the ReLU-softmax network.
tanh-softmax
The tanh-softmax network had a final training accuracy of 99.29% and a validation accuracy of 97.3%. This model was also overfit a little, but less than the ReLU-softmax model.
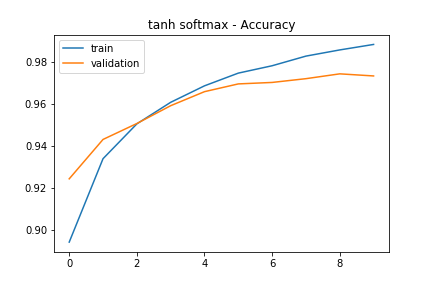
elu-softmax
The elu-softmax network had a final training accuracy of 99.00% and a validation accuracy of 97.43%. The history graph is surprisingly similar to the tanh-softmax training history.

softplus-softplus
The elu-softmax network had a final train accuracy of 98.38% and a validation accuracy of 97.02%.

Conclusion
Judging by the final results, a ReLU-softmax network is the best option when training a neural network. However, it should be noted that this is solely the case for this particular network on MNIST — the result will differ on different networks, datasets, and tasks. The fact that the ReLU function is the easiest to compute won’t change, however.
Comments 0 Responses