
Supporting deep learning inference on mobile and edge devices has gained popularity more than ever and we have a greater number of options to choose from when carrying out AI-related development tasks on our little companions than we could have guessed.
Not only is implementing machine learning models—the standard for tasks such as computer vision—faster and easier on mobile devices these days, but the renewed competition between the developers of frameworks supporting them also seems to have ensured that the process itself reaches new heights in terms of performance, flexibility and adaptability.
Not a big surprise considering how edge devices such as smartphones, wearables and IoT devices are omnipresent and tech companies all want in on the mobile ML development front.

Performing deep learning activities directly on mobile devices has many benefits, such as low latency, security, and increased personalization to name a few. In order to make the best of these activities, inference engines specifically optimized for such devices have been cropping up.
A few examples are TensorFlow Lite (Google), Core ML (Apple), PyTorch Mobile (Facebook) and so on. Last year, among other Asian tech firms such as Xiaomi, Baidu, and Tencent, Alibaba also joined the fray with its offering: Mobile Neural Network (MNN) — an open source deep learning framework built to address the demanding requirements of high-traffic applications such as Taobao. Some of the strengths, benchmarks and design choices of MNN are discussed in this article.
The latest from Alibaba
As a lightweight mobile ML framework, MNN offers support for the inference and training of deep learning models specifically for edge devices. MNN is integrated within over 20 apps by Alibaba Inc, such as Taobao, Tmall, Youku, Dingtalk, an Xianyu.
It takes care of various AI-specific tasks such live broadcast, short video capture, search recommendation, searching products by their images, interactive marketing, equity distribution, security risk control, and so on. Touted by Alibaba as being run over a 100 million times per day, MNN is also applied in IoT devices like Cainiao will-call cabinets.
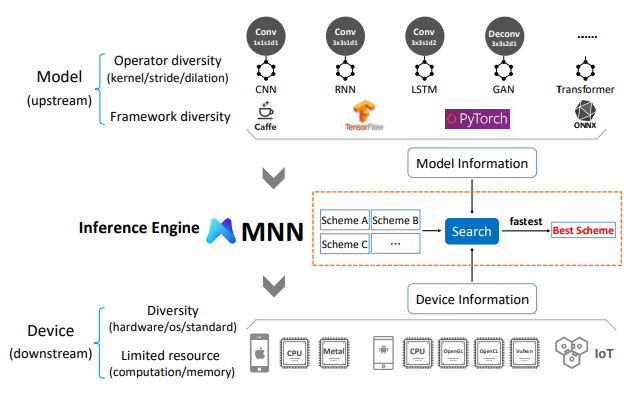
MNN tries to address a few key issues that inference engines face on mobile devices. Firstly, most models for mobile devices are trained from well-known frameworks such as TensorFlow, PyTorch, Caffe, etc., and the basic requirement is that these engines must support not only such standard formats but also be scalable to future formats that can be derived from these.

Additionally, MNN also tries to keep up with device diversity on the hardware level (i.e. architectures such as ARM, Adreno, etc.) and software level (iOS/Android/embedded OS). All this must be done keeping in mind the efficiency needed to run high-performance inference on devices using as little memory and energy as possible. Alibaba has made the MNN open-source and accessible for all on GitHub.
What MNN brings to the table
Alibaba has tried their best to put together a universally-compatible inference engine while maximizing its efficiency and going the extra mile by utilizing these features:
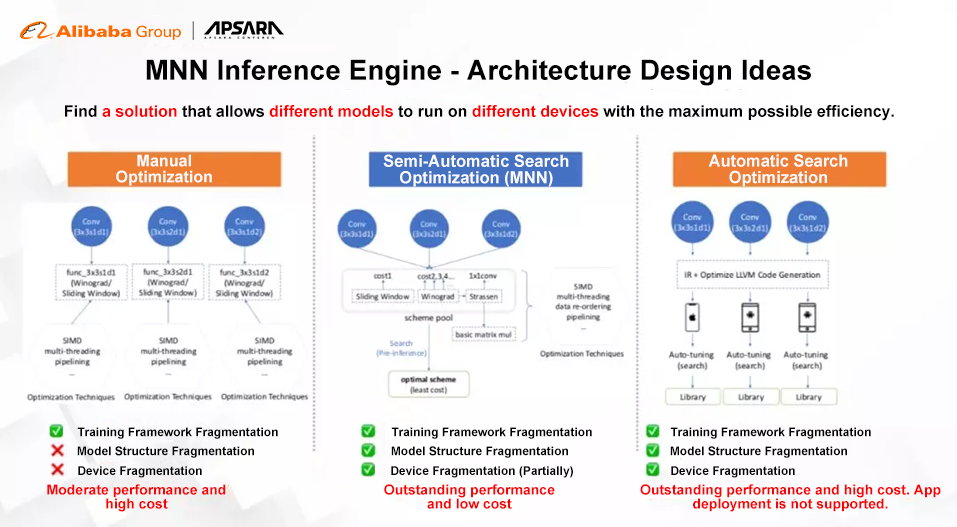
- A mechanism called pre-inference, which performs runtime optimization through online cost evaluation and optimal scheme selection.
