
Audio source separation is a wonderful use case where every one of us can easily relate with and in this article we are going to deep dive into technical implementations of the solution where we will build an Android app with the TensorFlow model performing audio source separation.
Before getting into the concept, let me tell you we are going to create a faithful reproduction of the Official Spleeter solution in the TF2.0 leveraging its latest features, but for Android use.
For those who are not aware, Spleeter is an industry standard audio source separation library and their solution performs at amazing accuracy in splitting the audio into different stems. So, kudos to the authors for building such a wonderful solution.
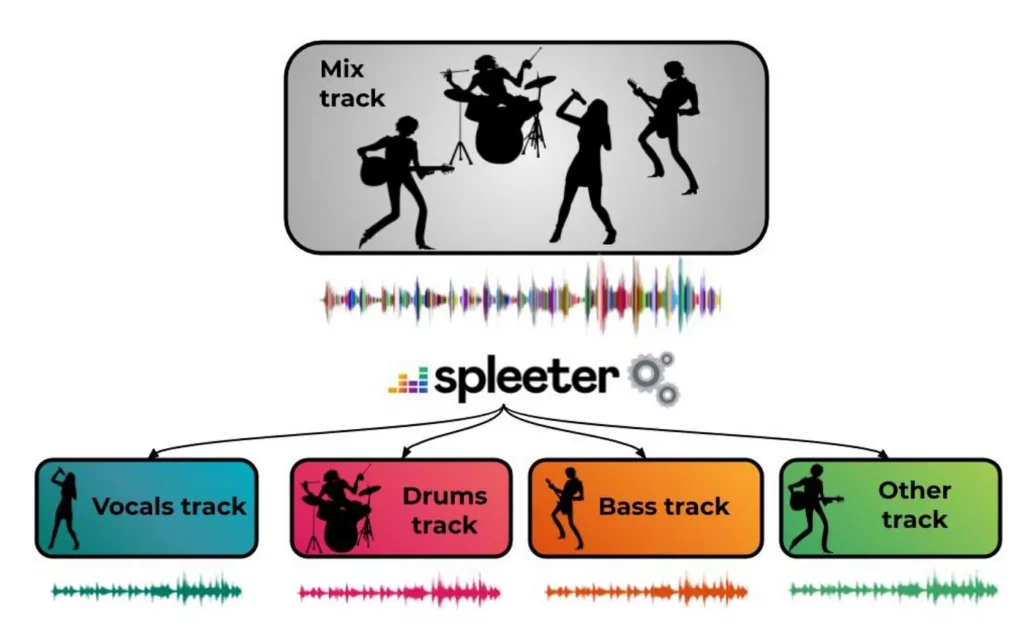
Table of contents:
- Audio Source Separation
- Audio Source Separation on Edge devices
- Network Architecture — Image Segmentation and UNet
- MusDB Dataset:
- Audio Data Processing — Spectrogram
- Custom Training Loop — Tensorflow
- TFLite Model Generation
- Accuracy and Further Steps
- Logical Architecture of the Solution
- Functioning Mobile App
- Audio Processing Process
- Mobile FFMpeg — Generate Audio from Magnitude Values
- Further Plans
Audio Source Separation
Audio Source Separation is a process where the audio data can be processed and split into various stems corresponding to each of the instruments present in the source audio.
Imagine you are a musician and have created a wonderful song with an excellent composition of accompanying instruments such as piano, guitar, drums, etc., from your band. Now, you would like to extract the music corresponding to one of the instruments separately, say piano, and would like to use it for some other purpose. Audio source separation helps you in doing this as you can separate individual stems of your music from the source data.
There are various techniques to do this and the Spleeter team have used AI technology and have achieved astounding success in the process.
Audio Source Separation on Edge devices
Spleeter has been open sourced since about a year ago and various services have emerged online leveraging Spleeter models for audio source separation activities.
