
In this post, we’re going to dive deep into one of the easiest and most interpretable supervised learning algorithm — decision trees. Decision tree algorithms can be used for both classification and regression. We’ll be discussing how the algorithm works, it’s induction, parameters that define it’s structure, and it’s advantages and limitations.
The Decision Tree Algorithm
A decision tree is an efficient algorithm for describing a way to traverse a dataset while also defining a tree-like path to the expected outcomes. This branching in a tree is based on control statements or values, and the data points lie on either side of the splitting node, depending on the value of a specific feature.
The structure of a decision tree can be defined by a root node, which is the most important splitting feature. The internal nodes are tests on an attribute. For example, if an internal node has a control statement (age<40), then the data points satisfying this condition are on one side, and the rest on the other. The leaf nodes belong to the available classes that the dataset represents.
The algorithm can be understood with the help of the following pseudocode:

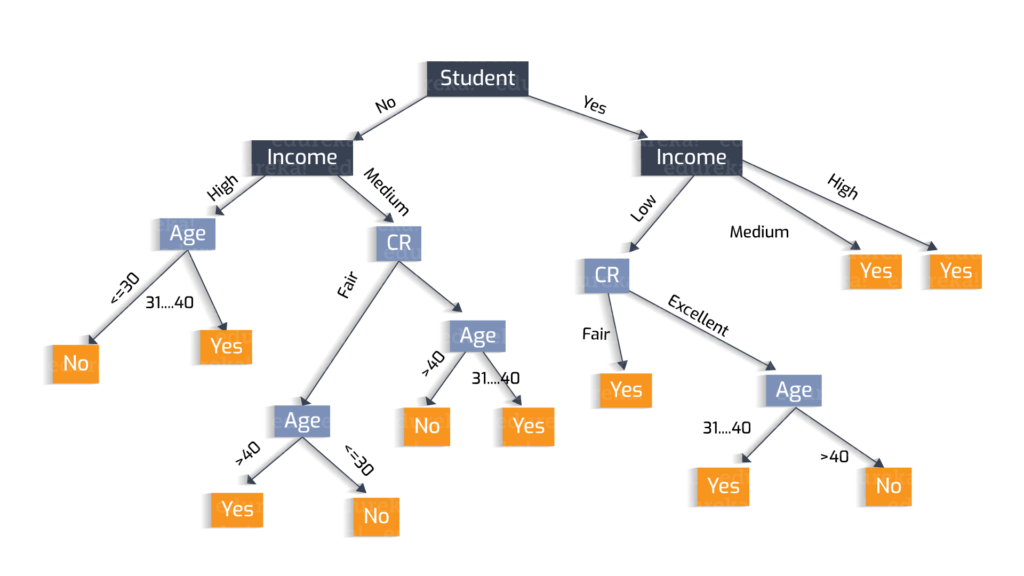
Example of decision tree induction
Applying the above algorithm for the problem of deciding whether to walk or take a bus, we can develop a decision tree by selecting a root node, internal nodes, leaf nodes, and then by defining step-by-step the splitting criteria for the class. We select the most important node as root node, which is weather. Depending on the weather and other conditions like time and hunger, we can build our tree as follows:

How do we know where to split?
An attribute selection measure is a heuristic for selecting the splitting criterion that’s most capable of deciding how to partition data in such a way that would result in individual classes. Attribute selection measures are also known as splitting rules because they define how the data points are to be split on a certain level in a decision tree. The attribute that has the best score for the measure is chosen as the splitting attribute for the given data points.
Here are some major attribute selection measures:
- Information Gain: This attribute provides us the splitting attribute in terms of the amount of information required to further describe the tree. Information gain minimizes the information needed to classify the data points into respective partitions and reflects the least randomness or “impurity” in these partitions.


pi is the probability that an arbitrary tuple in dataset D belongs to class Ci and is estimated by|Ci,D|/|D|. Info(D) is simply the mean amount of information needed to identify the class/category of a data point in D. A log function to base 2 is used, since in most cases, information is encoded in bits.
The information gain can be calculated as follows:

2. Gain Ratio: The information gain measure is biased toward tests with many outcomes. Thus, it prefers selecting attributes that have a large number of values. Gain ratio is an attempt to improve this problem.


3. Gini Index: The Gini index is calculated in the following manner:

where pi is the probability that a tuple in D belongs to class Ci and is estimated by |Ci,D|/|D|. The sum is computed over m classes.
The Gini index considers a binary split for each attribute. For example, if age has three possible values, namely {low,medium,high},then the possible subsets are{low,medium,high},{low,medium},{low, high}, {medium, high}, {low}, {medium}, {high}, and {} (ignoring the power and super set in our calculations).


