
What is a Logarithmic Function ?
A function that increases or decreases rapidly at first, but then steadily slows as time moves, can be called a logarithmic function.
For example, we can say that the number of cases of the ongoing COVID-19 pandemic follows a logarithmic pattern, as the number of cases increased very fast in the beginning and are now slowing a bit.
The logarithmic function is defined as…
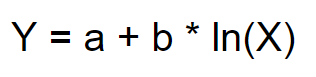
Where:
Y = Output feature
X = Input feature
a = The line/curve always passes through (1,a)
b = Controls the rate of growth/decay
Features of the Logarithmic Function:
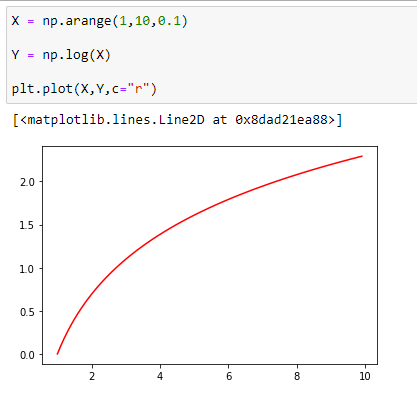
(1) Increases to the right without bound
Example:
(2) It always passes through (1,a)
Example:
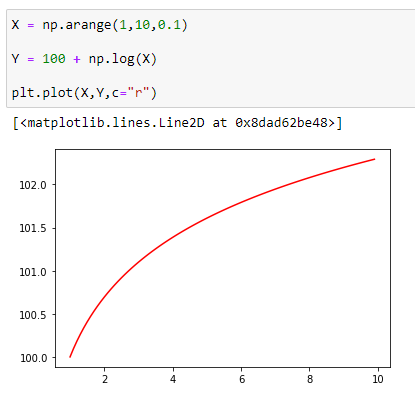
Here you can see that our graph passes through the point (1,a)—that is, (1,100).
(3) Very rapid growth, followed by slower growth
Example:
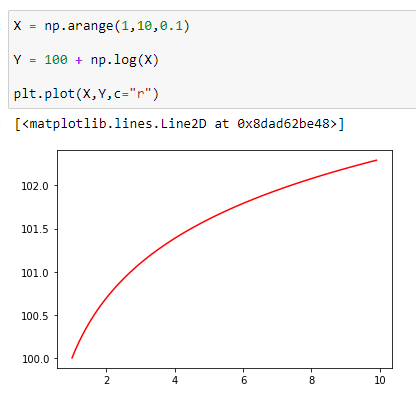
In the above image, you can see that in the beginning, the rate of increase was much higher than the rate of increase at the end.
Let’s see how we can calculate the rate of change :
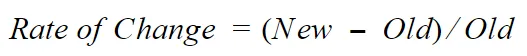
And here’s an example to understand it better (with discussion to follow).
Function used: Y = a + b * ln(X) = 100 + 1*ln(X)
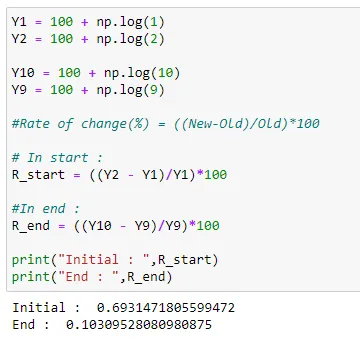
Short Description
In the above example, Y1 and Y2 represent initial points and Y9 and Y10 represent end points. What we did here is find the % change for each of the terminals (in our case) and compared them. From the output, we can be sure that the rate of change at the start of the curve is higher than the rate of change at the end of our curve.