- In-depth kernel optimization by using improved algorithms and data layouts to boost the performance of some widely-used operations.
- A backend abstraction module to enable hybrid scheduling and keep the engine as lightweight as possible. Integrating MNN into applications only increases the binary size by 400 ∼ 600KB.
We’ll delve further into what these features exactly do in a minute. Additionally, the inference engine also boasts of the following advantages for deep learning activities on the edge:
- High performance — MNN makes full use of the ARM CPU on mobile devices by implementing core computing with optimized assembly code. On iOS, GPU acceleration ensures faster speed than Apple’s native Core ML. Similarly, on Android, OpenCL, Vulkan, and OpenGL are available and fine-tuned for mainstream GPUs (Adreno and Mali). Convolution and transposition convolution algorithms are efficient and stable. The Winograd algorithm significantly enhances symmetric convolutions. According to Alibaba, its speed is 2x for the new ARM v8.2 architecture.
- Lightweight — Optimized for mobile and embedded devices, MNN is easily deployable and comes with no additional dependencies. On iOS, the static library size for ARMv7+ARM64 platforms is about 5MB, while on Android, the core size combined with OpenCL/Vulkan is less than 1MB.
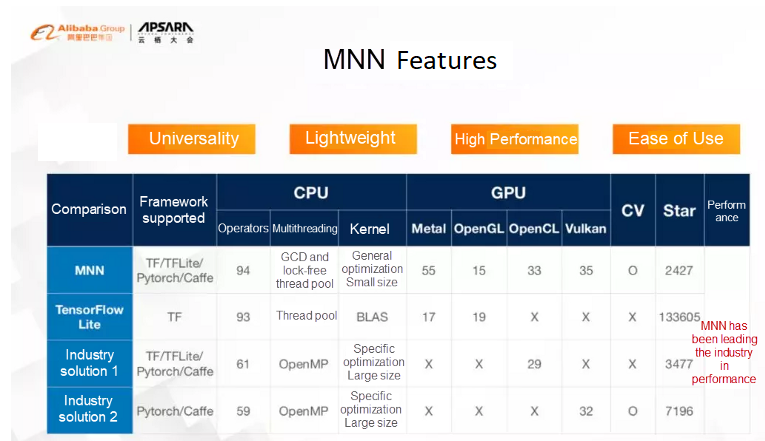
- Versatility — MNN provides support to reuse popular model formats such as TensorFlow, Caffe, ONNX and common neural networks such as CNNs, RNNs, and GANs. The MNN model converter supports 149 TensorFlow OPs, 58 TFLite OPs, 47 Caffe OPs, and 74 ONNX OPs. Besides, different hardware backends are also supported, such as 111 OPs for CPU, 6 for ARM V8.2, 55 for Metal, 43 for OpenCL, and 32 for Vulkan. The software versions compatible are iOS 8.0+, Android 4.3+, and embedded devices with POSIX interface. Hybrid computing is also possible on multiple devices.
- Ease of use — MNN has adopted an image processing module that speeds up affine transform and color space transform without libYUV or OpenCV. It provides callbacks throughout the workflow to extract data or control the execution precisely, along with options for selecting an inference branch and parallel branches on CPU and GPU. The MNN Python API helps ML engineers to easily use MNN to build a model, train it, and quantize it, all with minimal coding.
