
A couple of months ago, I wrote an article about training an object detection Core ML model for iOS devices. What made this tutorial unique, though, was that I used a tool I’d built called MakeML, which allow you to start training neural networks literally in minutes. The only model type available to train in that version was a tinyYOLO based Turi Create model.
After publishing that post, many people wrote to our team letting us know that the Turi Create framework doesn’t include enough flexibility to train their models.
That’s why we’ve decided to add TensorFlow-based training, and since we’re focused on mobile platforms (iOS specifically), we’ve chosen a MobileNetV2 + SSDLite architecture.
Not so easy
Turi Create uses a TinyYOLOv2 architecture for object detection. From a high-level perspective, these two architectures (TinyYOLOv2 and MobileNetV2 + SSDLite) operate in a similar manner. They take an image as input and produce two tensors as output.
These tensors (multi-arrays, as Apple calls them) contain information about anchor positions, anchors to bounding boxes, transformations, and the confidences that the bounding boxes have particular classes within them.
These models are designed to make predictions for particular bounding boxes in an image (called anchors). 1917 anchors for MobileNetV2 + SSDLite, and 2535 anchors for TinyYOLOv2.
So ultimately, you’re receiving 2 tensors with the following dimensions:
- (Number of Anchors) x (Number of Predicted Classes)
- I4x (Number of Anchors)
The first tensor give us a prediction for every anchor and class. But these anchors (as a reminder, 1917 in SSDLite MobileNetV2 or 2535 for tinyYOLOv2) may not fit perfectly within the object.
So the second tensor gives us information about how we should tune our anchor to receive the perfect bounding box for our object.
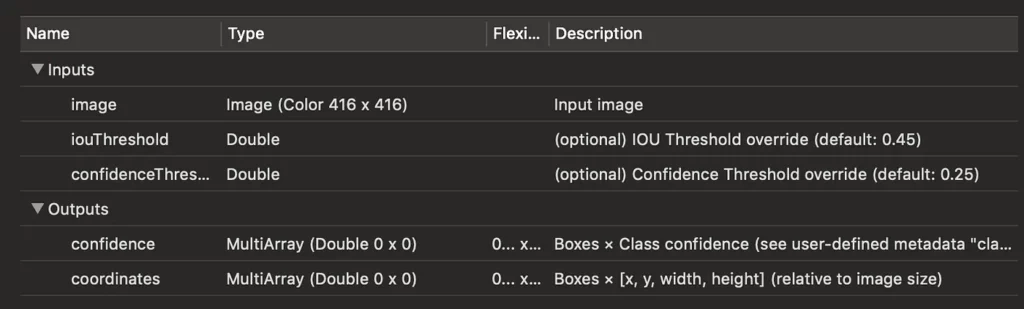
But as you can see, Turi Create’s model is giving us confidence and coordinates in ready-to-use box coordinates, and they give us just one bounding box for one object, instead of 5 bounding boxes, each of which contains some part of our object.
But when we’re training our model using a MobileNetV2 + SSDLite architecture, we’ll receive a model structured a bit differently, so we’ll need to apply some post-processing to the model to make it easier to use.
Post-processing consists of the following steps:
- HotConvert our TensorFlow model to Core ML using tf-coreml.
- Clean up the model to remove unsupported Core ML loops and unused branches.
- Create a new layer that will convert tensors to confidence and bounding boxes
- Create a non-max suppression layer
- Combine all 3 layers to receive a ready-to-use CoreML model.
All of this heavy lifting is handled by MakeML, so now we can train a MobileNetV2 + SSDLite Core ML model without a line of code.
First, if you haven’t already installed MakeML, you’ll need to do it 🙂
Here is the website, where you can download it. You can also follow the instructions from my previous tutorial to get up and running.
