
If you went back in time—2 years ago, let’s say—and asked me to write an algorithm that could take an image of a hand and identify whether it’s making the symbol for a rock, paper, or scissors, I would have said, I doubt it, but give me 6 months.
Now if you ask me, I can direct you to https://rps-tfjs.netlify.com/ and say:
What?
Here’s a webpage that lets you do this right in your browser, using your machine. The speed will depend on the specs of your computer. But since it uses TensorFlow.js, all the heavy lifting happens in your browser and in JavaScript!
How?
Machine learning needs data, and a model architecture to train that data on. After some time training, the model should be smart enough to pick out photos of rock, paper, and scissors symbols that it’s never seen before.
The first thing we need is some training data for “Rock, Paper, Scissors” images. Don’t start calling all your hand model friends just yet. We can use some awesome data provided by Googler Laurence Moroney.
Thanks to Mr. Moroney’s dataset (linked here), we can train a basic model. He’s also teaching a Coursera specialization on machine learning that I’m quite enjoying!
How do we get the training data to the browser?
In a normal machine learning workflow, we simply access the files. We can organize files by folder and crawl them with a simple glob. But in a browser, we’re sandboxed to what is loaded in memory. If we’re looking at loading 10MB of hand images, it’s a significant barrier.
Fortunately, we can leverage a classic trick to transfer a group of images to a browser; a sprite-sheet. We glue a bunch of images together into one single image. In this case, every pixel in an image turns into a 1px high image, and we stack those on top of each other to create a single 10MB image that holds all our images.

I wrote my own sprite-sheet generator and ran it on the “Rock-Paper-Scissors” dataset. The result looks crazy to a human. You can see images like these:

transposed into a collection like so:

The Python source code is in this project’s spritemaker folder, so you can create your own sprite-sheets if you decide you want to do something similar with a completely different dataset.
Now that everything is combined into a single image, we can slice images off for training and validation.
Click buttons — receive browser training

As you press the buttons in the website, info will be populated to TFVIS, which stands for TensorFlow Visor. It’s basically a small slide-over menu that helps us show info as we train.
On the visor, we’ll see a random array of 42 hands from the dataset shaved off as test data. The data is in RGB, but if we open constants.js, we can move the number of channels down to 1 and just work in black and white if we’d like.

Additionally, we’ll see the model layers, untrained results, training stats, and trained results in this side-menu.
The model you create:

I’ve got a simple one that’s perfect for this simple data, and an advanced one that would be more useful with real-world photos of fingers from many angles and backgrounds.
Teachable moment
You might be thinking: “Let’s just always use the most advanced model”, which is a common pitfall. If you select the advanced model, you’ll see several things. Firstly, it takes longer to train, and second, it doesn’t even do as well. One more thing you can notice is that if you train for too long, the advanced model will start to overfit the training data.
A good machine learning model can generalize.
While training the model, you’ll get a graph that gets updated every batch (in this case every 512 images), and another graph that gets updated once each epoch (all 2100 training images).
A healthy training round means the loss goes down, and the accuracy goes up, i.e.
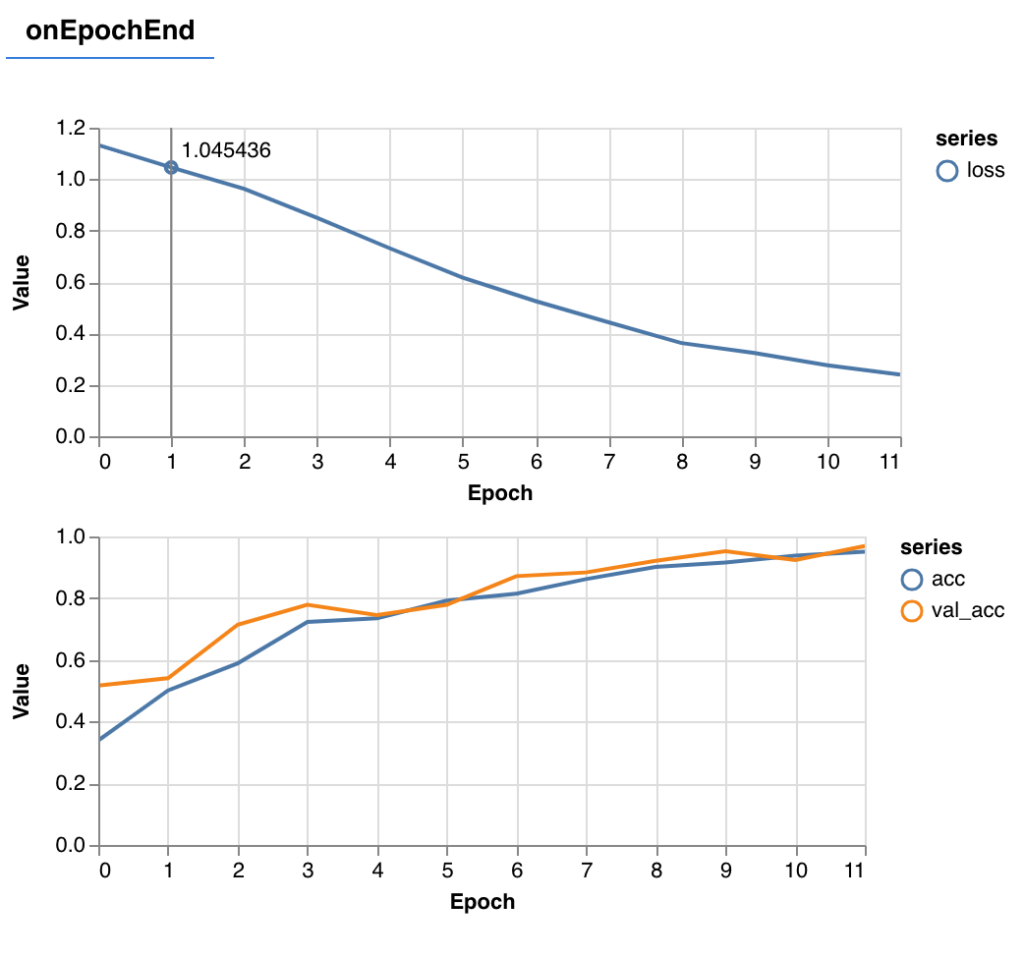