A universally-efficient inference engine ? Let’s dig in…
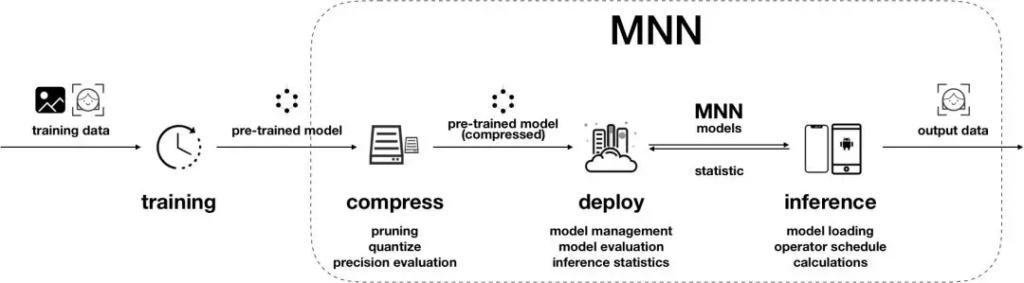
MNN’s internal working can be broadly classified into two parts: an offline conversion process, and the on-device inference process.
For the first part, the converter takes models as input from different deep learning frameworks and transforms them to the native model format (.mnn). Some basic graph optimizations such as operator fusion, replacement, and model quantization are done in the background. In the inference part, three modules are involved: pre-inference, operator-level optimization, and backend abstraction.
Some heavy terms, right? Let’s take a closer look into what is actually going on.
Pre-Inference
A fundamental part of MNN’s architecture, this process is actually a big reason for its highly-efficient inference process. It takes advantage of a common phenomenon that the input size is typically fixed (or can be pre-processed into a target size) in many deep learning applications.
The two sub-steps that happen here are called computation scheme selection and preparation-execution decoupling. The first is a cost evaluation mechanism to select the optimal scheme from a scheme pool, which takes into consideration both the algorithm implementation and the backend characteristics. Think of how certain functions assign a cost factor when training during ML. A similar concept is applied here in the name of memory optimization.
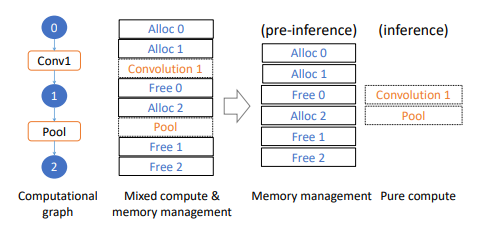
In the second part of the pre-inference process, MNN pre-allocates required memory as a memory pool during the pre-inference stage and reuses it in the following inference sessions (see the diagram above).
Since input size is determined or can be pre-processed into a target size, MNN can infer the exact required memory for the entire graph by virtually walking through all operations and summing up all allocation and freeing. This way, MNN achieves better performance when the selected scheme is GPU-related. Bypassing time-consuming setups, inference time using this technique can drop by about 7% ∼ 8% on CPU and 50% ∼ 75% on GPU.
Simply put, the pre-inference module serves the purpose of dynamically determining the optimal computation solution. Memory usage and computational cost can be determined ahead of the actual inference, thus improving performance.
Kernel Optimization
An optimization process at the operator level utilizes advanced algorithms together with techniques like SIMD (Single Instruction Multiple Data), pipelining to further boost the performance. Winograd and Strassen algorithms play a big role here, and researchers at Alibaba assert that MNN is the first ever mobile inference engine to adopt the Strassen algorithm to accelerate large matrix multiplication.
Simply put, this particular step is all about choosing the optimal algorithm with the lowest arithmetic complexity and making the most of available hardware resources for the fastest execution possible.
Backend Abstraction
A dedicated module for backend abstraction has been introduced in MNN to make all the hardware platforms (e.g., GPU, CPU, TPU) and software solutions (e.g., OpenCL, OpenGL, Vulkan) encapsulated into a single uniform class.
This module provides a number of advantages to MNN, such as reducing complexity by having the uniform class manage resource loading and optimal memory allocation or enabling hybrid scheduling. With backend abstraction, MNN divides all tasks into two separate independent parts.
This means that frontend developers can focus their efforts on things such as fast operator execution while all unrelated backend details are hidden. The backend developers can devote their time to exploiting different backend specifications and offering more convenient APIs. The point of this entire process is to set up a “wall” of sorts, so that backends are implemented as independent components while using the module to hide raw details.
