
According to Statistica, 25.6 billion units of microcontrollers were shipped in 2019. There are over 250 billion microcontrollers in the world and this number is projected to grow over the coming years. As a result of this, deep learning on embedded devices is one of the fastest-growing fields.
This area is popularly known as tiny machine learning (TinyML). That said, embedded devices pose a couple of challenges, key among them being their low processing power and limited memory.
Machine learning models must therefore be able to work on just a few kilobytes of memory.
They must also be able to perform inferencing with the low processing power available in embedded systems. In this piece, we’ll look at TensorFlow Lite Micro (TF Micro) whose aim is to run deep learning models on embedded systems.
TF Micro is an open-source ML inference framework that has been fronted by researchers from Google and Harvard University. It addresses the resource constraints faced with running deep learning models on embedded systems.
Applications of TinyML
The authors of the above TinyML article start by highlighting some of the applications of TinyML technology. Key among them being:
- Wakeword detection — waking up a device with a certain phrase, e.g., ‘Ok, Google.’
- Predictive maintenance — resulting from analysis and modeling of signals from microphones, sensors, and accelerometers, just to mention a few.
- Acoustic-anomaly detection.
- Visual object detection.
- Human-activity recognition.
Challenges Facing TinyML
Next, the authors highlight the major challenges faced when implementing machine learning in embedded devices. These include:
- There is a lack of a unified TinyML framework for embedded devices.
- Deploying models on embedded devices is slow.
- Vendors produce different hardware types, hence making it difficult to evaluate hardware performance.
- There is a lack of basic features such as memory management and library support.
The proposed TensorFlow Lite Micro (TF Micro) is aimed at solving these challenges.
TensorFlow Lite Micro (TF Micro) Design
The TF Micro framework has been designed with the following principles:
Minimize Feature Scope for Portability
This means that an embedded machine learning framework assumes that the model, input data, and output arrays are in memory. The framework should handle ML computations based on those values, meaning that the library will omit features such as loading models from a filesystem or accessing peripherals for inputs. This design principle is crucial because many embedded platforms don’t have a memory management mechanism as well as library support.
Enable Vendor Contributions to Span Ecosystem
As a result of device fragmentation, developers can’t build software that runs well on different embedded platforms. In order to tackle this challenge, the authors ensure that optimizing the core library operations is easy. They aim for ensuring significant technical support for developers. The authors also encourage submissions to a library repository.
Reuse TensorFlow Tools for Scalability
Exporting a model comes with its own set of challenges. Key among them being export errors that result from developers converting a model to a format that can run on an embedded device. Another challenge is the lack of support for some operations on the target device. It is also important to note that most models are trained on floating operations and these operations consume more space and memory and would therefore be unsuitable for an embedded device. This can be addressed by converting them to a quantized representation. This, however, increases the exporter complexity. To address these challenges, a converter is built on top of the existing TensorFlow Lite toolchain. This has been extended for deeply embedded machine learning systems.
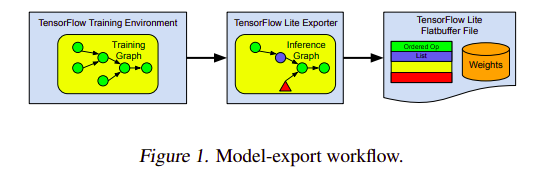
Build System for Heterogeneous Support
This feature aims at achieving a flexible build environment that doesn’t rely on any one platform. This would definitely encourage the adoption of TF Micro by developers.
TensorFlow Lite Micro (TF Micro) Implementation
Developing a TF Micro application involves a couple of steps. The first one is to create a live neural-network-model object in memory. The application developer starts by producing an operator resolver object via the Client API. The operator resolver controls which operations link to the final binary in order to reduce the size of the executable.
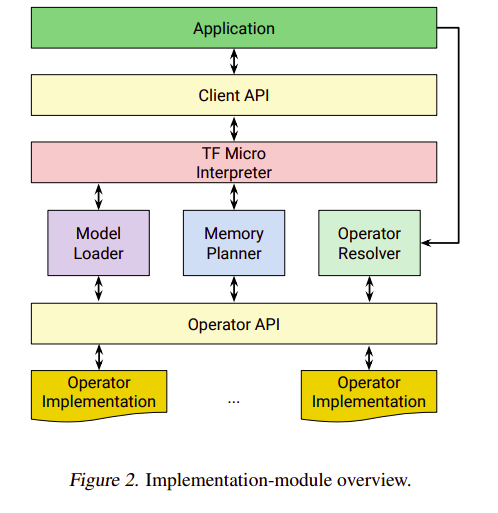
The second step is to provide a contiguous memory array referred to as the arena. The arena holds intermediate results and variables that are needed by the interpreter.
The third step is to create an interpreter instance. The instance arguments are the model, operator resolver, and the arena. During the initialization phase, the interpreter allocates all required memory from the arena. All communications between the interpreter and operators are handled by a C API. This ensures that operator implementations are modular and independent of the interpreter’s implementation.
