
This is the fifth blog post in my AutoML Vision Edge series. The post will help you run AutoML Edge models on Docker containers. If you haven’t been following this blog post series till now, here’s a quick recap:
We started the series by learning how we can train and run inference on an edge-ready ML model in hours using Google Cloud’s AutoML.
In the first post, we used the .tflite format provided by AutoML to run inference on-device:
In the second post, we used Python to run inference on the TF SavedModel format, available to us as .pb file:
In the third post, we used the tf.js format to load and run the model directly in the browser:
In the fourth and most recent post, we covered how to use the Tf.js model format on the server instead of in the browser.
Before running AutoML models on containers, we should learn about containers and the problems they can solve.
Containers
With containers, we can package our applications and their dependencies together into one succinct manifest. That means we can package our entire application, abstracting away the operating system, the machine, and the code itself.
As Google says:
Container images become containers at runtime. Docker is one of the tools designed to use containers. It makes it easier to create, deploy, and run our applications.
With Docker containers, we can run our AutoML exported Edge models on any device. After running the container, we can make an API call to the container endpoint to get our ML inference results.
It makes the integration of ML models with our codebase decoupled altogether. Also, we’ll be able to use any language to make the REST API call to the container, which makes this system language-independent.
Setup
- Docker Configuration
The first step is to install Docker on your operating system. You can follow the installation guide here. Once installed, you should start the Docker daemon inside your system.
To test your installation, you can run:
which will output the respective Docker version.
If you get an error (as shown in the screenshot below), it might be possible that the Docker daemon isn’t running in your system. To start the Docker daemon, you can follow the instructions here.

2. Exporting your model
To export your trained AutoML Edge model to the container, use the TF SavedModel format provided by AutoML. As shown in the image below, you need to click the Container icon and export the model into the Cloud Storage bucket.
If you want to learn more about training and exporting models in AutoML, check out the first blog post of this series here.
3. Downloading the AutoML Vision Edge model
To download the model, we need to specify two directories:
- Model_Path: This is the path of the GCP location of your model. For example: gs://my-bucket-vcm/models/edge/ICN4245971651915048908/2020-01-20_01-27-14-064_tf-saved-model/
- Your_Local_Model_Path: The path where the model will be downloaded from the cloud bucket.
For the AutoML container configuration, create a directory:
/tmp/mounted_model/0001/
This directory structure is required, as the container will try to find the model in /tmp/mounted_model/0001 inside our local system.
Set both the environment variables are as follows:
Now, you can download the model into the local path using the following command:
Getting the Docker image to load the model
Before we go into detail, we need to understand, what is a Docker Image?
A Docker Image is a template that contains the application environment, and all the dependencies required to run the application. They can have software pre-installed which speeds up deployment. They are portable, and we can use existing images or build our own.
Here, we’ll be fetching the prebuilt image to run our edge model.
The image will contain everything needed to run our models. First, we’ll set the environment variable (which is the path of the Docker image), and then we’ll get the container.
Running the model on the Docker container
As per the documentation, we need to set up two more environment variables here:
- CONTAINER_NAME: Any string that can identify your container
- PORT: Any free port where we can run the container
Once everything is set up as shown above, you can run:
You’ll be able to see some logs on the terminal, as shown below:
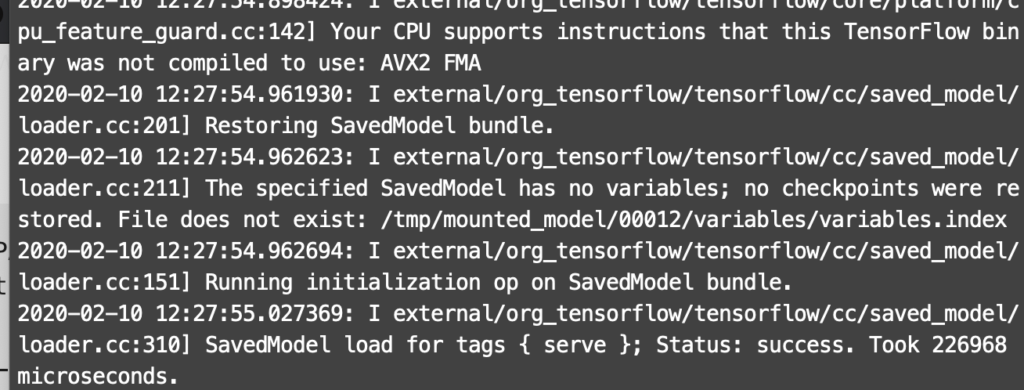
That means everything is fine, we’re all set up, and now we’re ready to run inference on our model.
Running inference
Running inference is the easiest task—it’s language-independent, as the model is served on a PORT. We’ll be sending a POST request with the base64 encoded image in the body to the server to run inference:
Replace your image path under the container_predict function along with a random string. The container_predict function encodes the image in base64 format and sends it as a POST request to http://localhost:{}/v1/models/default:predict’.format(port_number), which is where our docker container is running.
Now you can run this script and can obtain the image classification results from your model in JSON format:
Conclusion
In this post, we have covered a brief introduction of Docker containers, with a primary focus of running edge ML models on them. We’ve seen how we can make our machine learning applications decoupled and language-independent using the AutoML Container Model format.
In the coming posts of this series, we’ll explore the remaining model formats of AutoML Vision Edge, and then compare the formats with their benefits on the basis of performance, storage, training time, and other factors.
If you liked the article, please clap your heart out. Tip — Your 50 claps will make my day!
Want to know more about me? Please check out my website. If you’d like to get updates, follow me on Twitter and Medium. If anything isn’t clear or you want to point out something, please comment down below.
Comments 0 Responses