
Though I support learning machine learning from scratch, I’m always interested in validating the classic Cost + Effort < Output.
Machine learning is interesting conceptually, but at the same time, it’s hard to understand for a beginner. A lot of effort is needed to master and understand the foundational mathematics and logic. But luckily, there are a number of tools available online to decrease these efforts exponentially. One of them is Google Cloud AutoML.
AutoML is a suite of machine learning products that enables developers with limited machine learning expertise to train high-quality models specific to their business needs. In technical terms, it’s a neural net that can design neural nets.
This post will highlight how you can train a custom machine learning model from scratch using Google Cloud AutoML Vision Edge.
1. What are Edge-Based Models?
AutoML Vision Edge allows you to train and deploy low-latency, high accuracy models optimized for edge devices.
After training, the model can be consumed in various formats provided by AutoML, such as TF Lite, Core ML , Tensorflow.js, and other container export formats. This post will cover training and consuming the TF Lite format of the AutoML Edge-based model.
2. Preparing a Dataset and Training Edge-Based Models
2.1 Getting a good dataset
Dataset is the backbone of Machine Learning. Preparing Dataset is a crucial step before Training
There are two ways to get a viable dataset—either use an existing one from the internet (i.e good for general use cases) or create our own dataset for a specific use case.
For this, I’ve written a simple script that will help to scrape images from the website Pexels, which has 1000s of free, high-quality stock photos.
A simple use case to experiment with AutoML would be a basic image classification problem: recognizing dogs vs cats. A lot of images of cats and dogs are available on the internet or can be scraped easily from various websites (such as Pexels).
2.2 Problem: Classifying photos into dogs and cats classes
Step 1: Scrape from Pexels and Create Dataset
By using Pexels, we can extract all the dog and cat images we’ll need. With the aforementioned script, we just need to change the keyword to ‘cat’ and ‘dog’ in spider.py as follows:
And then run the Python script with this command:
The script uses Selenium to lazy load all the images into the browser window before downloading them into the _images folder.
Step 2: Cleaning the dataset
This step is often ignored, but it’s super important in achieving good accuracy. Make sure the dataset has a folder named “dogs” and another named “cats” containing their images respectively.
The directory should look like this:
Step 3: Setting up a Google Cloud Project
Once we’re ready with a clean dataset, we can get started by setting up our Google Cloud project.
We can follow this guide to create a Google Cloud project:
The next step is to create our dataset on the AutoML page. Here, as you can see in the snapshot, we will use single-label classification. Single-label classification is used when an image can belong to a single class. In our, Cat vs Dog problem, every image will be labeled as either as a cat or a dog, i.e a single-class label. In multi-label classification, a single image can belong to multiple classes simultaneously.
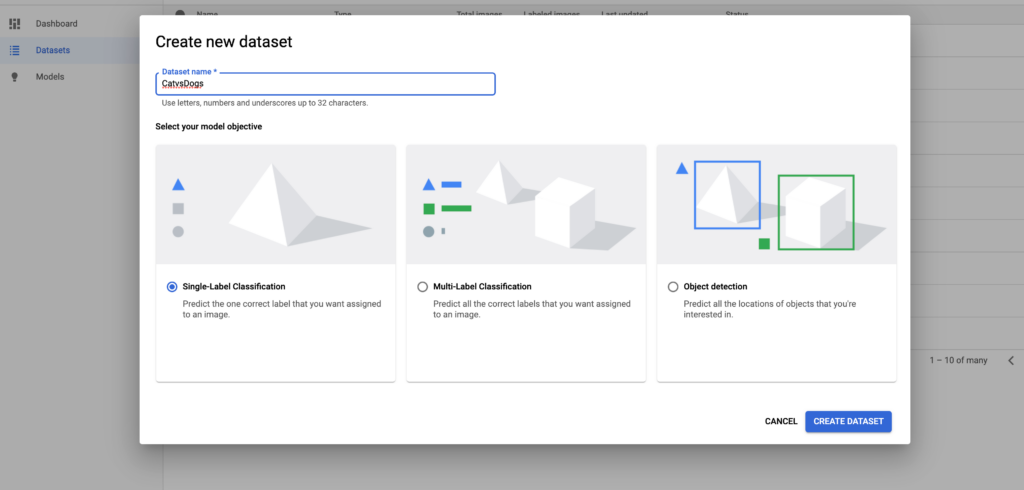
Step 4: Import all the images
After this initial project setup, we’ll use the “Import” button and import the dog and cat folders with their respective images.