Pruning
When a decision tree is built, many of the branches will reflect anomalies in the training data, due to noise or outliers. Slight changes in the values may result in completely different results.
Several methods are employed to eradicate this inconsistency, which is due to overfitting. Pruning the tree is one such method that typically uses statistical measures to remove the least reliable branches or the branches backed by a few number of samples.
Pruned trees tend to be smaller and less complex and, thus, easier to comprehend. They’re also usually faster and better at correctly classifying independent test data. Various techniques can be employed for pruning, such as pre-pruning, post-pruning, and pessimistic-pruning.

Implementing decision trees in scikit-learn
It merely takes four lines to apply the algorithm in Python with sklearn: import the classifier, create an instance, fit the data on the training set, and predict outcomes for the test set:
Parameter tuning in scikit-learn:
- max_depth: int, default=None. defines the maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
- min_samples_split: int or float, default=2. The minimum number of samples required to split a node—a minimum of 2 samples are required for splitting the node. Can be tuned as per the features and their values.
- min_samples_leaf: int or float, default=1. Provides information about the minimum number of samples required to be at a leaf node. This helps in smoothing the model.
Time and Space Complexity
Following the rules of data structures, the cost of constructing a balanced binary tree is O(n-samples*n-features*log(n-samples)) and time taken to query the tree is O(log(n-samples)). But since decision trees aren’t balanced, we need to assume that the subtrees remain approximately balanced.
The cost at each node consists of searching through O(n-features) to find the feature that acts as the best splitting attribute at the given level. This has a cost of O(n-features*n-samples*log(nsamples)) at each node, leading to a total cost over the entire tree of O(n-features*n-samples*2*log(n-samples)).
How Are Decision Trees Different from Rule-based Classifiers?
A decision tree is basically a well-developed set of conditional statements that can easily be converted into rule-based classifiers. But rule-based classifiers build rules based on a complete dataset, ignoring any scope of generalization by the model.
Thus, the model provides a default or wrong answer in cases of data points its never seen before, whereas decision trees are pruned and not grown as pure leaf nodes. This lets the model generalize and provides it a learning scope.
Advantages of Decision Trees
- Interpretable and Simple: Decision trees are able to generate understandable rules. The trees are simple to understand and to interpret and can be visualized.
- Handle all kinds of data well: Decision trees can handle both numerical and categorical data, making them widely-useable.
- Non-Parametric: Decision trees are considered to be non-parametric. This means that decision trees have no assumptions about the data points’ space or the classifier’s structure, nor is there a need for assuming any seed values.
- Robust: Decision trees require less effort from users for pre-processing data. They aren’t influenced by outliers and missing values either.
- Fast: The cost of using the tree (i.e. making predictions) is logarithmic in the number of data points used to train the tree.
Disadvantages of Decision Trees
- Overfitting: Overly complex trees can be developed due to overfitting. Pruning, setting the minimum number of samples required at a leaf node, or setting the maximum depth of the tree are necessary steps to avoid this problem.
- Instablility: Decision trees can be unstable because small variations in the data might result in a completely different tree being generated. Ensemble techniques like bagging and boosting can help avoid such instabilities in outcomes.
- Bias: Decision tree learners create biased trees if some classes are more likely to be predicted or have a higher number of samples to support them. Balancing the dataset before decision tree induction is a good practice to provide every class with a fair and equal chance.
- Optimality: The problem of learning an optimal decision tree is known to be NP-complete, since the number of samples or a slight variation in the splitting attribute can change results drastically.
How to Prepare Data for Decision Tree Modeling
- Decision trees tend to overfit on data that has a large feature space. Selecting the right number of features is important, keeping in mind the size of the dataset, since a tree with a smaller dataset in high-dimensional space is very likely to overfit.
- Consider performing dimensionality reduction (principal component analysis or feature selection) to get a better idea of redundant, useless, correlated, or discriminative features.
- Use min_samples_split or min_samples_leaf to ensure that quite a few samples support a decision in the tree, while keeping in mind the splitting attributes. A very small number will usually mean the tree will overfit, whereas a large number will prevent the tree from learning the data.
Sources to Get Started with Decision trees
Conclusion
In this post, we read about decision trees in detail and gained insights about the mathematics behind them. They’re widely used and strongly supported, and we covered their advantages and limitations.
Let me know if you liked the article and how I can improve it. All feedback is welcome. Check out my other articles in the series: Understanding the mathematics behind Naive Bayes, Support Vector Machines ,Principal Component Analysis and K-means clustering.
I’ll be exploring the mathematics involved in other foundational machine learning algorithms in future posts, so stay tuned.
Comments 0 Responses