
Introduction
I’ve recently been working a lot with video data—in fact, I’d already shared some learnings on a few deep learning-based video summarization techniques, in a recent article published on Heartbeat.
While I searched a lot for research papers that dealt with video summarization, I came across a paper that dealt with creating these summaries in the simplest way possible—by using the subtitles of a given video. You can check out the paper here.
First, the scripts are extracted from the subtitle files of the videos. Then, the extracted scripts are partitioned into segments. Finally, the partitioned script
segments are converted into a TF-IDF vector-based representation, which
acts as the semantic index.
This process is depicted in the flow diagram below:
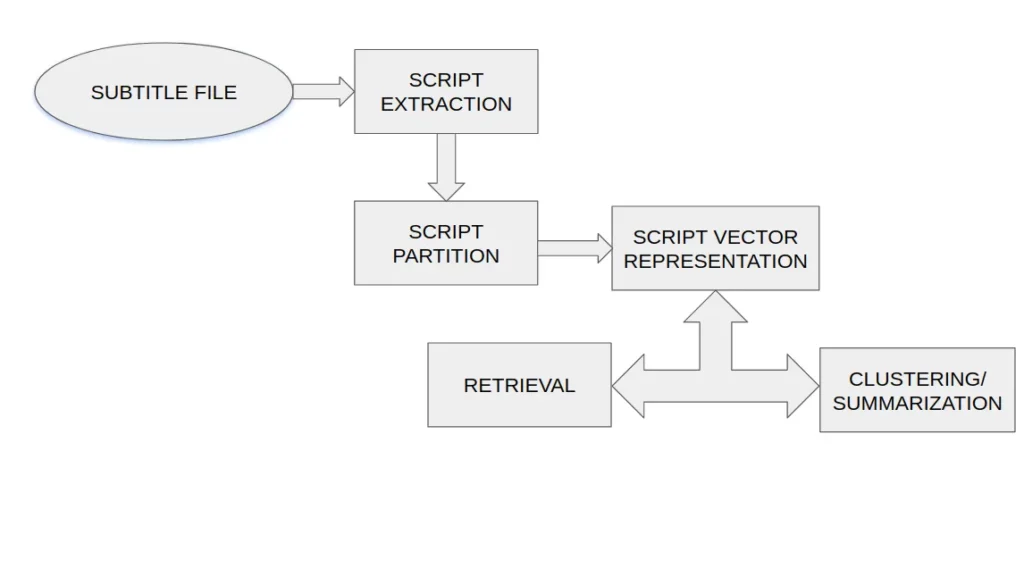
Diving Deeper
Video indexing is the process of providing watchers a way to access and navigate contents easily, similar to book indexing. And semantic video indexing is basically creating meaningful video summaries.
The methods for video summarization that we saw in my previous article are based on low-level visual or motion information, such as color or motion
activity. However, when humans deal with multimedia data, they prefer to
describe, query, and browse the content in terms of keywords rather than low-level features. Thus, how to extract information from digital multimedia is very important—although challenging—task.
The most popular method for extracting semantic information is to combine human annotation with machine learning. But such methods are semi-automatic and complex because the initial training set needs to be labeled by humans, and the learned classifiers may also need to be tuned for different videos.
Instead of discussing complex video processing algorithms in this article, we’ll look at a new approach to building the summaries for video content by analyzing the subtitle file.
Step 1: Conversion of .srt file to .txt file:
def srt_to_txt(srt_file):
""" Extract text from subtitles file
Args:
srt_file(str): The name of the SRT FILE
Returns:
str: extracted text from subtitles file
"""
text = ''
for index, item in enumerate(srt_file):
if item.text.startswith("["):
continue
text += "(%d) " % index
text += item.text.replace("n", "").strip("...").replace(
".", "").replace("?", "").replace("!", "")
text += ". "
return textThe subtitle file is parsed into script elements, where each script element has the following three attributes: ‘Start Time’, ‘End Time’, and ‘Text’. We use the information in the script elements to partition them in the next step.