After the upload, we can see all the images under the “Images” tab:
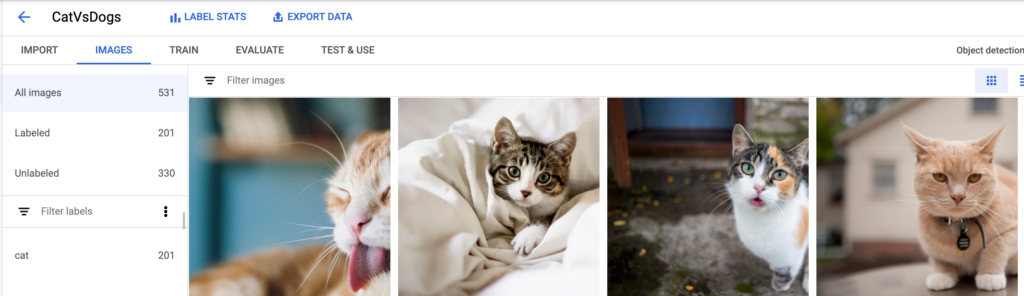
Step 5: Start model training
Once see get cat and dog images reflected in the AutoML dashboard, we can start training our model 😀
Training this model is very easy with AutoML—go to the Train tab and click Train New Model. Once training is completed, we’ll get an email notification.

Before training, you should make a decision about how your model will be consumed—as an API (online prediction) or on an edge device (offline predictions). Online Predictions are the best way to test the results or if you want to consume the model directly through the AutoML API. They are more accurate. Offline models save a lot of costs and can run on-device. They are generally less in size and can run without an internet connection.
Step 6: Evaluate your model
Before the evaluation of the model, we should understand the meanings of both precision and recall. Precision refers to the percentage of your results that are relevant. On the other hand, recall refers to the percentage of the total relevant results correctly classified by your algorithm. You can learn more about precision and recall here
Check out the recall and precision values of our CatVsDog model in the dashboard.
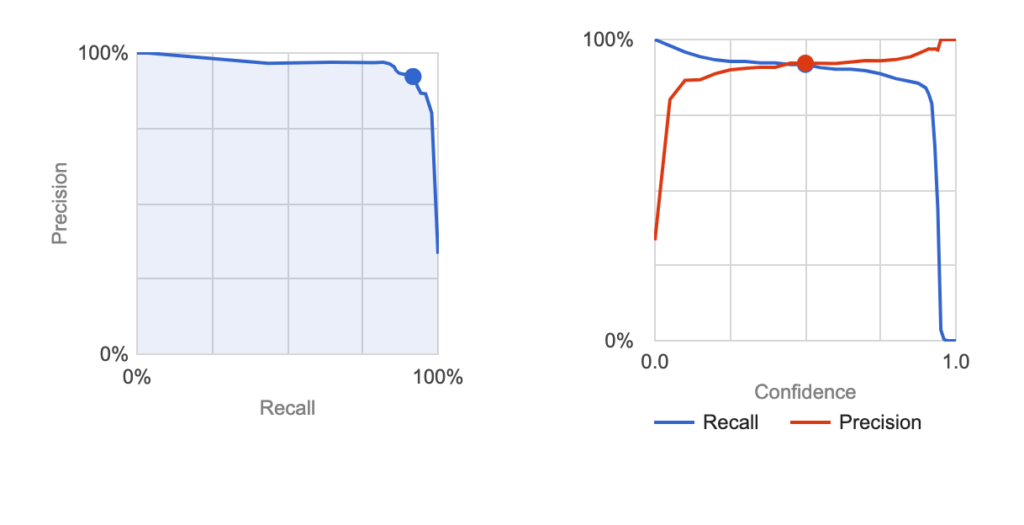
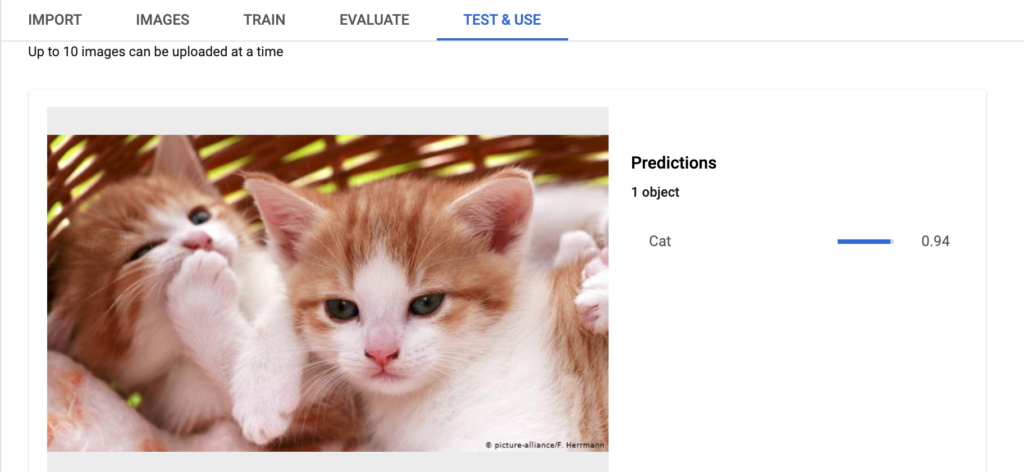
Step 7: Test your Model
The model will be trained anywhere between 1–8 hours, depending on the number of images in the dataset. You can test your images in the Test & Use tab.
