
For the last few months, I’ve been working on my own machine learning model to predict what kind of coffee (hot or iced) I should drink on any given day, based on a variety of factors.
I’ve become very interested in machine learning over the past year, and so I wanted to build something to help me learn—so I built an app (or 2)!
Table of contents
Overview
I’m obsessed with coffee. I have around 1–2 cups a day, sometimes because I can’t function without it, or sometimes just because I feel like I should have some.
But I’m pretty picky about what kind of coffee to have and when. Generally speaking, I like to have hot coffee when it’s cold outside and iced coffee when it’s warm. But it has to be the RIGHT temperature with the right weather conditions.
For example, if it’s 70 degrees out, I’ll have iced coffee, but if it’s 70 degrees out and raining — well, its hot coffee time! In contrast, if it’s 60 degrees out, I’ll most likely have hot coffee, but if it’s nice and sunny, I may have iced coffee. My brain just can’t seem to stick to one or the other.
My guess is that others have this problem, so I wanted to build an app that takes the guesswork out of what coffee to drink.
When I first went about building this, I figured I could just use a whole bunch of if/else statements:
But since there are so many different scenarios, I figured this wouldn’t be the best (or most fun) way to build it.
Which led me to machine learning…
For the past year, I’ve been kind of obsessed with machine learning. I remember exactly when I got hooked. I was at an AWS talk about Amazon’s MXNet and found myself amazed at what it could do.
From that moment, I wanted to learn about this. I’ve done a lot of reading, mostly on Medium, and I’ve taken the Deep Learning Nanodegree course on Udacity.
These were great resources, but in order for me to really learn something, I have to build it. So I did! And it’s still a work in progress. But I’m very excited about its possibilities.
iOS and Alexa Apps
Before building and training the model, I first needed data. But I haven’t seen any dataset on coffee drinking preferences. (If you see one in the wild, please let me know). So I then decided I’d have to obtain the data myself.
In order to obtain the data, I first had to build something that let me record my preferences.
I needed to be able to record when I drink coffee, what I drink, and the weather conditions. So I decided to do was build both an iOS app and an Alexa skill that does all of this.
The iOS app is open-sourced here and is available on the app store as well . It’s pretty simple, and it’s still a work in progress. But I’m pretty happy with the first version of it. This version obtains the user’s current location, looks up the current weather conditions using OpenWeatherMap, and lets the user select the type of coffee they’re having, which is all saved to Firebase.
The Alexa app, which is also open-sourced, is available as a skill here:
The Alexa skill detects the users’s current location (note, I’ll have another post on how I did this soon), and lets the user say what kind of coffee they’re drinking,
or
It retrieves the current weather conditions at the users location, saves the coffee preference, hot or iced, and saves the data to firebase. The skill is available to use now!
Pretty cool huh?
Building the Dataset
So after building both the iOS app and Alexa skill, I had to start recording my preferences, which I’ve done for the better part of the past year. Currently, I have more than 500 rows of data, which is a pretty good start. I generally have 2 cups a day. I also have a good friend who likes coffee almost as much as I do, and they’ve been helping out adding their preferences via the iPhone app. I’ll have more data when other users (like yourself) download the app and save your preferences!
I’ve made the dataset available on Kaggle for anyone to view:
Let’s start analyzing this data! First, we need to download it from Firebase. I won’t go into detail of how this is done, but here’s a link to the full script:
Basically, I download the Firebase data, cleaned up the data, and wrote to a csv for processing.
In order to build a very accurate model, I spent more than 1 month just cleaning the data and deciding what features would be best to train the model. I had gone through a few iterations to see what features would work best. Eventually, this is what I decided on.
First, I dropped the columns that wouldn’t help with the prediction:

Then, I decided was to round the temp and windSpeed columns to the nearest integer, which helps the model better predict new values.

Next, I only included the same amount of rows for both hot and iced coffee. My dataset had way more ‘hot’ samples than iced. This is because I started recording my data in the winter.
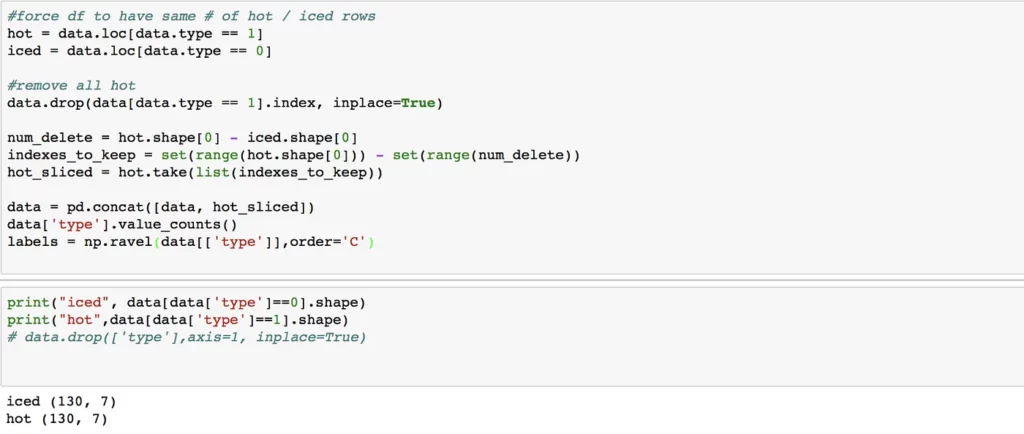
This helped with bias in the model and made sure both types were recorded equally in the dataset.
Finally, since the weatherCond column is a set of strings for the current weather conditions (‘Clear’, ‘Rain, ‘Snow’, etc), I decided to one-hot encode the column, for better accuracy.