So I think from the above example we can see that for a logarithmic function, the rate of growth at the beginning (0.6931) is greater than the rate of increase in the end.(0.1030)
(4) Common log(base 10) will grow slower than natural log(base e)
Example:
(a) Natural Log (base e)

Here you can see that peak value at X = 10 is > 2.0
(b) Common Log (base 10)
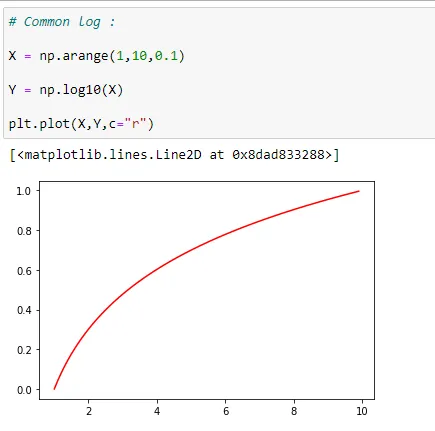
And here you can see that peak value at X =10 is ~1.0.
So it’s clear that the common log grows faster than the natural log.
(5) b controls the rate of growth
Let’s start with a simple function:
y = a+b*ln(x)
(a) a =0
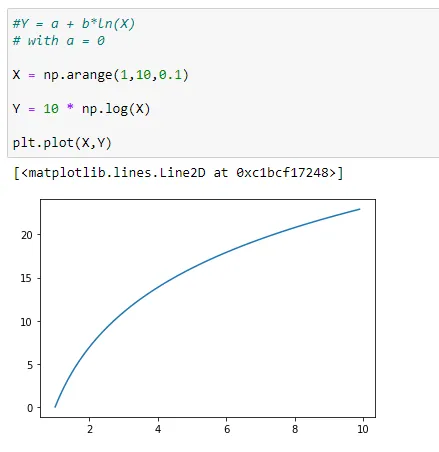
Here, (1,a) will be (1,0) since the value of a=0.
(2) b = 0
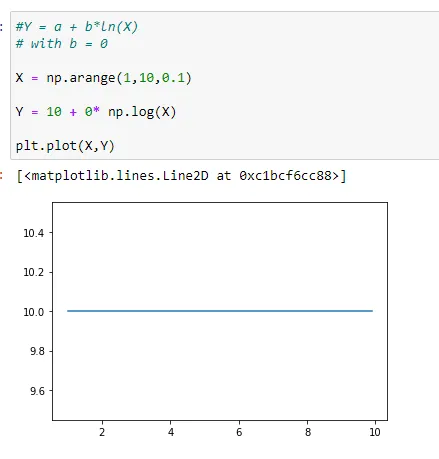
Here, (1,a) will be (1,10) since the value of a=10.
(3) a = b = 0
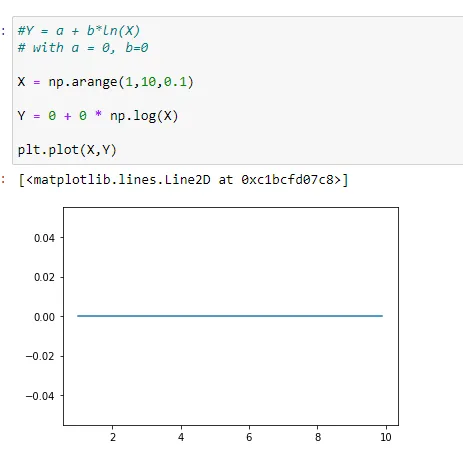
Here, (1,a) will be (1,0) since the value of a=0.
(4) b = 0.1

Here, notice that the value of Y is increasing slowly with respect to X.
At X =10 the value of y ~=10.20 and (1,a) will be (1,10) since the value of a=10.
(5 ) b = 10
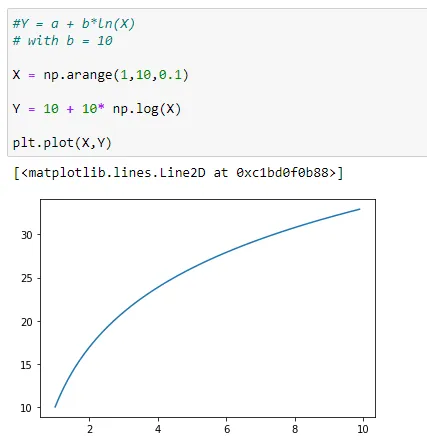
Here, notice that value of Y is increasing very fast with respect to X.