AutoML by default splits the dataset randomly into these 3 sets:
- Test Dataset: The data sample used to provide an evaluation of a final model fit on the training dataset. 80% of the images are used for training.
- Training Dataset: The sample of data used to train the model. 10% of images are used for hyperparameter tuning and/or to decide when to stop training.
- Validation Dataset: The data sample used to provide an evaluation of a model fit on the training dataset while tuning model hyperparameters. 10% of images are used for evaluating the model. These images are not used in training.
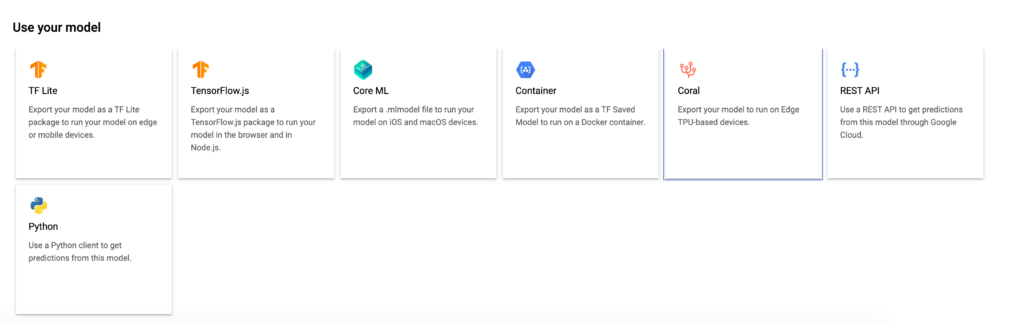
3. Using the TensorFlow Lite (.tflite) model offline
If we want to use the model offline—whether on Android, iOS, any desktop app, or on an edge device—we’ll need a .tflite version of the model, which is the model version for common mobile and edge use cases.
To export the model, we have to click the Tf Lite card and choose a Google Cloud Bucket to export it.
Once you export the model to the Google Cloud bucket, you’ll be able to see a .dict file containing the class names of your model and a JSON file explaining the input and output shapes of the image. The dictionary file is the dictionary of your class names. It contains the class names whose scores/confidences will be predicted by the TensorFlow Lite model.
The JSON file helps us understand what type of input is accepted, along with other information about the model.
For example: Here, the dict file will contain two classes dog and cat. While running the code mentioned below, we will get the confidence of the picture is a cat or a dog respectively.
Your output_data will contain the class names and the accuracy score of the image. We have achieved an accuracy of 93.2% with our dataset, which is fine for most basic use cases.
Conclusion
AutoML is first on my list for a Cost + Effort < Output analysis. It does come with the inevitable costs of online predictions. But if you’re using the model offline (i.e. on-device), then there won’t be any bills to pay 😀
AutoML works great for classification problems and is great for beginners who want to solve real-world problems using ML.
In this post, we have exported the Tf Lite model and used it in our codebase. In the coming posts, we will be using various available formats of the AutoML Vision Edge.
If you liked the article, please clap your heart out. Tip — Your 50 claps will make my day!
Want to know more about me? Please check out my website. If you’d like to get updates, follow me on Twitter and Medium. If anything isn’t clear or you want to point out something, please comment down below.
Comments 0 Responses