With the arrival of Tensorflow 2.0 and TFLite framework, I was working towards migrating Spleeter’s TensorFlow model into TFLite version but I could not succeed as the solution had been built on TensorFlow 1.0 and the built model is only available in tensorflow’s ‘checkpoint’ version.
After multiple failed attempts, I have decided to recreate the Spleeter code in TF2.0 with the latest features so that the generated model can be extracted into a TFLite version with which I will be able to perform source separation tasks on the mobile app itself.
This project is a humble effort towards this — with my limited resources — where I have been able to build the model and use the model in Android app. Of course, the model’s accuracy is not so great — but I have been able to put-together an e2e working solution. I will be working towards improving the accuracy further and you can refer to the github project for the up-to-date information.
So, let’s get started and dive into the code.
The source code of the model is available here for your reference:
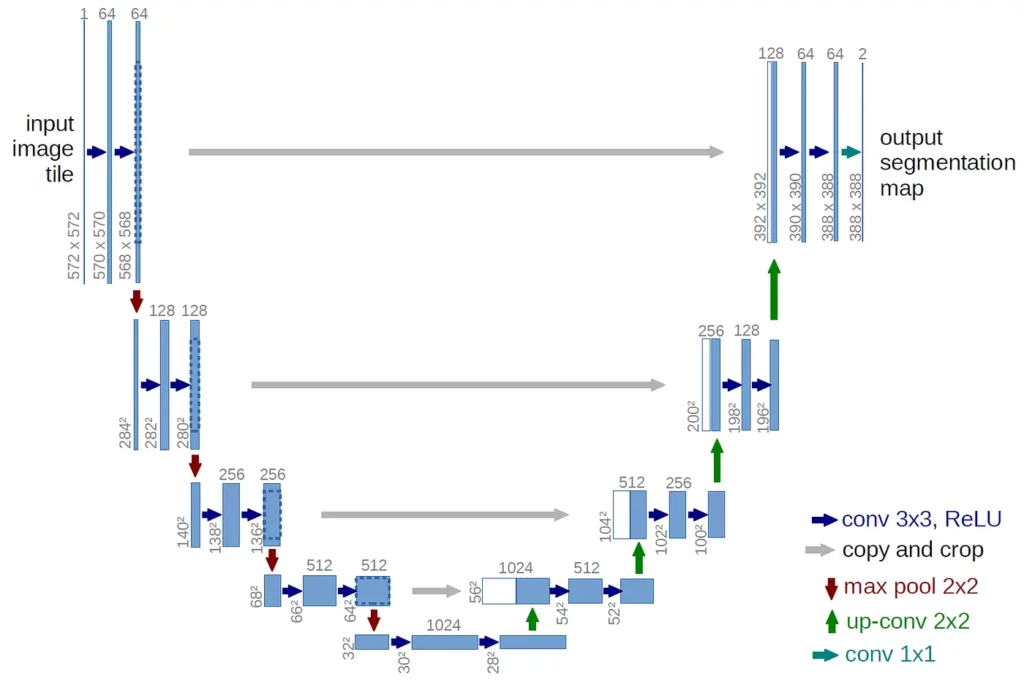
Network Architecture — Image Segmentation and UNet
Audio source separation has been conceptualized along the lines of image segmentation principles. Image segmentation is primarily the process of partitioning a digital image into various segments to simplify or to represent an image into more meaningful way for better analysis.
UNet is one of the neural network architectures that has achieved a huge success in the process of image segmentation.
MusDB Dataset:
Audio source separation solutions require a specialized dataset for training that should contain the actual audio file and audio’s respective instrumentation versions.
MusDB dataset is a dataset that contains 150 audio files along with their isolated drums, vocals, bass, and other stems. We will be using MusDB as our training dataset and you can follow the below procedure for processing:
- MusDB dataset is a protected dataset and the request for the access has to be placed in the below link: https://sigsep.github.io/datasets/musdb.html#musdb18-compressed-stems
- Once request is placed, dataset access would be provided by the owners in a period of 24 hours.