Additionally, notice that as we increased the value of b, when X = 10, the value of y~=30. And (1,a) will be (1,10) since the value of a=10
(6) b =-0.1
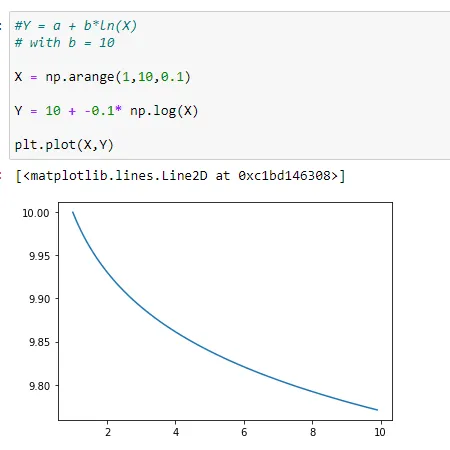
Here we see a slower rate of decay in the graph.
(7) b = -10
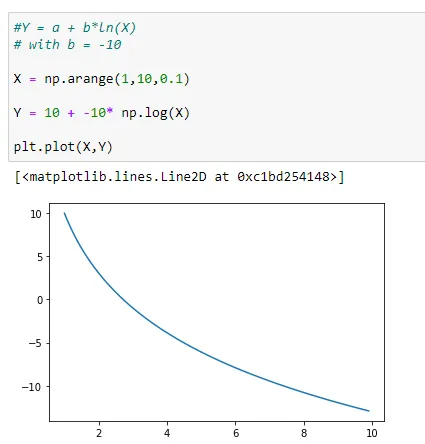
Conversely, here we see a faster rate of decay in the above graph.
From all of these graphs, we can say that the logarithmic model has a period of rapid increase (at the beginning), followed by a period where the growth slows (towards the end).The main difference between this model and the exponential growth model is that the exponential growth model begins slowly and then increases very rapidly as time increases.
Differences between exponential and logarithmic models
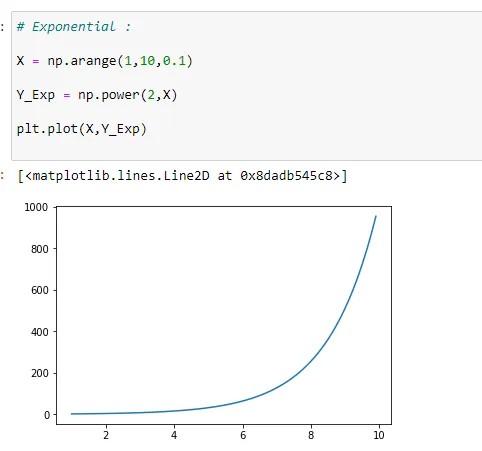
(1) Exponential Model:
Almost flat, then increases rapidly.
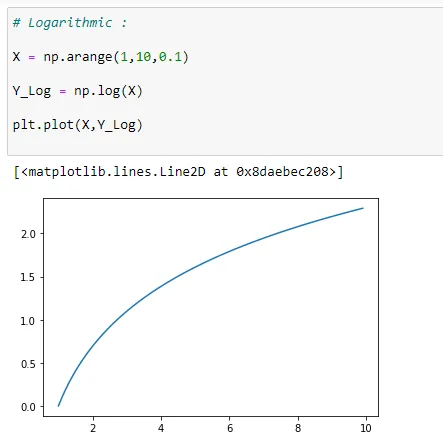
(2) Logarithmic Model:
Growing rapidly to start, then eventually flattens.
Applications of the logarithmic model
(1) The magnitude of earthquakes
(2) The intensity of sound
(3) The acidity of solution
(4) pH level of solutions
(5) Yields of chemical reactions
(6) Production of goods
(7) Growth of infants
(8) COVID-19 Graph
As with exponential models, data modeled by logarithmic functions are either always increasing or always decreasing as time moves forward.
