
In these unprecedented times involving a worldwide pandemic, many changes have taken place in our daily lives. To ensure the safety and well being of all, many protocols and guidelines have been implemented across society, such as maintaining a minimum distance or limiting physical contact with exposed and shared surfaces.
Businesses are getting creative by adapting their shopping experiences to ensure the safety of their customers and employees. Contactless services have become more of a necessity than a fad, and technology has evolved to keep pace with these newfound demands. Many stores have standardized Scan & Go technology, which allows customers to scan item barcodes and pay using just their smartphones, thus limiting human contact and providing a faster, simpler alternative.

An ML-enhanced experience
Progress in computer vision, combined with the portability of smartphones, has led to newer and safer approaches to traditional shopping methods.
Dedicated barcode scanners that need to be shared among store employees are now being switched out for smartphone apps, and augmented reality is playing a bigger and bigger role in new store management approaches, transforming routine tasks such as counting inventory and restocking shelves. Scandit is one such app that is using ML-powered methods like text and object recognition to power contactless working in shops and stores.
The onset of the pandemic has shown logistics companies the value in using ML-powered apps on personal smartphones, thus allowing staff and customers to practice social distancing guidelines more easily.
Computer vision has also played a crucial role in the health industry, using similar principles to help healthcare workers handle clinical samples and supplies without physical contact. Retail, transport, and manufacturing are some of the other businesses taking advantage of these features, with use cases such as inventory management, airport baggage handling, deliveries, and more.

The issue is that the possibility of coronaviruses to remain on exposed surfaces or in the air for extended periods of time, making it very risky in the current situation to physically touch unfamiliar surfaces or spend too much time in crowded indoor spaces.
A better alternative is to use a more familiar touchscreen — that of your own smartphone, which has a much lesser chance of having interacted with multiple people physically.
Improved experience with on-device AI
With a growing number of ML-related activities taking place locally on devices day after day, computer vision-based tasks such as object detection are also no stranger to this new trend.
Coupled with the growing compute power of smartphones and new tech such as dedicated “AI” chips, the efficiency of machine learning tasks that take place entirely on user devices without reaching out to a cloud server has only increased in recent years. Product recognition at stores is one such example of a model running entirely locally.

Let’s have a look at Lookout, an Android app by Google that uses computer vision to assist people with visual impairments by doing tasks such as scanning documents and reading them aloud. However, its uses go beyond that in many respects. For example, it has a quick read mode that can skim text and prepare a label showing its context, which is useful when it comes to doing things like sorting mail.
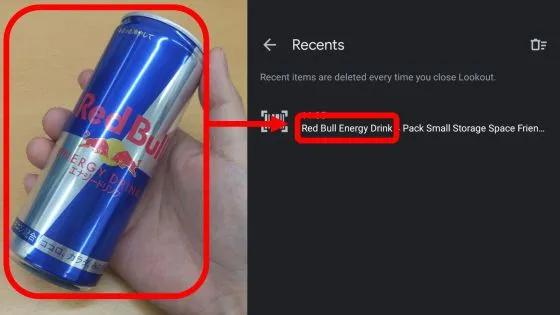
Lookout includes a supermarket product detection and recognition model with an on-device product index, along with MediaPipe object tracking and an optical character recognition model.
The resulting architecture is efficient enough to run in real-time, entirely on-device. While an on-device system like this comes with its usual perks, such as low latency and no reliance on network connectivity, it does need to have a local database covering supermarket products. For Lookout, Google provides a dataset within the app data—a dataset that includes over a million popular products, chosen according to the user’s geographic location range.
The app supports most Android smartphones and is available on the Play Store, with support for 20 different countries. Upon installation, it prompts you to install an additional 250 MB of data, which is presumably the dataset of items it’s trained to recognize.
It worked fairly well for me, readily identifying most of the items in my household. There is an Exploration (beta) mode as well, where the app will verbally recite whatever the camera is pointed at. I tried all of this out while offline, and the app didn’t seem to have any hiccups at all.