Step 2: Script Partition:
def find_summary_regions(srt_filename, duration=30, language="english"):
""" Find important sections
Args:
srt_filename(str): Name of the SRT FILE
duration(int): Time duration
language(str): Language of subtitles (default to English)
Returns:
list: segment of subtitles as "summary"
"""
srt_file = pysrt.open(srt_filename)
enc = chardet.detect(open(srt_filename, "rb").read())['encoding']
srt_file = pysrt.open(srt_filename, encoding=enc)
# generate average subtitle duration
subtitle_duration = time_regions(
map(srt_segment_to_range, srt_file)) / len(srt_file)
# compute number of sentences in the summary file
n_sentences = duration / subtitle_duration
summary = summarize(srt_file, n_sentences, language)
total_time = time_regions(summary)
too_short = total_time < duration
if too_short:
while total_time < duration:
n_sentences += 1
summary = summarize(srt_file, n_sentences, language)
total_time = time_regions(summary)
else:
while total_time > duration:
n_sentences -= 1
summary = summarize(srt_file, n_sentences, language)
total_time = time_regions(summary)
return summaryIn a video, when there’s a dialogue or a long narration that extends to several frames, the script element gap is very small. Concurrently, it’s evident that script elements that constitute an extended narration will also have a high “semantic correlation” among themselves. Hence, we can see that the script element gap is a useful parameter by which to group together semantically relevant script elements, thereby creating a partition of the scripts.
Step 3: Script Vector Representation
After partitioning the scripts into segments, we build an index for each script
segment. We adopt the term-frequency inverse document frequency (tfidf) vector space model, which is widely used for information retrieval, as the semantic index for the segments.
The first step involves the removal of stop words, e.g. “about”, “I” etc. The Porter stemming algorithm is then used to obtain the stem of each word—e.g., the stem for the word “families” is “family”. The stems are collected into a dictionary, which is then used to construct the script vector for each segment.
The Final Step: Creating the Video Summary
def get_summary(filename="1.mp4", subtitles="1.srt"):
""" Abstract function
Args:
filename(str): Name of the Video file (defaults to "1.mp4")
subtitles(str): Name of the subtitle file (defaults to "1.srt")
Returns:
True
"""
regions = find_summary_regions(subtitles, 60, "english")
summary = create_summary(filename, regions)
base, ext = os.path.splitext(filename)
output = "{0}_1.mp4".format(base)
summary.to_videofile(
output,
codec="libx264",
temp_audiofile="temp.m4a", remove_temp=True, audio_codec="aac")
return TrueAfter the script extraction and script partition processes, the video summary is created, taking into account the most important keywords in the subtitle file.
Let’s Implement the Code
First, let’s create a virtual environment where all the dependencies will be installed, according to our requirements. Open the terminal and type in :
To activate the environment, type:
Here is the link to my GitHub repository where I have posted the code for creating a video summary :
You can clone the repository and unzip it in the folder where you created the virtual environment. I created my virtual environment in the documents folder and named my unzipped folder vidsummary1.
For the code to work, you’ll need to have the following packages installed:
If you don’t have these packages installed, then you can do so by running this command:
Usage
To generate a summary of a video file sample.mp4 with the subtitle file subtitle.srt:
To summarize a YouTube video from its URL:
If you want to retain the subtitles of the downloaded YouTube video, you can use this code snippet to do so:
Experimental Result
Our test data consists of a single episode from the popular TV sitcom Young Sheldon (season 3 episode 20). The following video is generated after performing summarization on it:
Conclusion
In this article, we covered the techniques and processes to create a video summary using a video’s subtitles:
- Script extraction
- Script partition
- Script vector representation
We’ve also worked through a simple Python implementation on our local system, for a video with subtitles that we already have, and also by downloading a YouTube video through its URL.
Comments 0 Responses