The following represents the final columns I used for training:
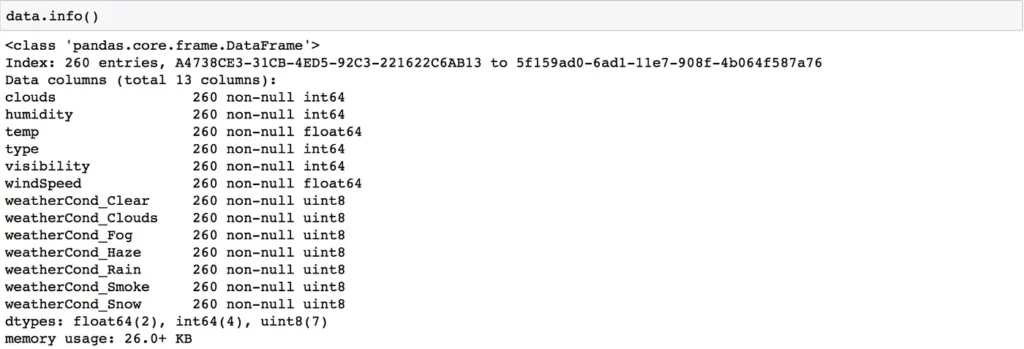
The training process is on a Jupyter notebook and can be found here.
I first split the data into x and y values. X contains all the features, and y is the prediction: 1 for hot coffee, 0 for iced coffee.
Next, I decided to try out some models and see what performs best! I’m using Sci-kit Learn to perform training for now.
First, I had to split the data into training and test sets using train_test_split:
The first model I tried was a Logistic Regression:
Only 68%, eh? Not great. Let’s see what else I can do. How about a Linear Regression?
Ok, that had no effect. How about a Random Forest?
That’s better!
Next, I tried SVC.
69%. Ok. Not terrible, but also not too good.
Since Random Forest had the best accuracy, I used this model for the app.
In order to use this model for the iOS app, I had to first save the model by pickling:
By pickling, we save the model to our machine for later use.
Note I have need to use protocol=2 because of different Python versions. The training was done in Python 3, but the Core ML conversion is only supported in Python 2.7, so I needed to backport the pickle file to be read by Python 2.7.
Core ML
Next, I had to convert the pickled file into a Core ML model to be used in the iOS app.
All I did here was load the pickled model, imported Core ML packages, and ran it:
I then modified the model and added a description to the input and output:
Finally, I exported the model to a file:
OK, almost done! Next, I imported this model into the iOS app and started predicting.
Once the model was imported, I could then use it:
func toOneHot(_ string:String) -> [Double] {
var str = string
var items = [Double](repeating: 0.0, count: 7)
let weather_conds:[String] = ["Clear", "Clouds", "Fog", "Haze", "Rain", "Smoke", "Snow"]
if str.lowercased().range(of:"cloud") != nil || str.lowercased().range(of:"overcast") != nil{
str = "Clouds"
}
if str.lowercased().range(of:"snow") != nil {
str = "Snow"
}
if str.lowercased().range(of:"rain") != nil || str.lowercased().range(of:"drizzle") != nil || str.lowercased().range(of:"mist") != nil{
str = "Rain"
}
if str.lowercased().range(of:"none") != nil {
str = "Clear"
}
guard let index = weather_conds.index(of: str) else {
items[0] = 1
return items
}
items[index] = 1
return items
}To summarize this code block, I acquired the user’s current location, fetched the current weather conditions, formatted the .json file back to what the model accepts — which is a 12d matrix of numbers — and performed the prediction.
When I trained the model, I had to one-hot encode the weatherCond column, and I had to do the same thing in the iOS app. Here, I created an empty array filled with 0’s, then updated the index to 1, which corresponds to the weather string.
In order to get the data into a matrix, I looped through each feature (cloud cover, humidity, temperature, wind speed and current weather condition) and used MLMultiArray.
Then I fed this matrix into the model to perform the prediction.
let input = coffee_predictionInput(input: mlMultiArray)
guard let prediction = try? model.prediction(input: input) else {
return
}
let result = prediction
print("classLabel (result.classLabel)")
if result.classLabel == 1 {
self.class_image.image = UIImage.init(named: "coffee_hot")
self.predict_label.text = "Hot Coffee"
} else {
self.class_image.image = UIImage.init(named: "coffee_iced")
self.predict_label.text = "Iced Coffee"
}
let percent = Int(round(result.classProbability[result.classLabel]! * 100))
self.predict_label.text = self.predict_label.text! + "n((percent)% probability)"Here, I passed the 12d matrix to the prediction model, which returned both the class name (1 or “Hot Coffee”, 2 for “Iced Coffee”), and the probability of the output.

So now, in the iOS app, it shows what coffee I should drink!
The application is now available for free on the App Store.
In the next post, I’ll go into more detail on how I cleaned the data and performed some feature analysis of the coffee data. I’ll also review how I employed the Alexa skill to help record the data.
Thanks for reading! Please like, share, and clap if you found this interesting.
Comments 0 Responses