Traditional ML vs. newer approaches
Non AI-based approaches, besides not being very reliable, are also expensive with regards to storage requirements. They typically rely on extracting features from individual images of products (objects), thus having to maintain said images within memory — a stress on memory if we assume an image of average quality would consume around 10 kB.
In contrast, conventional deep learning algorithms such as OCR use such images to run inference with a model connected to cloud data servers, which severely reduces the margin of error when it comes to spelling mistakes, misinterpreted images, or failed object recognition. They also typically implement measures such as the Jaccard similarity coefficient, which allows for partial image matches.
According to the latest research at Google, their neural network-based approach generates a global descriptor for each image, which requires only 64 bytes, maximizing storage efficiency, which in turn contributes to better local operation.
Internal architecture
Let’s dig a little deeper into the product recognition pipeline’s internal design structure.
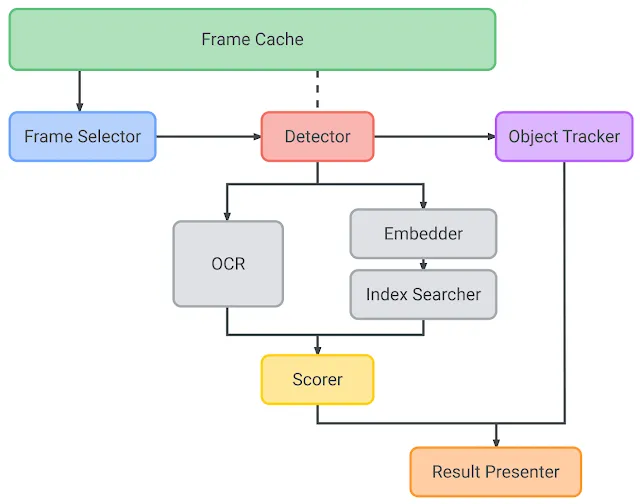
According to this system diagram from the Google AI blog shown above, the design can be broken down into nine major components:
Frame-Selector — The selector component comes into play when the user points the camera towards a product, acting as a filter. Its purpose is to select frames from the mobile vision stream that satisfy certain quality criteria (such as white balance).
Detector — The selected frames then go on to an ML model whose function is to zero in on the individual regions of the image that are of interest. In other words, this step imposes the conventional bounding boxes on the image frames. In the Lookout app, this is an MnasNet model.
Cache — The system has its dedicated cache reserve for the stream images and can be called seamlessly by the other system components. To capitalize on memory saving, the cache has protocols to avoid duplicate or redundant frames.
Object tracker — Once the frames have had bounding boxes drawn on them, the live stream tracks the detected feature point in real time using MediaPipe Box tracking.The object tracker maintains an object map where each object gets assigned a unique ID, allowing for better differentiation between objects and reducing redundancy, due to duplicated objects in memory. If an object is repeated in the stream, the object tracker will simply update the ID, depending on the bounding box.