- Dataset will be around 4.4 GB in size and there will be two folders — ‘train’ and ‘test’ with 100 and 50 files respectively.
- You will observe the dataset to be in the format of ‘.stem.mp4’ and each of the files will contain individual stems of the respective musics such as: Bass.wav, drums.wav, mixture.wav, other.wav, and vocasl.wav.
- We will be required to decode the ‘.stemp.mp4’ file into respective stems for us to feed the data during training.
- Place the dataset under the ‘musdb_dataset’ folder.
- Execute the ‘musdecode.sh’ shell script and it will decode each of the fils, extract the stems and place them under the respective directory.
Audio Data Processing — Spectrogram
Once audio files are extracted, the next step is about audio processing. Files ‘musdb_train.csv’ and ‘musdb_validation.csv’ contain the information about the files to be used for train and validation purposes. Configuration values are set in the ‘musdb_config.json’ file.
TensorFlow Dataset is used to process data from csv files. Magnitude values of audio files are read and they are further processed to generate the spectrograms (STFT). During the processing sequences of filters are being applied to filter out the erroneous segments of data.
Custom Training Loop — Tensorflow
TensorFlow in its latest version has introduced a powerful feature called ‘GradientTape,’ which helps in training (Neural Nets) NN having custom training requirements.
Most of the NNs could fit with the Keras-based traditional training cycle, where the requirement is to train with one set of inputs and outputs. But there are some complex models where the architecture will not fit this traditional structure and we will require custom training. GradientTape is primarily used to train such networks.
With regard to audio source separation, as you would have seen there are five sets of input audio files in training dataset — mixture.wav acts as the primary input and UNet is trained to minimize the transformation loss in converting this file into each of the four instrument stems.
Loss function used here is RMSE, but it is a mean of the individual losses of each of the instrument transformations and the network is being trained to minimize the overall loss.
Tensorflow GradientTape feature is used here as below, to achieve the stated objective:
def stepFn(inputFeatures, inputLabel):
global opt
output_dict = {}
with tf.GradientTape(persistent=True) as tape:
for instrument in _instruments:
output_dict[instrument] = model_dict[instrument](inputFeatures['mix_spectrogram'])
losses = {
name: tf.reduce_mean(tf.abs(output - inputLabel[name]))
for name, output in output_dict.items()
}
loss = tf.reduce_sum(list(losses.values()))
for instrument in _instruments:
grads = tape.gradient(loss, model_trainable_variables[instrument])
opt.apply_gradients(zip(grads, model_trainable_variables[instrument]))TFLite Model Generation
Our custom training loop has been written in such a way that it will periodically save the generated model at the end of every 100 runs. The model will be saved in the formats of ‘saved_model’ and ‘checkpoint.’ The SavedModel format is primarily to generate the TFLite model, whereas ‘checkpoint’ is to restart the training from the previous run.
Accuracy and Further Steps
Audio source separation requires the model to be trained on larger a dataset for a large number of runs. The official Spleeter model has been trained on over 100 audio files (~10 hours of audio) for more than 200K runs in a GPU. This training process went on for more than a week, it seems.
As I do not have the infrastructure to support such a huge volume of run, I have trained the model hardly for 2K runs with small set of data. Accuracy of the current model is pretty low, nevertheless the objective is to build a low performing model and to develop an Android app out of it.
As the e2e functioning solution is available, training of the model with a larger dataset and accuracy improvement activities can be subsequently taken care of. So, anybody who is interested in this use case and would like to work with me in training the network on GPU — please get in touch with me. We can work together!
As mentioned above, this project is an effort to build audio segmentation models in TF 2.0 with Spleeter as a reference — and thanks to the Spleeter team for providing such a wonderful library!
At the end of the article, our Android app would help you in extracting the vocal track of the sample input.