Example:
(1) Always Increasing : (+ve value of b)

(2) Always Decreasing: (-ve value of b):
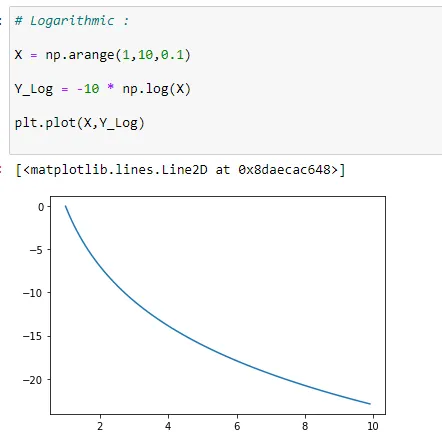
Recall that logarithmic functions increase or decrease rapidly at first, but then steadily slow as time moves on. By reflecting on the characteristics we’ve already learned about this function, we can better analyze real-world situations that reflect this type of growth or decay.
When performing logarithmic regression analysis, we use the form of the logarithmic function most commonly used on graphing utilities:
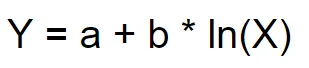
In summary,
(1) X must be greater than zero.
(2) The point (1, a) is on the graph of the model.
(3) If b > 0, the model is increasing. Growth increases rapidly at first and then steadily slows over time.
(4) If b < 0, the model is decreasing. Decay occurs rapidly at first and then steadily slows over time.
Now that we have some of the fundamentals of logarithmic regression down, here we’re going to see why we should actually use it. To explain this in more depth, we’ll look at the example of growth in tree height with increasing ages, finding the regression line/curve using both simple linear regression and logarithmic regression.
After that, we’ll calculate the error for both the plotted curves and compare which model did a better job for the task at hand.
The normal equation is as follows:
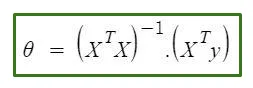
Where
X = Input feature matrix
Y = Output Vector
Ө = The optimal parameter array
I have written a comprehensive article on this topic, if you’re interested in studying that in depth:
To watch helpful video explanations on machine learning algorithms check out this YouTube channel:
If you are reading this then please clap for the article!!

Real World Example:
Here I’m going to show you an example using 2 different methods:
- Using a normal equation with linear line fitting
- Using a normal equation with logarithmic curve fitting (long way!)
- Using the SciPy library (short way!)
Please keep in mind that understanding the logic behind each operation is crucial in machine learning. So I think you should go through both the solutions to understand it better.
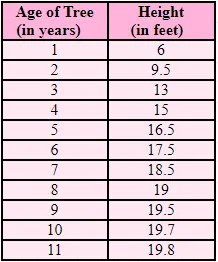
Let’s use a real example (tree age and height) and find the best fit curve:
(A) Logarithmic data with simple linear regression line
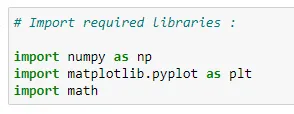
(1) Import the required libraries:
We use the numpy library for array manipulations in Python. For plotting the data we can use matplotlib library. Here we’re importing the math library, because at the end we’re going to use the value of “e” (2.71828). If you don’t want to use math library, then you can simply use the value of “e” in a numeric fashion.
(2) Our dataset :
Here X stores the value of “Age” for a tree and Y stores the value of “Height” for that tree.