Putting all the pieces together
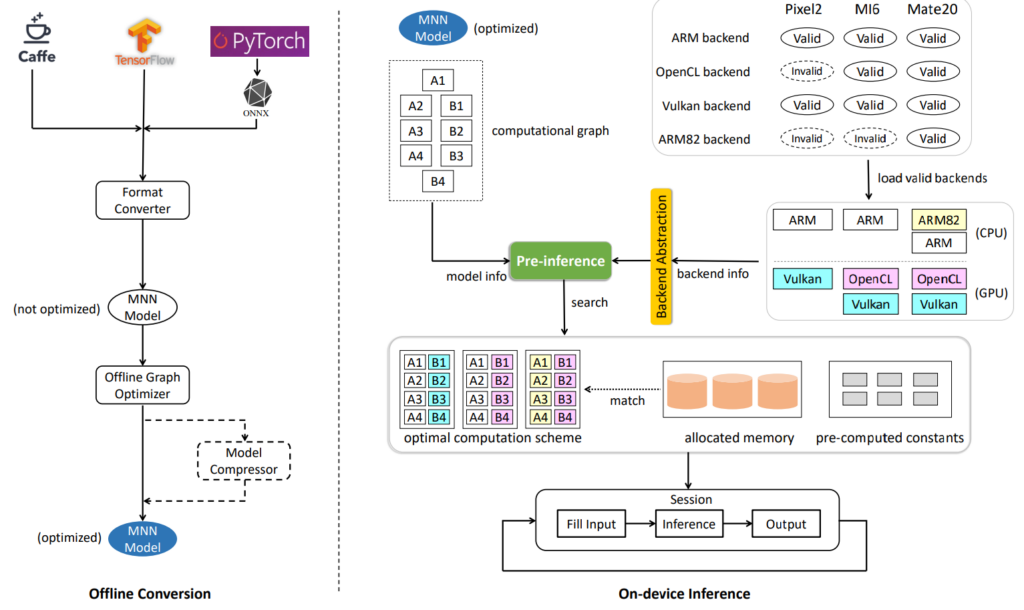
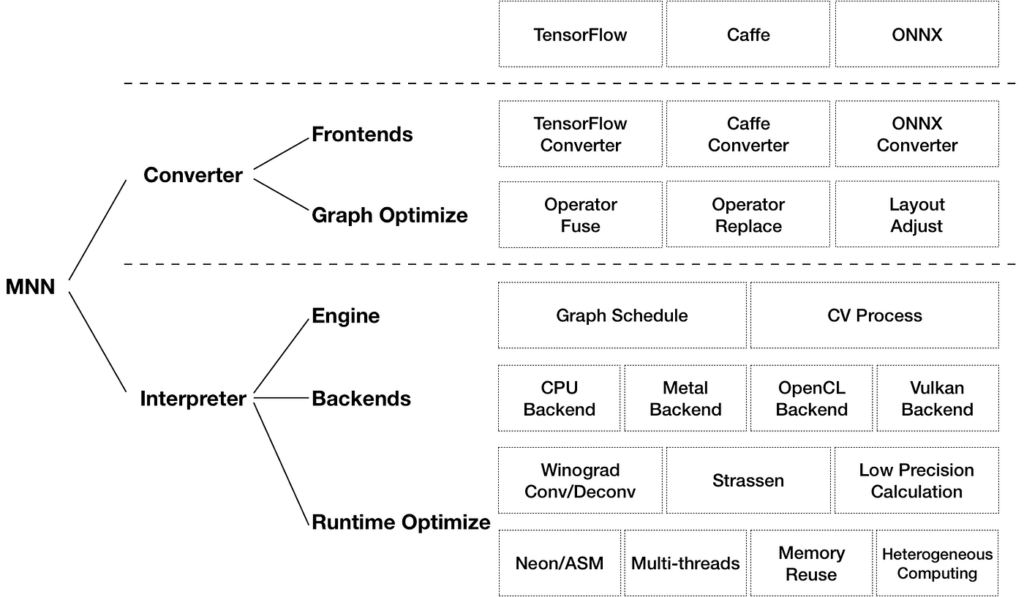
Alibaba’s Mobile Neural Network can be broadly partitioned into two parts: a converter and an interpreter.
According to the diagram above, the converter consists of frontends and graph optimize. While the former is responsible for supporting different training frameworks (MNN currently supports TensorFlow/TFLite, Caffe, and ONNX), the latter optimizes graphs by operator fusion, operator substitution, and layout adjustment.
Similarly, the interpreter consists of the inference engine and backends. Within the interpreter part, MNN applies a bunch of optimization schemes, such as the Winograd algorithm for convolution and deconvolution, Strassen algorithm for matrix multiplication, low-precision calculation, Neon optimization, hand-written assembly, heterogeneous computing, multi-thread optimization, memory reuse, etc.
For any inference engine, high performance is a vital factor that decides how widely it gets adopted by devs. Thus, the continuous efforts into optimization and better performance.
