
There’s this farmer. His cows have stopped producing milk so he enlists a group of academics from the local university to help. The team arrives at the farm and the psychologists, mathematicians, physicists, and biologists start collecting pages of data, measuring and observing every move a cow makes.
One by one the academics leave telling the farmer they need time to analyze their data. At last there is one scientist left, a physicist. He walks over to the farmer, “I have a solution,” he says “assume a spherical cow…”
It’s a bad joke, but it’s an old chestnut in the physics community.
It highlights the natural tendency of physicists to make simplifying assumptions about phenomena so that the mathematical models they write are easier to solve. They don’t consider every little detail, but their models help us understand fundamental dynamics about the world.
Sometimes I feel like we need some more spherical cows in deep learning. Neural networks “work” in that they produce accurate predictions or useful outputs, but we don’t know a whole lot about why. VGG16, a popular convolutional neural network used for image recognition, has over 138 million parameters that must be tuned during training. The Standard Model in particle physics — one that does a pretty good job of describing most of the observable universe — has just 32.
Physicists had a few-thousand year head start figuring out how the universe works, but they’re just now starting to make progress on neural networks. In 2016 (and revised in 2017), a group of professors from Harvard and MIT put out a paper that sheds light on the unreasonable effectiveness of neural networks. Their logic has the kind of elegance that drew me to physics as a college freshman. It seems too simple, too obvious, yet the math works: A spherical cow.
The neural network mystery
A one megapixel grayscale image contains 1 million pixels, each of which can be a value from 0–255. This yields 25⁶¹⁰⁰⁰⁰⁰⁰ possible ways to construct an image, more than the number of atoms in the universe. Yet we ask neural networks to look at an image and tell us the probability that it contains a cat, a person, or a spherical cow. It seems an impossible ask, but somehow, neural networks often get the answer right. These days, they are correct more frequently than a human.
That’s weird. Unreasonable. Creepy. How are neural networks able to find needles in a such an impossibly large haystack?
Laws of physics
The solution put forth by Lin et al. is conceptually simple. While it is possible to construct a nearly infinite number of images, most of the ones that we create are of objects that exist in the physical world. We take photos of cats, cars, and people. Those things are created and constrained by the laws of physics and the laws of physics are relatively simple. Remember, just 32 parameters describe most of the observable universe. In this light, we aren’t asking neural networks to learn any possible picture, but rather an extremely small subset of images created by simpler rules.
The formulas you were required to memorize in school could take an infinite number of forms, but they were all simple. The total energy of a single body, for example, depends on the square of its momentum, p². Most physical systems are like this. They can be described by low order polynomials with degrees between 2 and 4. Mathematically, then, in order for a neural network to “learn” a physical system, it just needs to be capable of learning low order polynomials.
To get any further, we need to take a deeper look at what neural networks are doing under the hood. A neural network is a function, f(x), that takes a vector, x, as an input and transforms it into another vector. Despite the descriptive names like convolution and max pooling, each layer of a feed-forward neural network applies its own mathematical transformation, turning the output of the previous layer into the input for the next. Take n of these layers and apply them in succession, and you have a function that can be described as follows:
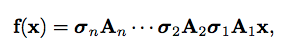
Sigma here represents a nonlinear transformation like softmax, while A is a linear transformation like A=Wx + b, the same calculation that occurs inside a dense layer with bias. It actually is that simple, just a series of matrix multiplications chained together.
Sparing you from more math, this fact leads to the following corollary: any multivariate polynomial can be approximated by an N-layer neural network where N is finite and bounded. In other words, we are guaranteed to be able to construct a feed forward neural network that approximates any polynomial function and with a reasonable number of parameters. The very functions that describe the physical world also happen to be the same ones neural networks are best at finding.