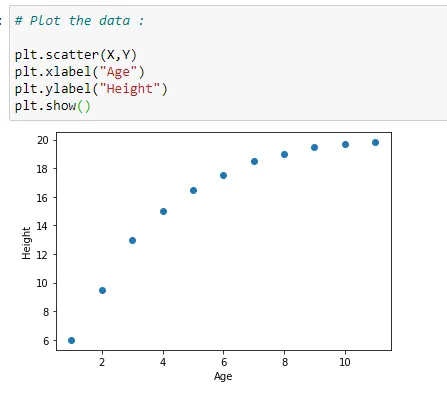
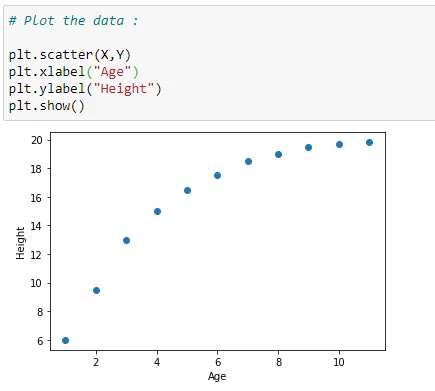
(3) Plot the data :
Here we are plotting our data on coordinate plane with matplotlib library.
(4) Value of 1st column in our main matrix X :
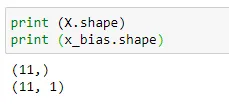
(5) Shape of our data :
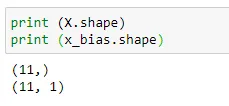
As we going to append one vector with another, the size of each vector must be equal. So here we are going to see what’s the size of each vectors.
(6) We need to reshape the data since we want to append our x-features with x_bias:
Since the sizes of vectors are different, we are going to reshape our vector X.
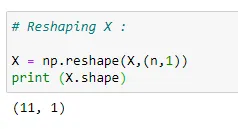
(6) Main matrix X:
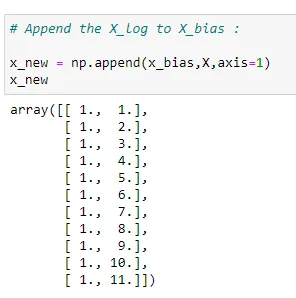
(7) Transposing a matrix:
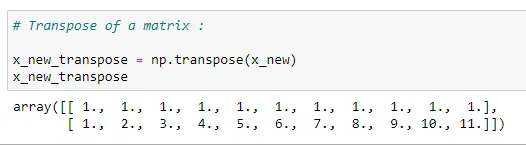
(8) Matrix multiplication:

(9) Inverse of a matrix:

(10) Matrix multiplication:
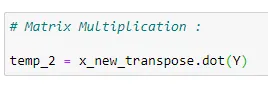
(11) Find coefficients:
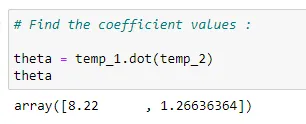
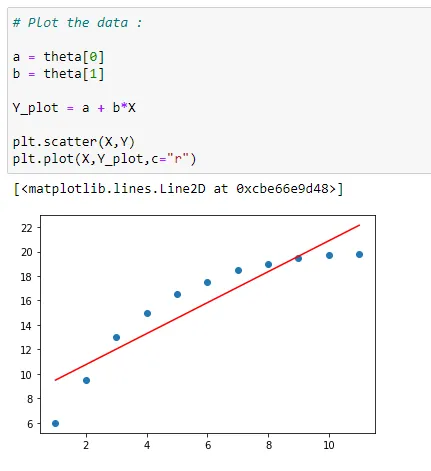
(12) Plot the data with regression line:
Here we can see that first we have plotted the main data points in blue dots, then the red line is the best fit for our data set. The values used to plot the red line are our values stored in the theta variable.