While an industry standard would be to go directly for a case-by-case optimization solution, an issue that often crops us is that some elements are left out of the optimization cycle and become a performance bottleneck. MNN adopts a different solution by isolating granular units (say, matrix multiplication) and optimizing them with fast algorithms. Anything on top of these units automatically gets a boost.
Benchmarks
In their research, the developers at Alibaba have carried out ample experiments comparing the performance of MNN with other state-of-the-art mobile inference engines, including Core ML, TFLite, NCNN, and MACE. The benchmarks are obtained on iOS with the iPhone8 and iPhoneX (processor: Apple A11 Bionic) as well as on Android, using the Xiaomi MI6 (processor: Snapdragon 835) and Huawei Mate20 (processor: Kirin 980). The networks used are MobileNet(v1), SqueezeNet(v1.1) and ResNet-18.
Make a note of the following results:
- In general, MNN outperforms other inference engines under almost all settings by about 20% to 40%, regardless of the smartphones, backends, and networks.
- For CPUs with 4 threads, inference with MNN is about 30% faster than others on iOS platforms, and about 34% faster on Android platforms (e.g., Mate20).
- On Metal GPU backend on iPhones, MNN is much faster than TFLite, a little slower than Core ML but still comparable, which is reasonable since Core ML is Apple’s exclusive solution tailored to iOS, while MNN is meant to support backends of different operating systems.
- On Android GPU backends, other engines usually have their performance blind spots. For example, NCNN with Vulkan backend is not very fast on MI6; TFLite with OpenGL still has much room for improvement on ResNet-18. In contrast, MNN obtains favorable results on all different hardware platforms and networks, backing up its claims for supporting “device diversity”.
- Multi-thread CPU inference using MNN on high-end devices (e.g. iPhone 8 and iPhone X) is highly competitive compared with those using GPU backends, which demonstrates the effectiveness of the kernel optimization properties of MNN.
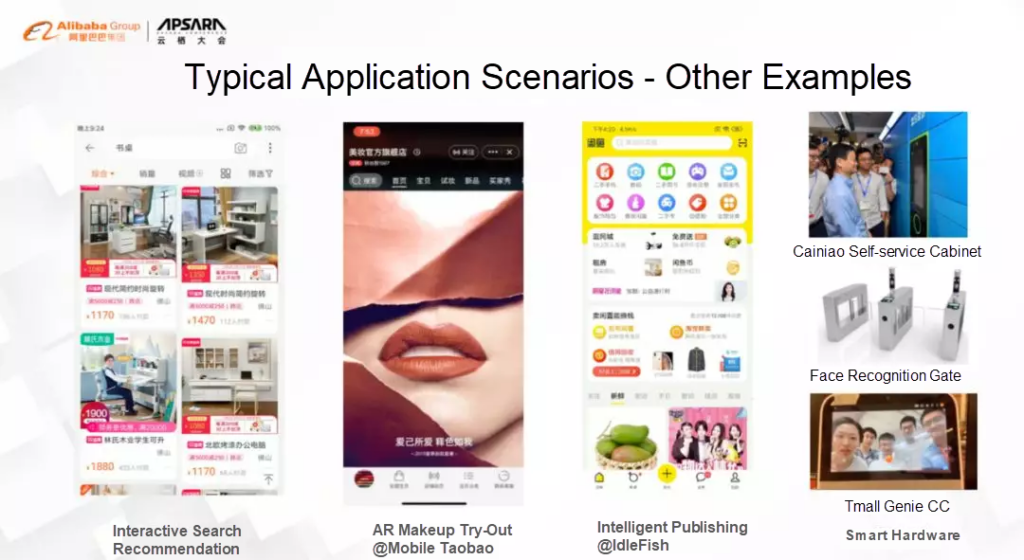
Putting MNN to good use
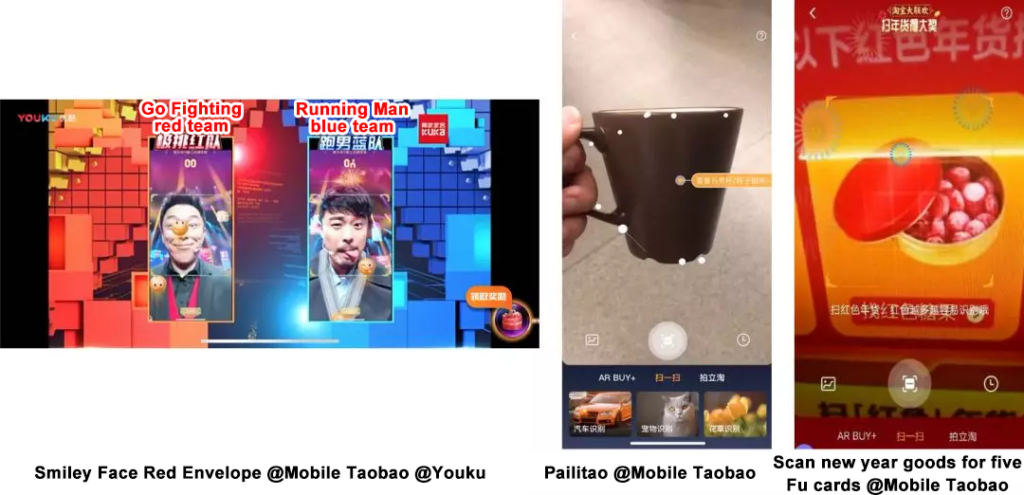
With a stable version being released every two months, MNN is currently being used in over 25 apps, a few better known of which are Taobao, Youku, UC Browser and Qianniu.
