
Quantization can make your deep learning models smaller, faster, and more energy-efficient (I’ve written about this previously).

But the process may cause high accuracy loss or may not improve prediction speed if done incorrectly. So here, I’m sharing some practical tips to minimize accuracy loss while maintaining good inference speed. These points are valid for both post-training quantization and quantization-aware training.
Table of contents
1. Do not quantize full model
This is generally the most common reason for low accuracy in quantized networks. In almost all of the tutorials and guides available on internet, they will generally guide you to quantize a full model. It’s an easy way but can lead to bad results.
A better approach is to quantize only specific layers. Look at this image showing the sizes of different layers of an encoder-decoder based network:
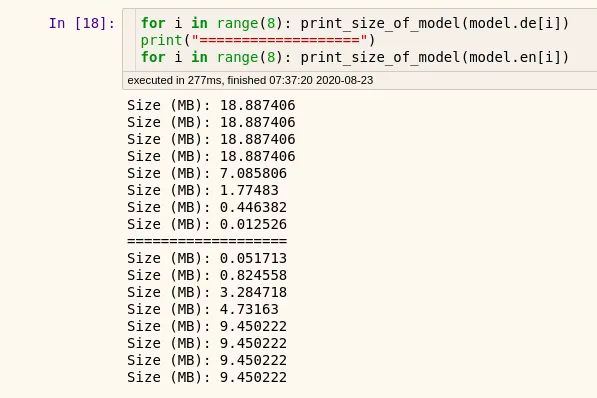
If you quantize full model here, you will end up with an inaccurate model. Why? As you can see in the above image, some layers are very small (<2MB).
Information in these layers is already very dense and thus, very low redundancy. If you compress these layers, you will lose information learned by the network and thus, the accuracy will drop.
Generally, you should leave the following types of layers in full-precision:
- Very small layers.
- Layers at the beginning and end of the network.
- Layers connected with multiple blocks. (Eg. skip connections).
2. Scale factor scope (per-channel over per-tensor)
The scale factor is used to map fp32 to int8. Per-tensor means we’re using one scale factor for one layer (all the channels). Per-channel quantization means we have different scale factors for each channel.
This allows for lesser error in converting fp32 tensors to quantized values. This is more beneficial when weight distribution varies greatly between channels.
3. Use symmetric quantization over asymmetric
Symmetric quantization (scale quantization) is much faster than asymmetric quantization (scale+shift quantization). In the image below (you don’t need to understand the equations), just see that scale+shift requires more operations:

Scale+shift quantization is able to slightly more accurately represent fp32 tensors in int8 format. But still, the accuracy gained is negligible.


4. Specify Backend
Multiplication and addition operations are implemented differently on ARM and x86 hardware. So, specifying hardware during the quantization process will help in optimizing inference speeds.
ARM is used in generally small energy-efficient devices like phones (Android, iOS) and Raspberry Pi, while x86 is used on computers and servers.
Thanks for reading, and I hope these tips will help you in building efficient quantized models. If you still get any problems in quantization, feel free to mail me at [email protected].
I’ve included some helpful references below.
References:
- PyTorch Docs: https://pytorch.org/docs/stable/quantization.html
- TensorFlow Docs: https://www.tensorflow.org/lite/performance/quantization_spec
- Quantization Blog: https://heartbeat.fritz.ai/quantization-arithmetic-421e66afd842
- Nvidia GTC: https://developer.download.nvidia.com/video/gputechconf/gtc/2019/presentation/s9659-inference-at-reduced-precision-on-gpus.pdf
Comments 0 Responses