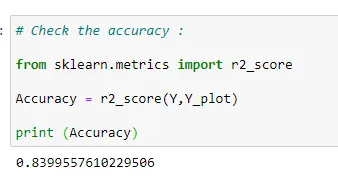
(13) Check the accuracy of model :
Putting it all together :
# Import required libraries :
import numpy as np
import matplotlib.pyplot as plt
import math
#X = Age
#Y = Height
X = np.array([1,2,3,4,5,6,7,8,9,10,11])
Y = np.array([6,9.5,13,15,16.5,17.5,18.5,19,19.5,19.7,19.8])
# Plot the data :
plt.scatter(X,Y)
plt.xlabel("Age")
plt.ylabel("Height")
plt.show()
# 1st column of our X matrix should be 1 :
n = len(X)
x_bias = np.ones((n,1))
print (X.shape)
print (x_bias.shape)
# Reshaping X :
X = np.reshape(X,(n,1))
print (X.shape)
# Append the X_log to X_bias :
x_new = np.append(x_bias,X,axis=1)
x_new
# Transpose of a matrix :
x_new_transpose = np.transpose(x_new)
x_new_transpose
# Matrix multiplication :
x_new_transpose_dot_x_new = x_new_transpose.dot(x_new)
# Find inverse :
temp_1 = np.linalg.inv(x_new_transpose_dot_x_new)
# Matrix Multiplication :
temp_2 = x_new_transpose.dot(Y)
# Find the coefficient values :
theta = temp_1.dot(temp_2)
theta
# Plot the data :
a = theta[0]
b = theta[1]
Y_plot = a + b*X
plt.scatter(X,Y)
plt.plot(X,Y_plot,c="r")
# Check the accuracy :
from sklearn.metrics import r2_score
Accuracy = r2_score(Y,Y_plot)
print (Accuracy)(B) Using the normal equation for logarithmic curve fitting :
(1) Import required libraries :
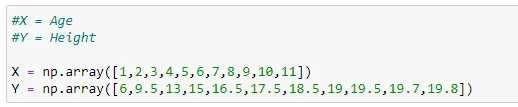
(2) Data set :
(3) Plot the data :
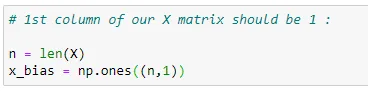
(4) Initialize matrix X :
(5) Shape of data :
(6) Reshaping X :
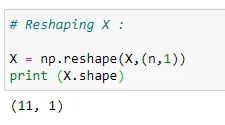
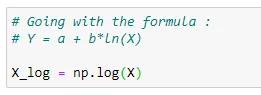
(7) Applying the formula :
Here we are going with the formula of normal equation. Notice that, here we are going to use log(X).
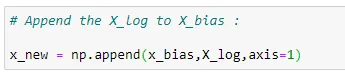
(8) Matrix x :
Here we are going with the formula of normal equation.
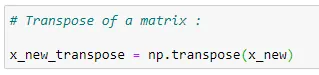
(9) Transposing the matrix:
(10) Matrix multiplication:

(11) Inverse of the matrix:

(12) Matrix multiplication:
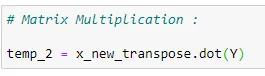
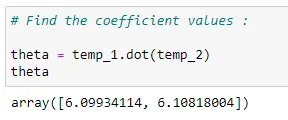
(13) Coefficient values :
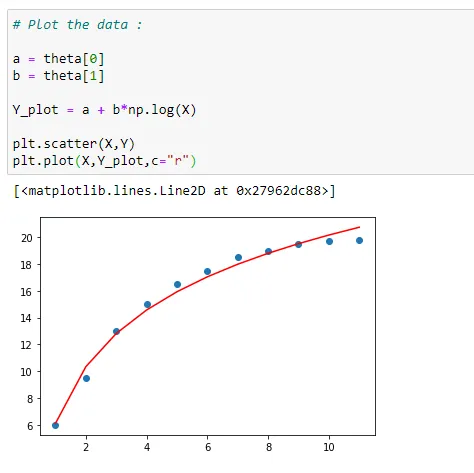
(14) Plot the data :
Here we can see that first we have plotted the main data points in blue dots, then the red curve is the best fit for our data set. The values used to plot the red curve are our values stored in the theta variable.
(15) Check accuracy :
Here we can see that how accurate our model is by checking the r2_score.

Given this, we can say that when we have kind of logarithmic data, it’s wise to use logarithmic function to plot the curve instead of simple line.
