
Introduction
Machine learning is rapidly moving from manually designed models to automated data pipelines using tools such as auto-sklearn, MLbox, and TPOT. In using these automated tools, the aim is to simplify the model selection process and come up with the best data set features for our model.
In this article, we’re going to learn how to use feature tools and Deep Feature Synthesis to automatically come up with the right set of features for our dataset. The complete code and data for this guide is available on my GitHub.
Learning without a recipe is a sure way to forget. So before we dive deeper into automated feature engineering, let’s establish some basic understanding of features and feature engineering more generally.
What are features?
Features are typically measurable attributes depicted by a column in a dataset. For instance, customer datasets often include features like customer id, income, and joined. I strongly recommend these guides for a better understanding of features in machine learning:
● Basics concepts of feature selection.
● Introduction to feature selection
Feature Engineering
Typically, we can define feature engineering as the creation of new features from existing ones, in order to improve model accuracy. This involves selecting only those features that are really important.
Feature engineering is an essential parameter of a successful model as observed below:
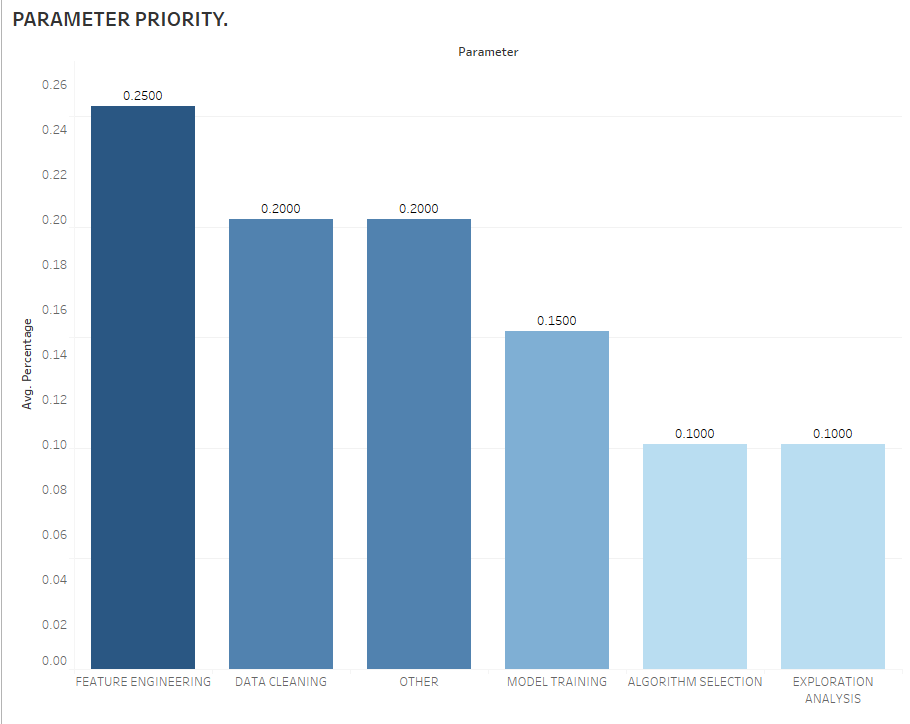
This reinforces the fact that data scientists spend about 80% of their time on feature engineering, which is time consuming and requires domain knowledge and mathematical computations.
For a solid understanding of feature engineering, the following resources can serve as a comprehensive guide:
● Understanding Feature Engineering
Manual Feature Engineering
Manual feature engineering relies on domain knowledge, intuition, and data manipulation.
This can be grouped into:
i) Transformations
Transformations act on a single table by creating new features out of one or more existing columns.