Neural network depth and hierarchy
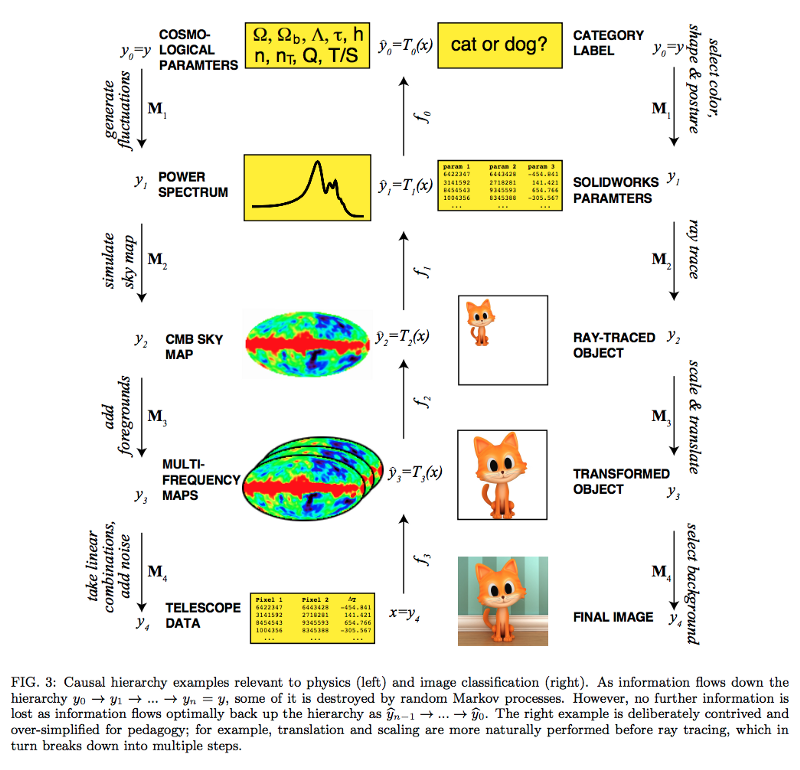
It turns out neural networks are actually so good at approximating low order polynomials with just a few shallow layers, that Lin et al actually need to look for a reason why deeper networks sometimes perform better. The real world, they suggest, is also deep. Single atoms combine to form molecules, which group together in cells, which make up organisms, and so on.
Hierarchical structures are everywhere, and there are causal mechanisms that determine how pieces combine at each level to create structures further down the line. We call these generative processes, and we can describe the hierarchy with compositional functions.
As an example, consider again the one megapixel grayscale image. It is made up of individual pixels. Let’s assume, though, that for some weird physical reason, each pixel is governed the rule: “pick a random integer between 0 and 255”. Despite the fact that this rule allows for more possible images than atoms in the universe, I was able describe a model to generate them with just 8 words.
The handful of parameters in the Standard Model describes the physics of nearly all particles. Like individual pixels, these particles combine to form larger and larger structures, each with their own set of physical laws. Mathematically this type of relationship can be described by compositional functions. We learn the functions at each level and nest them to describe the universe. A neural network trying to approximate the world at the same level in the hierarchy is really trying to approximate some compositional function.
We have just one more loose end to tie up, but it’s going to require a bit of math. For those readers whose eyes gloss over at equations, feel free to skip to the end. For the rest, you’re probably wondering why we can’t simply apply all of these compositions and arrive at a final, simplified model. For example, if we let f(x) = x² and g(x) = x + 1, then the composition of the two:
(g ∘ f )(x) = g(x²) = x² + 1
A deep neural network would learn f and g independently, but this seems like a waste. Why not just learn x² + 1 and call it a day? If the world were deterministic we could. But random noise and error get introduced at each step, and we’re trying to approximate functions given imperfect information.
Lin et al show that combining levels of a hierarchy into a single function destroys too much information and produces worse results. We’re better off trying to fit each level in the process. This leaves us with networks that are deep instead of shallow.
A nice perk of the undergraduate physics curriculum is that unlike biology or chemistry, the textbooks get thinner and thinner as you progress. In physics, the more you understand about the processes that generate the world, the less you have to memorize and the more you can derive. You can make predictions about where certain paths of research will lead with just pencil and paper.
Building a neural network today is still more art than science. Because we don’t understand enough about why they work, we’re left with little tips and tricks that seem arbitrary, errors that are hard to troubleshoot, and many wasted experiments. Spherical cows don’t seem useful at first, but by resisting the urge to tinker and hack our way to slightly better results, we can end up with more productive ways of thinking.
Neural networks work because physics works. Their convolutions and RELUs efficiently learn the relatively simple physical rules that govern cats, dogs, and even spherical cows. Their layers reflect the hierarchies we find in everyday life, organizing matter from atoms to galaxies. I’m excited to see how this framing can guide us to breakthroughs in the future.
Comments 0 Responses