Putting it all together:
# Import required libraries :
import numpy as np
import matplotlib.pyplot as plt
import math
#X = Age
#Y = Height
X = np.array([1,2,3,4,5,6,7,8,9,10,11])
Y = np.array([6,9.5,13,15,16.5,17.5,18.5,19,19.5,19.7,19.8])
# Plot the data :
plt.scatter(X,Y)
plt.xlabel("Age")
plt.ylabel("Height")
plt.show()
# 1st column of our X matrix should be 1 :
n = len(X)
x_bias = np.ones((n,1))
print (X.shape)
print (x_bias.shape)
# Reshaping X :
X = np.reshape(X,(n,1))
print (X.shape)
# Going with the formula :
# Y = a + b*ln(X)
X_log = np.log(X)
# Append the X_log to X_bias :
x_new = np.append(x_bias,X_log,axis=1)
# Transpose of a matrix :
x_new_transpose = np.transpose(x_new)
# Matrix multiplication :
x_new_transpose_dot_x_new = x_new_transpose.dot(x_new)
# Find inverse :
temp_1 = np.linalg.inv(x_new_transpose_dot_x_new)
# Matrix Multiplication :
temp_2 = x_new_transpose.dot(Y)
# Find the coefficient values :
theta = temp_1.dot(temp_2)
# Plot the data :
a = theta[0]
b = theta[1]
Y_plot = a + b*np.log(X)
plt.scatter(X,Y)
plt.plot(X,Y_plot,c="r")
# Check the accuracy :
from sklearn.metrics import r2_score
Accuracy = r2_score(Y,Y_plot)
print (Accuracy)
(C) Using SciPy (Python library)
(1) Import libraries:
(2) Dataset:

(3) Prediction function:
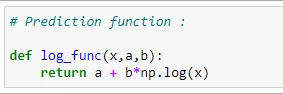
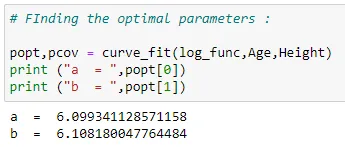
(4) Optimal parameters:
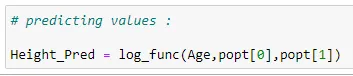
(5) Predicting values:
(6) Plot the data:

(7) Accuracy:
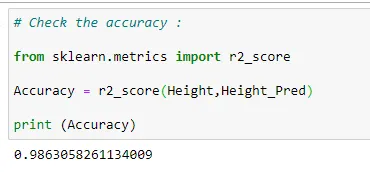
Putting it all together:
#Import Required Libraries :
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
#Dataset :
Age = np.array([1,2,3,4,5,6,7,8,9,10,11])
Height = np.array([6,9.5,13,15,16.5,17.5,18.5,19,19.5,19.7,19.8])
#Prediction function :
def log_func(x,a,b):
return a + b*np.log(x)
#Finding the optimal parameters :
popt,pcov = curve_fit(log_func,Age,Height)
print ("a = ",popt[0])
print ("b = ",popt[1])
#Predicting values :
Height_Pred = log_func(Age,popt[0],popt[1])
# Plot the data :
plt.plot(Age, Height, 'r-')
plt.scatter(Age,Height_Pred,label='Age vs Height')
plt.title("Age vs Height a+b*ln(X)")
plt.xlabel('Age')
plt.ylabel('Height')
plt.legend()
plt.show()
# Check the accuracy :
from sklearn.metrics import r2_score
Accuracy = r2_score(Height,Height_Pred)
print (Accuracy)Notice that with both methods we get the same accuracy. But the only difference is that the code for 2nd method is shorter, and we always like to run our program with fewer lines of code, right? But keep in mind that it’s also always important to know how the operations actually work.
That’s pretty much it for this article. I hope you guys learned something new from this article. If you guys enjoyed this article, then please hit the clap icon—it will motivate me to write more comprehensive articles!
Thank you for reading this article. I hope it helped!
I regularly post my articles on : patrickstar0110.blogspot.com
All my articles are available on: medium.com/@shuklapratik22
If you have doubts about anything in this article, feel free to contact me : [email protected]

Comments 0 Responses