We’re going to create new features from our customer table. These features include: joined month, joined year, mean income, and log income. The initial table only three features: customer id, joined date, and income, from which we’ve been able to create more features, as shown below:
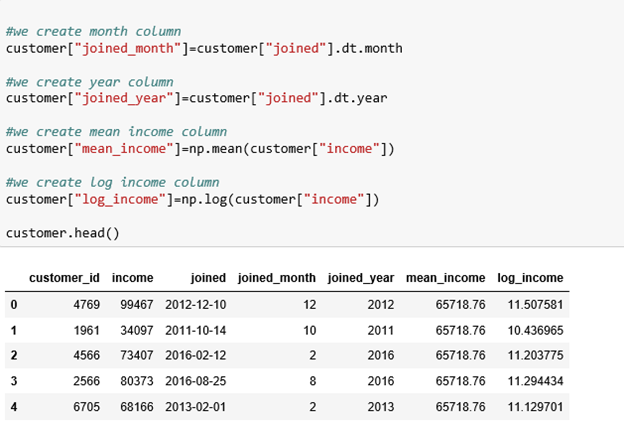
ii) Aggregations
Aggregations are performed across tables and use a one-to-many relationship (parent-to-child) to group observations and then calculate the statistics.
In our case, a customer may have multiple loans, and thus we may have to calculate the mean, maximum, and minimum loan amounts for each customer.
This is done by grouping the loans table with the client table, calculating the aggregations, and merging the results with the customer table. The commands are as shown:
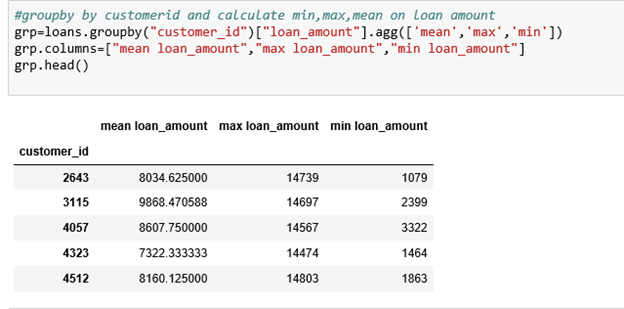
We now merge the customer data frame with the loan amount aggregations.

It’s evident that manual feature engineering can grow quite tedious with many columns and multiple tables. Suppose your machine could automate this process and determine the best feature metrics for your model. And suppose that with these better features, the model trains faster, makes more accurate predictions, and ultimately results in better models.
Fortunately, Featuretools can automate the entire process and come up with more useful and precise features.
Featuretools
Featuretools is a framework used to automate the feature engineering process. It works by transforming transactional and relational datasets into feature matrices for machine learning.
Featuretools works on a concept known as Deep Feature Synthesis (which we will discuss later), which stacks up multiple features together.
Implementing Featuretools
We first import our featuretools library:
Data
Next, we need to define our data:
Customer-unique customers who borrowed loans.
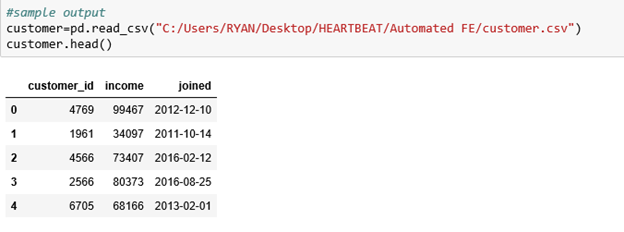
Loans-unique loans with the associated attributes.
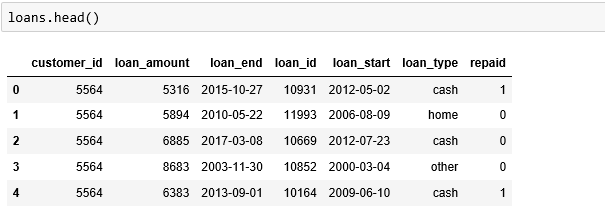
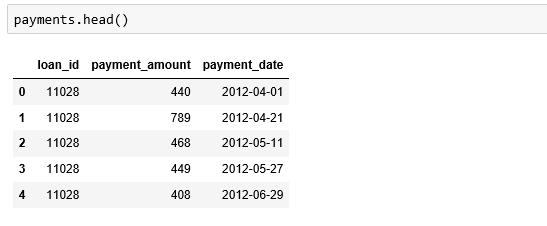
Payments-list of various payments of the loans made by the customer.