Once everything is setup, open the MakeML app and enter a unique project name and select “New Project From Training Configuration” button:
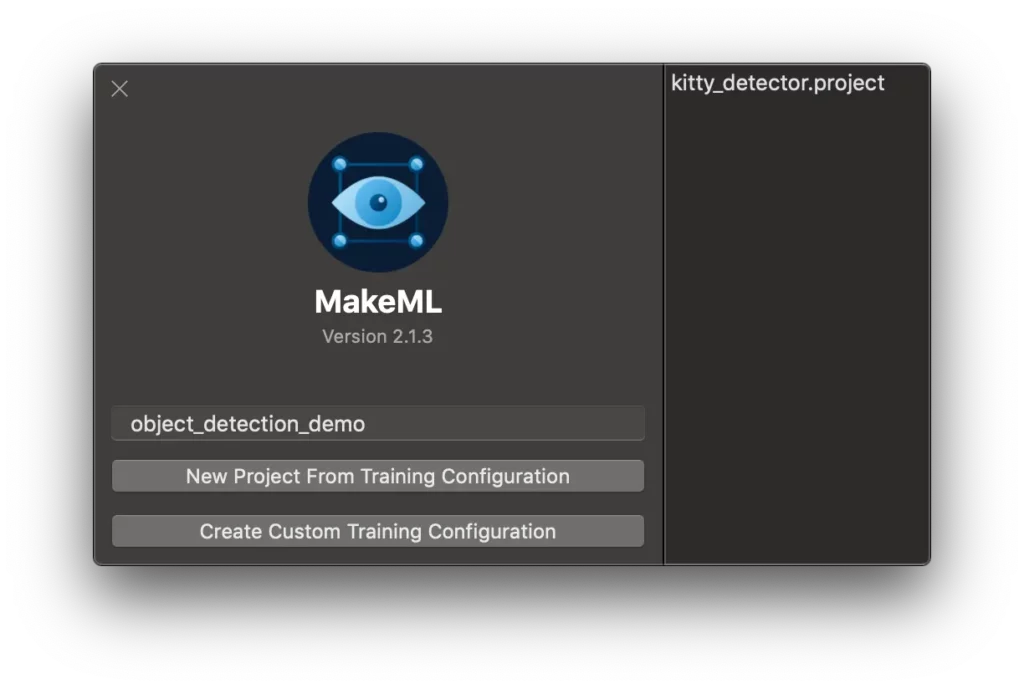
Select TensorFlow as the “Default Training Configuration” and press “Use Default Configuration.”