Original Input Track:
Vocal only track as extracted by the mobile app:
[Audio track would contain lot of noises along with the vocal part]
As you would have heard, vocal extracted audio contains a considerable amount of noises along with the vocal portion. Primary reasons for the noises are as below:
- Limited amount of model training and data — I have limited access to the GPU environment. With a larger dataset and larger epoch, output of the model would certainly be lot better.
- Output of TFLite model in Android is not exactly the same as in a Python environment. There exists a difference and with this complex model of audio segmentation, the difference is larger.
- The real challenge in building the audio AI solutions in an Android environment is primarily associated with the lack of Java libraries. JLibrosa has been primarily built to address this gap, where it generates the audio feature values as similar to Python. But still there exists a difference in certain cases and that is adding to the noises.
So, considering these challenges, I will be adding an another layer on top of the audio segmentation model output to de-noise the extracted audio. With this de-noiser — output looks pretty much decent and the extracted vocal portion of the audio would sound as below:
Logical Architecture of the Solution
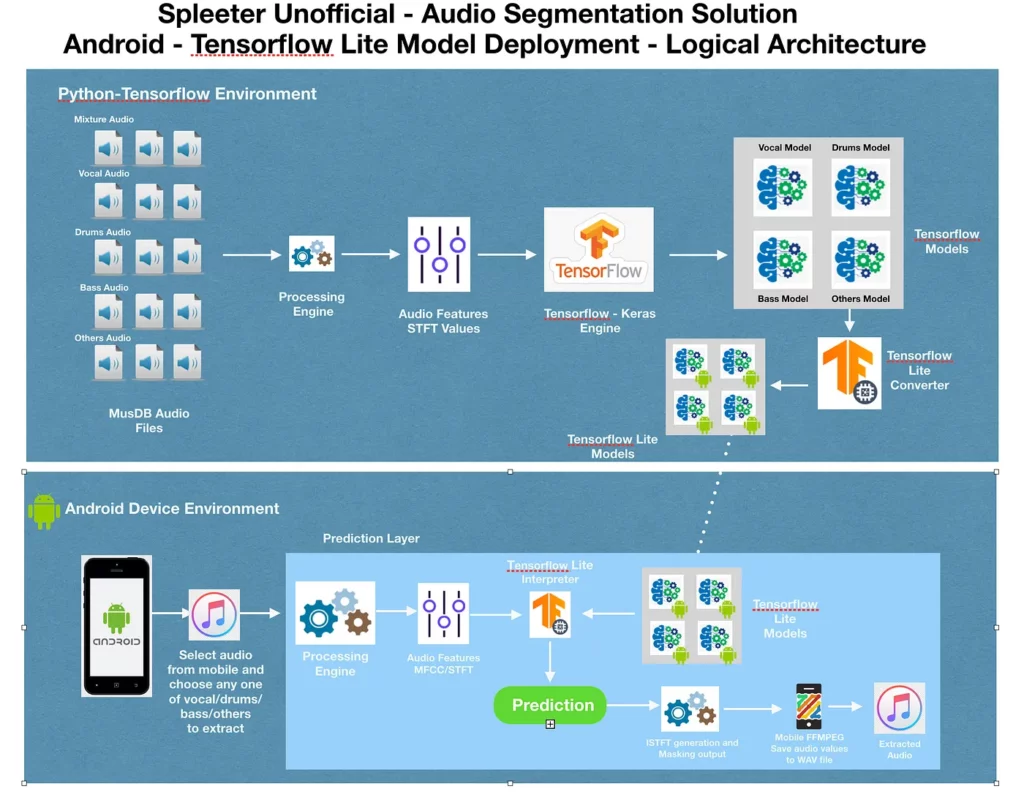
The below image provides the logical architecture for the overall solution.
The first section of the image corresponds to building the TFLite models in Python-TF environment with MUSDB audio files as input. Refer to the first part of the article to understand the various components involved in the training process.