Entity
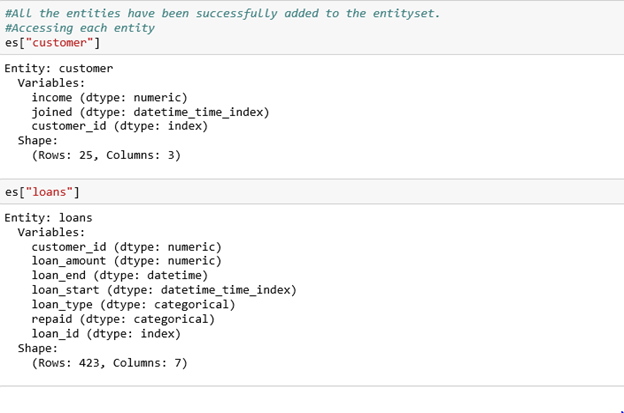
An entity is basically a table (dataframe). For our case, customer, loans, and payments are our entities. Each entity must have an index (uniquely identifying column) i.e. customer id or loan id. In case our entity doesn’t have an index, we pass the make_index=True command and then specify a name for the index. If the entity has a unique time stamp, we pass the time_index command.
Entityset
Entityset is a large data structure (dictionary) composed of many individual entities and the relationships between them.
In the code below, we create three entities (customer, loans, payments), and then we add them to our entityset customer.

Accessing each entity with the associated attributes:
Relationships
We now need to define the relationships between the entities in our entityset. The most intuitive way to think of relationships is the parent-child analogy, which is a one-to-many relationship where for each parent, there can be multiple children.
In our example, the customer dataframe is the parent of the loans dataframe, where each customer may borrow multiple loans. Likewise, the loans dataframe is the parent of the payments dataframe, where a loan can have multiple payments.
These relationships are what allow us to group data points together using aggregation primitives and create new features. We need to specify the parent and child variables to define our relationship.
This is the variable that links the two entities together. In our case, the customer and loans data-frames are linked together by customer_id.
The general format for defining our relationship is:
(parent_entity, parent_variable, child_entity, child_variable)
We now define the relationships between the data-frames and add them to the entityset:

Feature Primitives
Feature primitives are basic operations that we use to form new features, can be applied across datasets, and can be stacked on top of each other to create complex features.
They are grouped into:
i) Aggregations.
ii) Transformations.
Hint: Refer to the upper section for a detailed description.
Let’s take a look at the list of feature primitives in Featuretools:
Aggregations:

Transformations:

We create new features using the specified primitives. Our target entity is the customer dataframe because we want to create new features about each customer specifying the aggregation and transformation primitives. You can select your own target entity and tweak with the primitives.
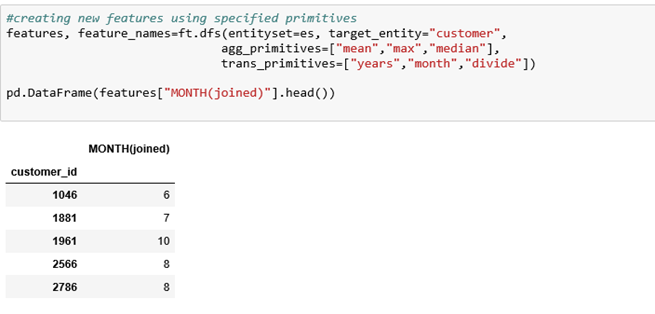
Features output:
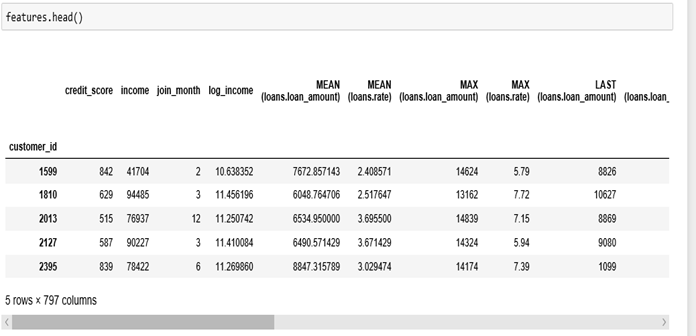
The usefulness of featuretools can be observed; it performed the same operations we did manually, but it also added more.