Embedder — The embedder is a neural network trained from a large classification model spanning tens of thousands of classes. It has a special “embedding” layer that projects the input image into an ‘embedding space’. The notion here is to tune the network to recognize that two points being close within this space means that the images they represent are visually similar (for example, different images of the same product)
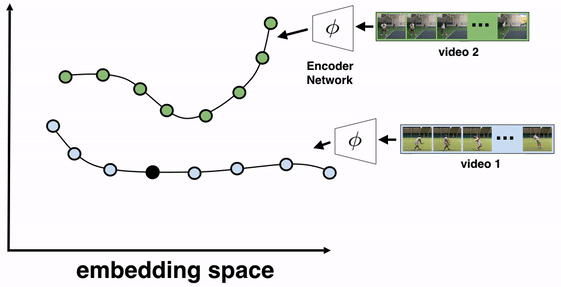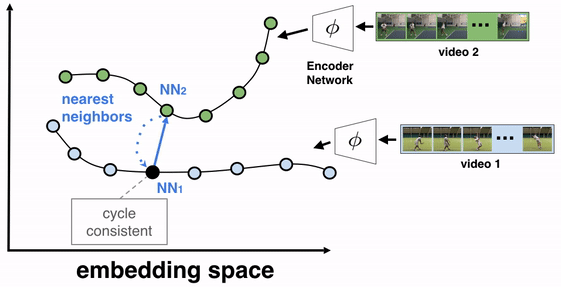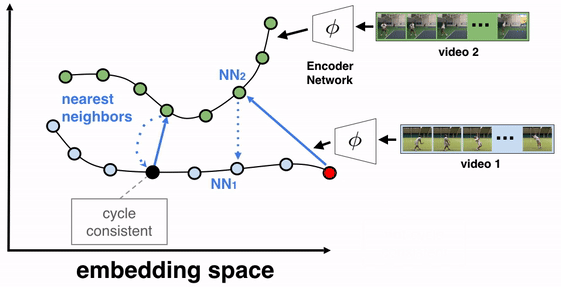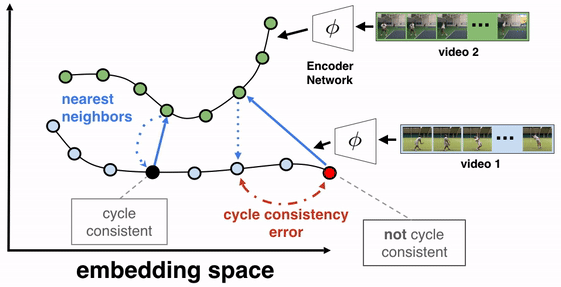
Here’s where the researchers get creative — Since the model is way too large to be used on-device, the vectors resulting from this “embedding space” are used to train a smaller version of the model. They refer to the original model as the ‘teacher model’ and the smaller, mobile-friendly version as the ‘student model’. To further reduce allocated memory, principal component analysis helps to reduce the overall dimensionality.
Index searcher — This component is tasked with looking up the relevant results for the image patterns. It performs a KNN search using the features as a query and returns the highest-ranked index containing the matching metadata, such as brand name or package size. Low latency is achieved by having the indexes clustered using the k-means algorithm.
OCR — There is also an OCR component with the bundle. However, while traditional ML algorithms focus on using OCR for primary index searching, its purpose here is to aid the system to refine results. OCR helps extract additional information from the frames (for example: packet size, product flavor variant, etc.) To this purpose, a score is assigned to it, with the help of a scorer component, which improves precision.
Scorer — The scorer component assigns scores to the results obtainer from the index searcher, assisted by the OCR to achieve more accurate results. The result with the highest score is used as the final product recognition displayed to the user.
Result presenter — This is a UI component whose job is to present the final result to the user. This can be done via the app GUI or a speech service.
Key Takeaways
While this product recognition system was originally implemented to help users with visual impairments that make it difficult to identify packaged products on display, it can be a useful tool during the ongoing COVID 19 pandemic, as well.
It can help replace the need to physically touch a product on display, allowing customers and store employees to examine packaging information by simply using their smartphone instead. Since the computer vision tasks required for this activity are performed completely on-device, hurdles such as internet connectivity or latency issues do not come into play. The on-device functionality in a product recognition app such as this can be used to usher in various in-store experiences, such as displaying more detailed facts about products (nutritional information, allergen warnings, etc.).
This is just one of many steps that Google is taking to further on-device machine learning. Google’s Pixel 4 smartphone, released last year, was certainly a milestone in the field, featuring the Pixel Neural Core with an instantiation of the Edge TPU architecture, Google’s machine learning accelerator for edge computing devices. Google has also developed next-generation models such as MobileNetV3 and MobileNetEdgeTPU to advance on-device computer vision.
Comments 0 Responses