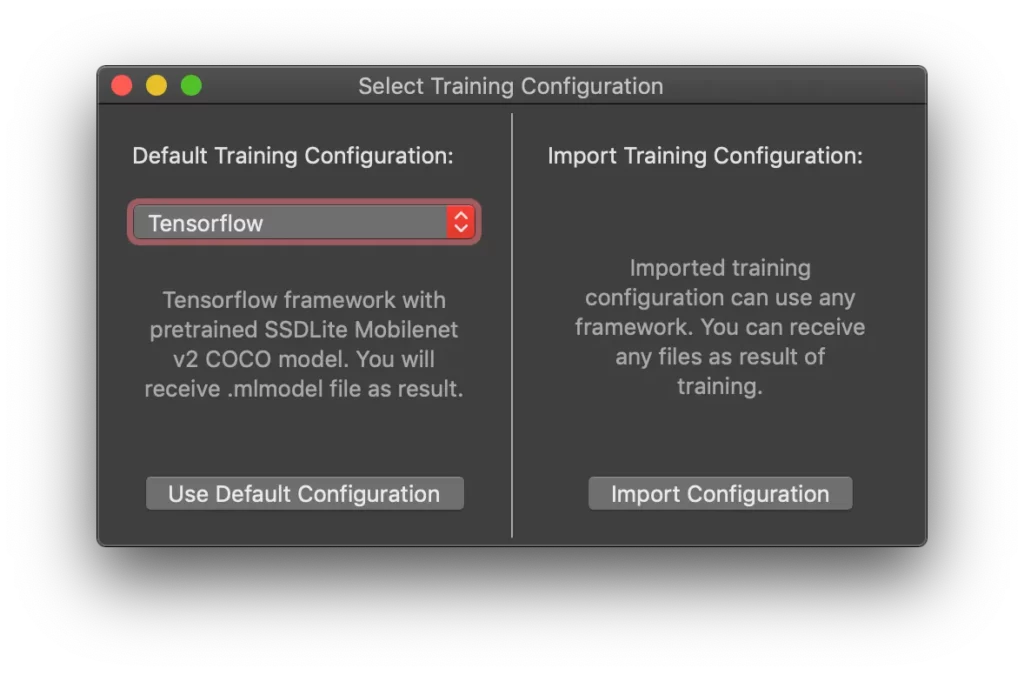
You’ll see the following window:
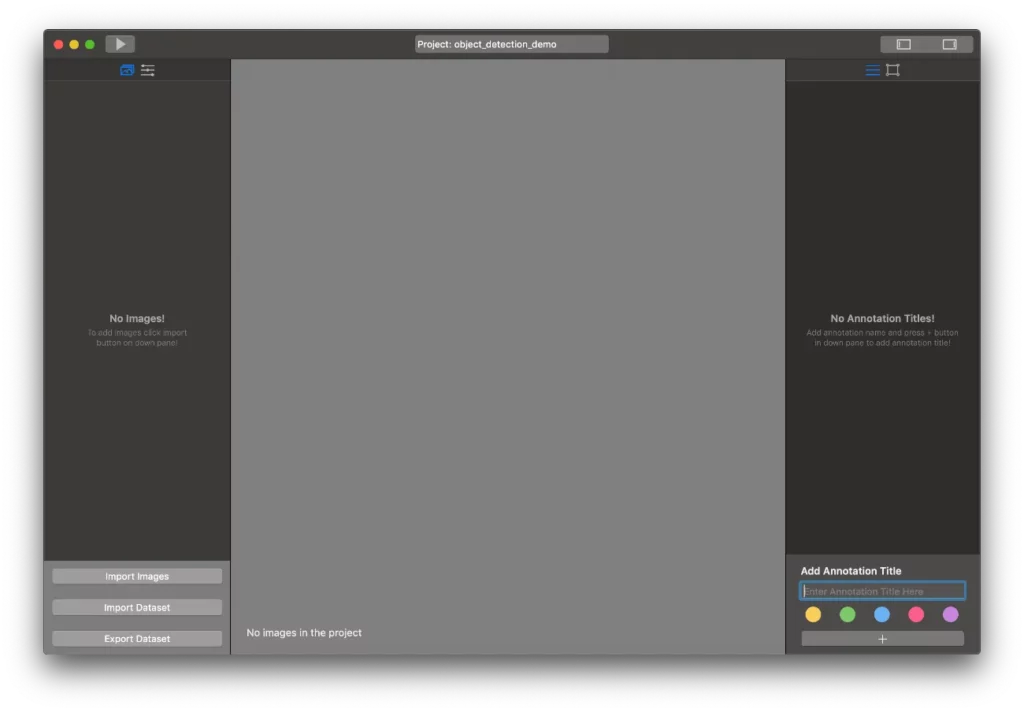
At this point, you’ll need to import your annotated dataset, or import images and mark them up inside the app.