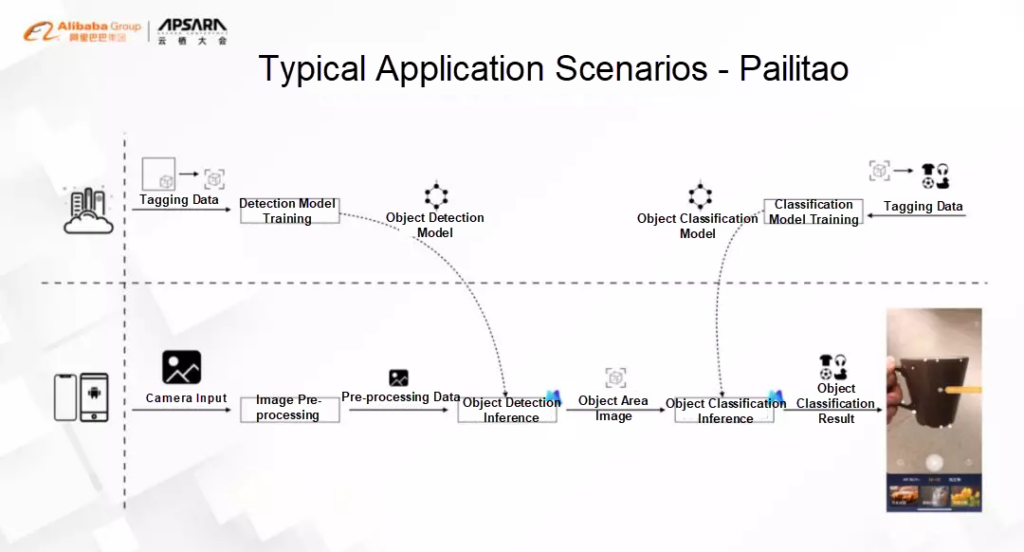
A notable utilization of MNN is for image search-based online shopping (i.e. visual search). Pailitao, an image search and recognition feature in the Taobao mobile app is a good example, having over 10 million unique users.
Originally, to search for an item, a picture needed to be taken and then uploaded to the cloud for image recognition. But with MNN, object recognition and picture editing are first performed on the mobile device itself, and the edited pictures are uploaded, significantly improving user experience and reducing compute cost on the server side. Similarly, it found use in real-time face detection and emotion recognition on the Smiley Face Red Envelopes show in 2018.
MNN has also found its way into big data problems. In a traditional big data system, the client is responsible for data collection, and the server is responsible for data calculation and mining.
Applications such as personalized recommendation engines are built on top of this scenario. However, with the constant increase in edge computing power, deep learning models can be deployed on end devices. One such application is context computing. Relying on multi-dimensional data from end devices, it is possible to correctly determine a user’s status, for example, if they are walking, riding in a vehicle, or lying in bed — a common feature in fitness and health apps.
MNN is quick and easy to use, having a Python tool chain to make it easy for developers to test and validate. Currently, Alibaba provides support for model conversion, model compression, model structure visualization, and tools that support OP list querying.
MNN is still evolving and being improved in many aspects—for example, applying auto-tuning during backend evaluation, integrating model compression tools (e.g. pruning) to slim a model on the fly, providing more tools for user convenience, and providing more language support including JavaScript and Python.
All in all, MNN lives up to the hype created by Alibaba and appears to be a fast, lightweight deep learning framework, battle-tested by a bunch of different application scenarios, and it possesses all the necessary qualities that constitute a powerful tool for mobile machine learning.
Comments 0 Responses