The fourth step is the model execution. At this point, the application retrieves pointers to the memory regions that represent the model inputs. It then populates them with values mainly obtained from sensors or user-supplied data. With the inputs available, the interpreter is invoked so that it can perform model calculations.
Finally, the interpreter returns control to the application after it has evaluated all the operations.
Let’s now briefly look at some of the individual components.
TF Micro Interpreter
The interpreter loads a data structure that defines a model. Code execution is static but the interpreter handles the model data at runtime. The data controls which operations are executed and where model parameters are drawn from. The authors chose an interpreter based on their previous experience deploying models on embedded hardware. The interpreter approach (as opposed to a code generation approach) is advantageous for several reasons:
- Sharing code across multiple models and applications is easier.
- Maintaining code is easier.
- Allows updates without re-exporting models.
Model Loading
To enable the interpreter to load the data structure and the model, the TensorFlow Lite portable data schema is used. The model serialization format used is similar to the one used in TensorFlow Lite. The model representation used is the TensorFlow Lite representation.
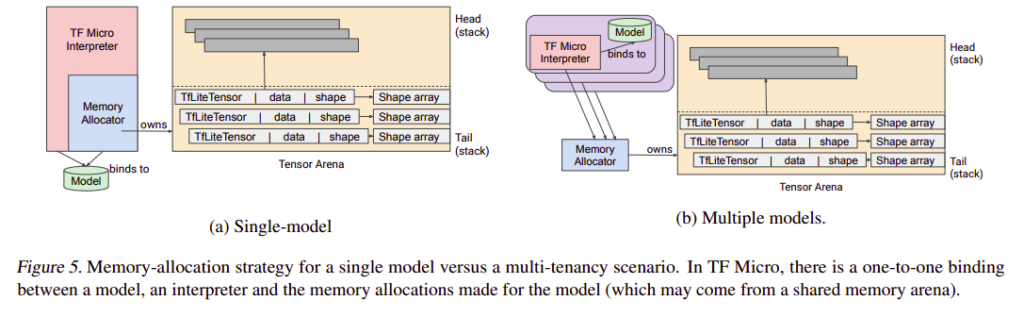
Memory Management
The framework allocates and manages memory from a provided memory arena. At model preparation, the interpreter computes the lifetime and size of all buffers needed to run the model. The buffers include the run-time sensors, memory for storing metadata, and memory for holding the values that the model runs on. With this at hand, the framework creates a memory plan. This memory plan ensures that all buffers are valid during their required lifetimes.
TensorFlow Lite Micro (TF Micro) Evaluation
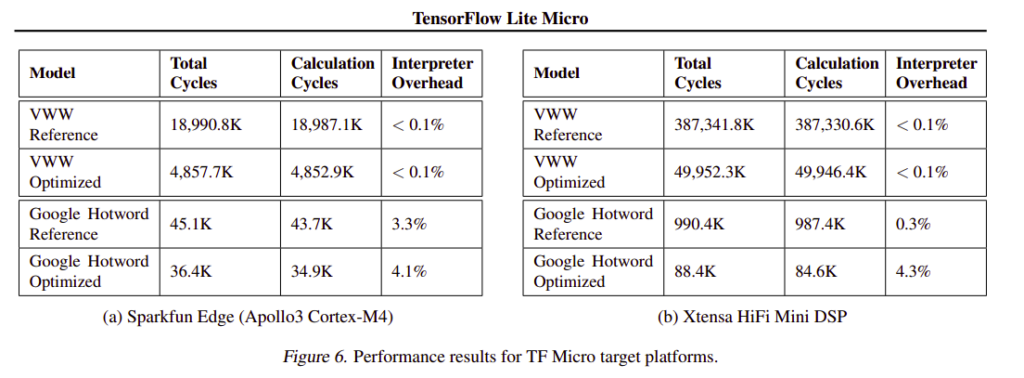
TF Micro has been deployed on processors based on the Arm CortexM architecture. It has also been ported to other architectures such as ESP32 and several digital signal processors (DSPs). TF Micro is also available as an Arduino library. The framework is evaluated on the Sparkfun Edge — an Ambiq Apollo3 Microcontroller Unit that is powered by Arm Cortex-M4 core and operates in burst mode at 96 MHz. The next platform that TF Micro is evaluated on is an Xtensa Hifi Mini DSP, which is based on the Cadence Tensilica architecture. It is evaluated on the Visual Wake Words (VWW) person-detection model (a microcontroller vision task of identifying whether a person appears in a given image). It is also evaluated on the Google Hotword model whose aim is to detect the phrase ‘OK, Google.’
The table below shows the results of those experiments.
Conclusion
TF Micro definitely presents a huge opportunity for the application of deep learning models on embedded devices. The framework can fit into tens of kilobytes on microcontrollers. It addresses key challenges facing the application of machine learning in embedded devices.
These are majorly hardware heterogeneity in the fragmented ecosystem, missing software features, and resource constraints. The framework also doesn’t require any operating system or even standard C or C++ libraries.
Tensorflow Micro is huge progress in the embedded machine learning ecosystem, but it’s only the start. The field is only poised to grow bigger and better.
Comments 0 Responses