When you’re ready, you can start your training in the cloud, or locally:
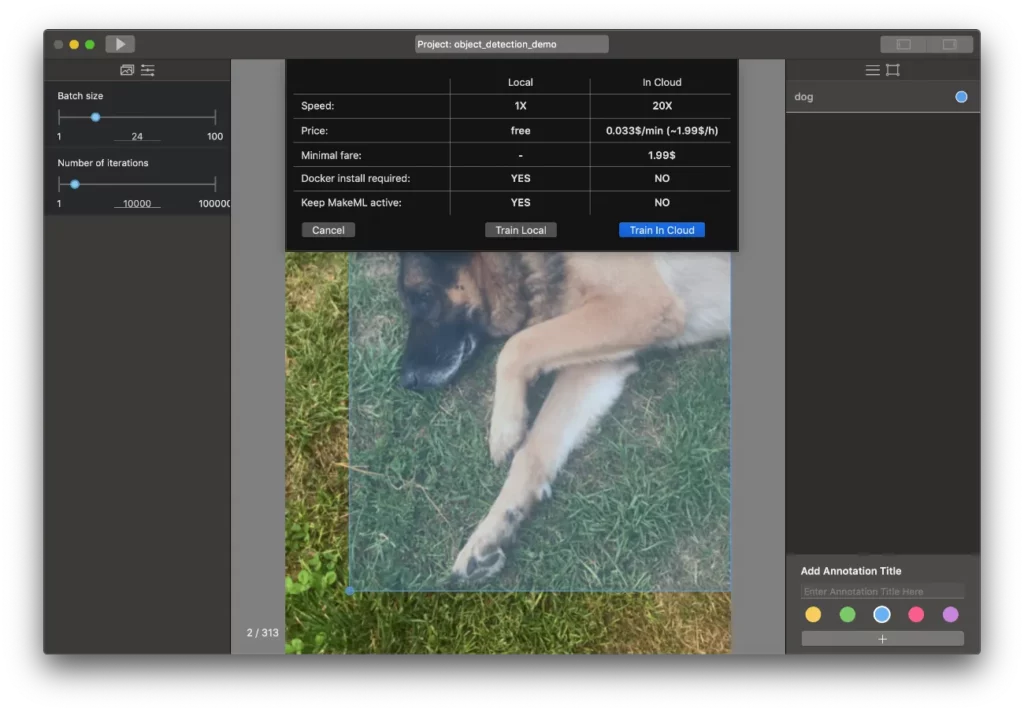
After this you’ll need to export the model as a model.mlmodel file. You can rename it as you wish. The easiest way to try this model is to download MakeML’s “Live Object Recognition CoreML iOS App” example, open the project, and insert your .mlmodel file inside the project. This will automatically generate Core ML access methods to your model.
The last thing to do in testing your model is to change name of the model in ObjectDetectionViewController.swift file (“Model” to “name_of_your_model”), as shown below:
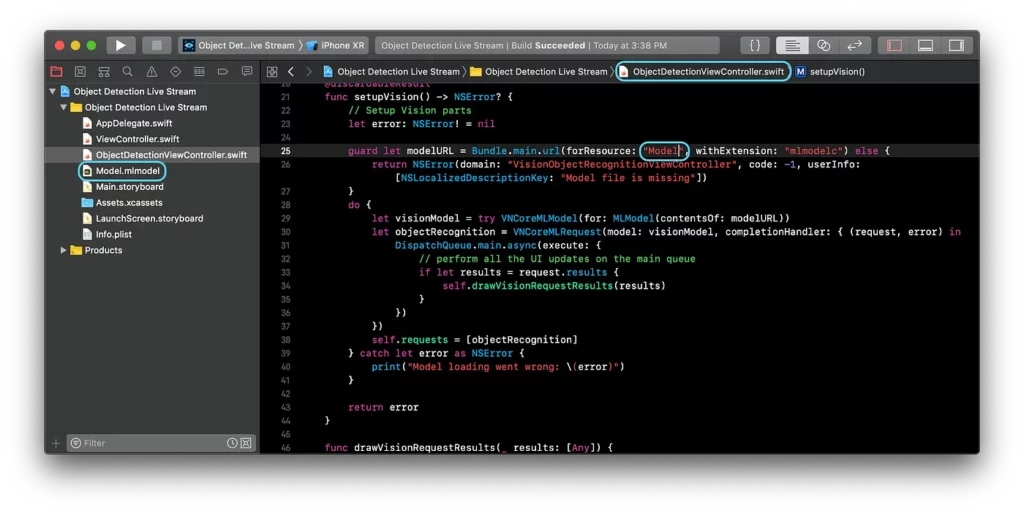
Here’s an example of a model we’ve received after training with MakeML:
In this article, we’ve learned how to train and use a MobileNetV2 + SSDLite model for object detection on iOS using MakeML, which allows you to train Core ML models without writing any code. I’ll be glad to hear any feedback from you in comments below.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Comet Newsletter), join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.
Comments 0 Responses