The orange line in the accuracy graph is a representation of the validation data; i.e., how accurate was the model with the 420 remaining images that the model is NOT trained on. Seeing that orange line ride alongside the training accuracy is great! Our model should generalize well (as long as the new images are similar in complexity and style).
If we click “Check Model After Training” we can see some healthy results!
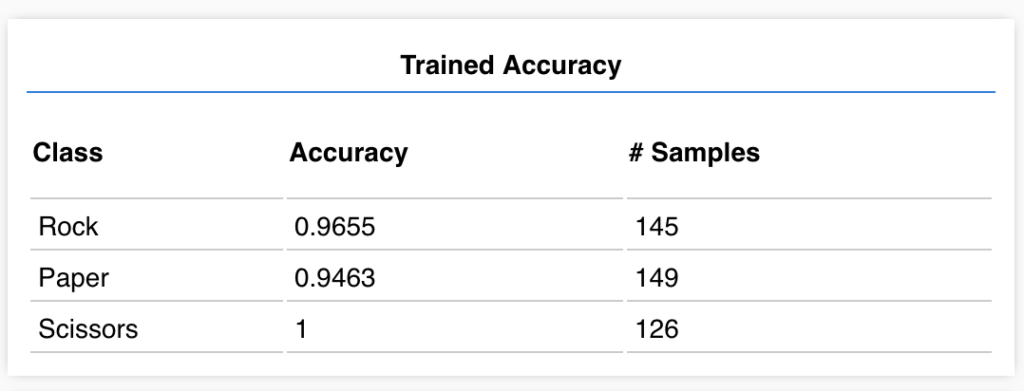
As you can see, Scissors is always accurate, and our worst class is Paper, which is only 95% accurate.
To dig a little further, we get a confusion matrix, too.
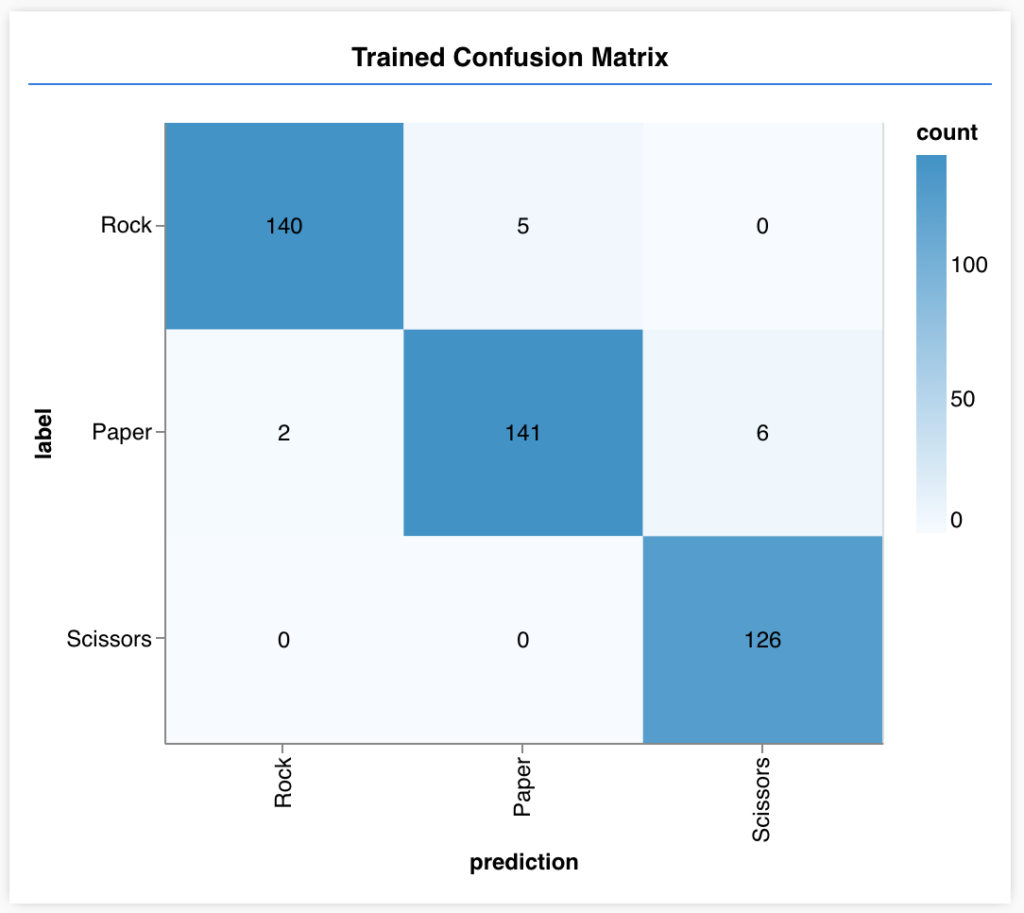
As you can see here, Paper has accidentally been categorized as Scissors 6 times. That makes sense—sometimes paper can look a bit like scissors. We can accept the results…or train more! Confusion matrices like the above help us figure out what kind of problems we need to fix.
Now we can finally test our model in the real world. Using a webcam, we can check our own hands for rock-paper-scissors! Keep in mind, we’ll want our photos to appear similar to our training images in order to have any reasonable functionality (no rotation, and a white background).