Deep feature synthesis (DFS)
DFS is an automated method for performing feature engineering on relational and multi-table data. DFS works using the concept of stacking multiple primitives together to get deep features.
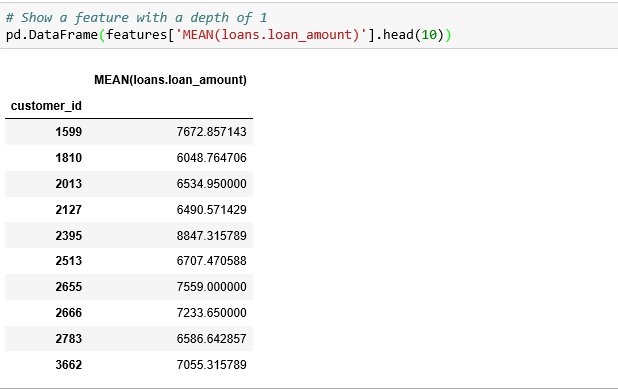
The depth of a feature is simply the number of primitives required to make that feature. A feature that relies on a single transformation or aggregation would have a depth of one, while that which stacks two primitives would have a depth of two.
In our instance, the MEAN (loans.loan_amount) feature has a depth of one because it’s made by applying a single aggregation primitive.
The LAST(loans.MEAN(payments.payment_amount)) has a depth of two because it’s made by stacking two feature primitives — first an aggregation and then a transformation.
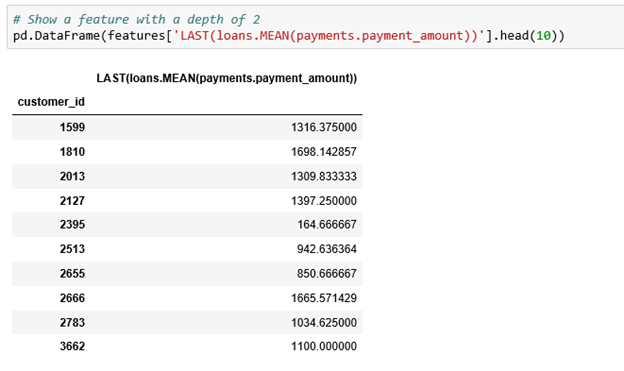
We can create features of arbitrary length by stacking more primitives. I’d encourage anyone interested to experiment with increasing the depth for a real data set.
We can let featuretools automatically generate many new features using the ft.dfs function, without passing any primitives. We only set the max-depth, entity-set, and target-entity, and featuretools automatically tries many combinations of feature primitives to the ordered depth.
DFS is powerful in that it can create a feature matrix for any entity in our data. All we have to do is change the target-entity.
For a deeper understanding of DFS, I recommend the following resources:
● Deep Feature Synthesis: How Automated Feature Engineering Works.
● Deep Feature Synthesis, the algorithm that will automate machine learning.
Conclusion
Even with all the resources of a great machine learning expert, most of the gains come from the great features, not the algorithms used.
Automated feature engineering can create the problem of too many features. As such, ML experts have to have the intuition, creativity, and knowledge to discern the appropriate features that will improve their models.
Great appreciation goes to Will Koehrsen for his guide on automated feature engineering from which I drew inspiration for this article.
My hope is that you’ve gained valuable insights from this article on automated feature engineering.
If there are any tips you’d like to add to this article, feel free to leave a message in the comments. Any sort of feedback is appreciated! Don’t forget to share. We can continue with the discussion through my LinkedIn.
Discuss this post on Hacker News and Reddit.
Comments 0 Responses