One key difference between the official Spleeter model and this project is the way models are generated. Official Spleeter generates a single model to extract different stems of the audio, whereas this project generates an individual model for each of the stems (such as Vocal, Drums, Bass, or Others) and the models need to be used accordingly in Android environment for audio extraction.
Please note in the current state of the project, the ‘vocal’ model only has been built. But preparing the rest of the models is just a configuration change and retrain of the models. I plan to have it done soon.
Functioning Mobile App
Functioning code of the above project is available below and you can download to try it yourself. This project is actively being worked on, so please expect considerable changes.
Please note that this project’s primary intent is to build the audio segmentation feature on device. So, I have not spent much time on the mobile UI features.
As you will have observed, the current mobile app is a simple app where users would select the audio file placed in the designated directory and trigger the background process for audio segmentation. Audio processing is a time-consuming process and it will take around 3 to 5 minutes for processing and at the end of the processing a generated audio file would be saved in another designated directory.
As there are additional processing layers to be built and different stem models to be developed, enhancing the UI layer is not a key priority and the focus currently is towards making the model more accurate.
Audio Processing Process
The real challenge with regard to porting TF models into mobile is primarily associated with the data processing. Especially in the case of audio data, we do not have any standard libraries available for generating various audio features.
Library ‘jlibrosa’ has been built primarily for this purpose and it helps in generation of audio features in the Android environment. With regard to this project, audio data would be subjected to various processing such as ‘STFT’ (Short Time Fourier Transform), ‘iSTFT’ (Inverse Short Time Fourier transform’), masking, etc., and you can find the respective code in the repository.
Mobile FFMpeg — Generate Audio from Magnitude Values
As we perform lots of processing both pre and post predictions from the TFLite model, we will be generating a magnitude value of audio and we will be required to convert the audio values into ‘wav’ format so that the audio can be played back.
This project uses mobile FFMpeg library for this purpose and leverages the piping feature of the library to create audio files.
Respective gist of the code can be found below (refer to the method ‘saveWavFromMagValues’ in the project for more details):
val byteArray = convertFloatArrayToByteArray(instrumentMagValues)
val externalStorage_1: File = Environment.getExternalStorageDirectory()
val audioFileName: String = audioInputFileName + "_vocal"
val outputPath_1 = externalStorage_1.absolutePath + "/audio-separator-output/" + audioFileName + ".wav"
val sampleOutputFile = externalStorage_1.absolutePath + "/audio-separator-output/bytes_j.txt"
val pipe1: String = Config.registerNewFFmpegPipe(applicationContext)
try {
val file = File(sampleOutputFile)
// Initialize a pointer
// in file using OutputStream
val os: OutputStream = FileOutputStream(file)
// Starts writing the bytes in it
os.write(byteArray)
println(
"Successfully"
+ " byte inserted"
)
// Close the file
os.close()
} catch (e: Exception) {
println("Exception: $e")
}
val ffmpegCommand = "-f f32le -ac 2 -ar 44100 -i " + pipe1 + " -b:a 128k -ar 44100 -strict -2 " + outputPath_1 + " -y"
// val ffmpegCommand = "-f f32le -ac 2 -ar 22500 -i " + pipe1 + " -b:a 128k -ar 22500 -strict -2 " + outputPath_1 + " -y"
Runtime.getRuntime().exec(arrayOf("sh", "-c", "cat " + sampleOutputFile + " > " + pipe1))
FFmpeg.execute(ffmpegCommand, " ");Further Plans
As mentioned above, the extracted vocal portion of the audio contains lot of noises. I will be adding a de-noiser post extraction, so that the audio will be clearer.
Please watch out for the third part, where the mobile app would generate a pretty nice extraction of vocal tracks from the music file.
If you would like to collaborate with me to have these models trained on a larger dataset in GPU environment, please reach out — I would love to collaborate.
Comments 0 Responses