The webcam will snapshot and convert to a 64×64 image over and over with printed results.
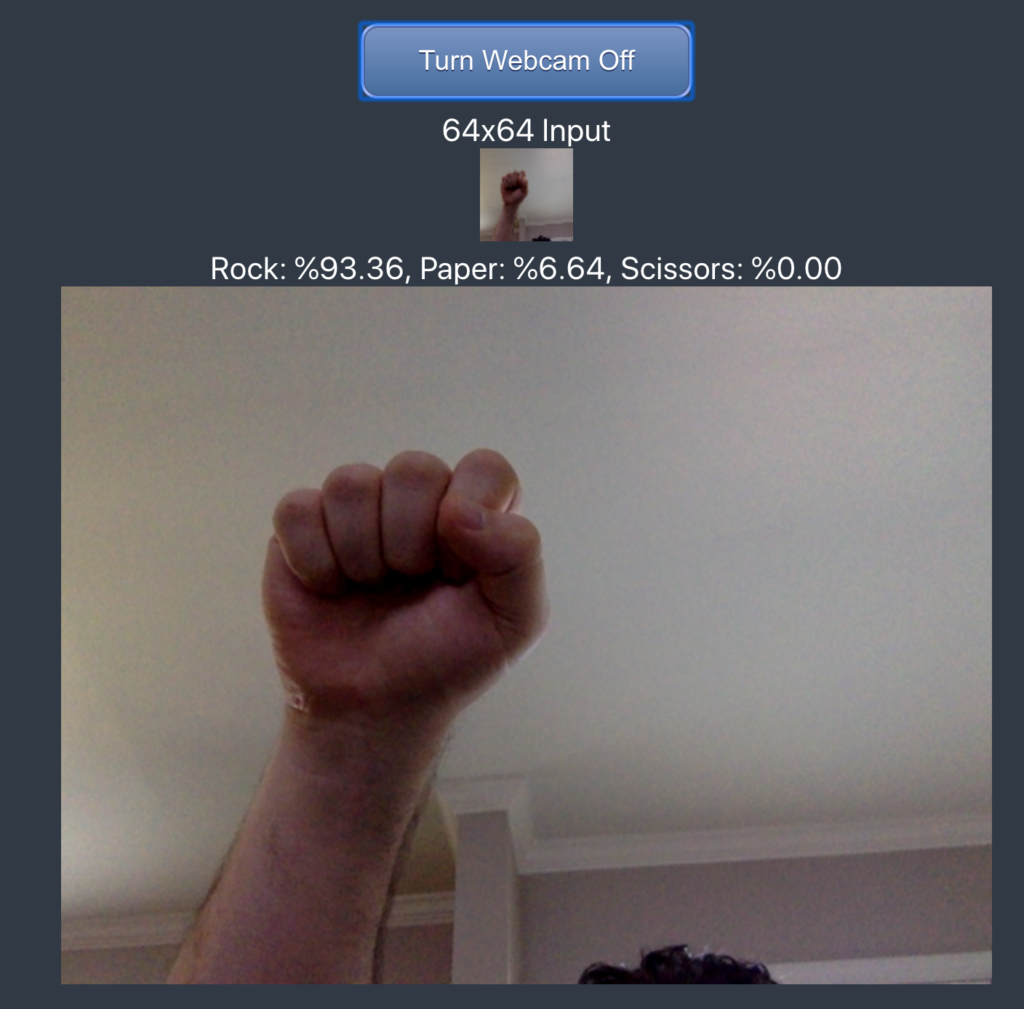
Congrats!
You’ve trained a model right in your browser, validation tested it, and even live-tested it! Very few people have ever accomplished this, and even fewer have done it all in the browser. Welcome to the forefront of some pretty awesome tech!
Here are some resources:

Full source code: https://github.com/GantMan/rps_tfjs_demo
Demo site: https://rps-tfjs.netlify.com/

Interested in learning how to bring AI and Machine Learning to web with TensorFlow.js?
JavaScript lets you create front-end websites that can leverage the power of AI directly on the browser. Learn from scratch with this book.
Reserve your copy on Amazon now
If you’re interested in learning more about TensorFlow JS, you can join our newsletter and eventually take our online course.

Gant Laborde is Chief Innovation Officer at Infinite Red, a published author, adjunct professor, worldwide public speaker, and mad scientist in training. Clap/follow/tweet or visit him at a conference.
Comments 0 Responses