
Sensor fusion is one of the key aspects of self-driving cars.
If we take a look at the 4 main elements of self-driving vehicles, we can categorize sensor fusion a part of both the perception and the localization world. The reason is simple: both these disciplines use multiple sensors to function.
For example, perception is using cameras, LiDARs, and RADARs to detect obstacles’ classes, positions, and velocities with high accuracy. Localization, on the other hand, fuses GPS, LiDAR, and camera data to get an accurate position with centimeter-level accuracy.
Today, I’d like to focus on the perception process—and especially the fusion between a LiDAR and a camera.
LiDAR & Camera Fusion
Camera — A 2D Sensor
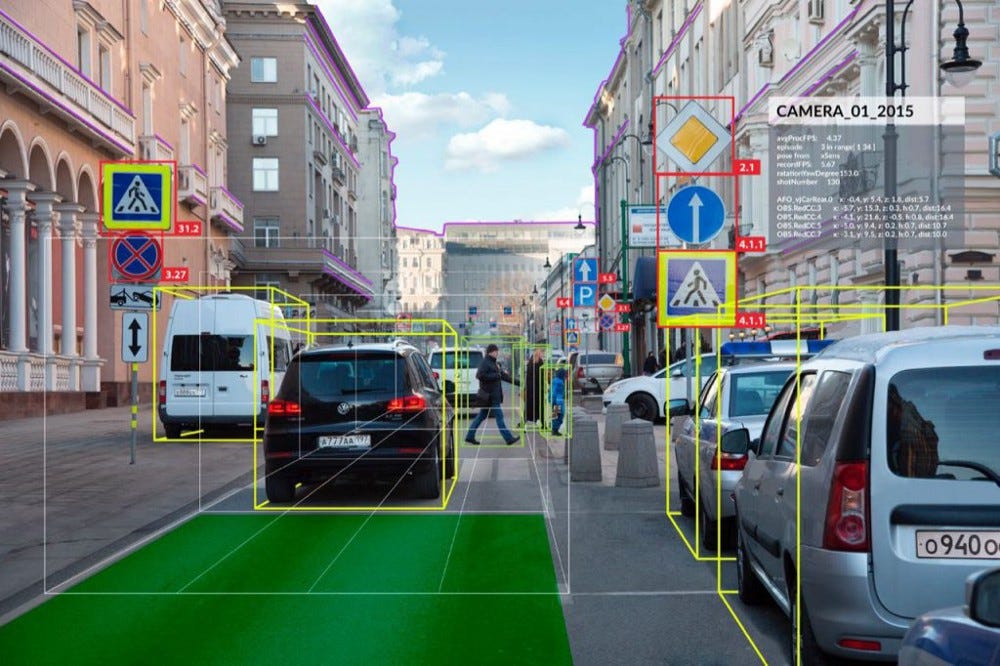
The camera is a well-known sensor that’s used to output bounding boxes, lane line positions, traffic light and signs status, and many other things. The key thing to remember about a camera is that it’s a 2D Sensor.
Though there are limitations, it’s possible to use camera images and run machine learning and deep learning algorithms to get the results we’re looking for. For more information about this process, refer to my article ‘Computer vision applications in self-driving cars’.
LiDAR — A 3D Sensor
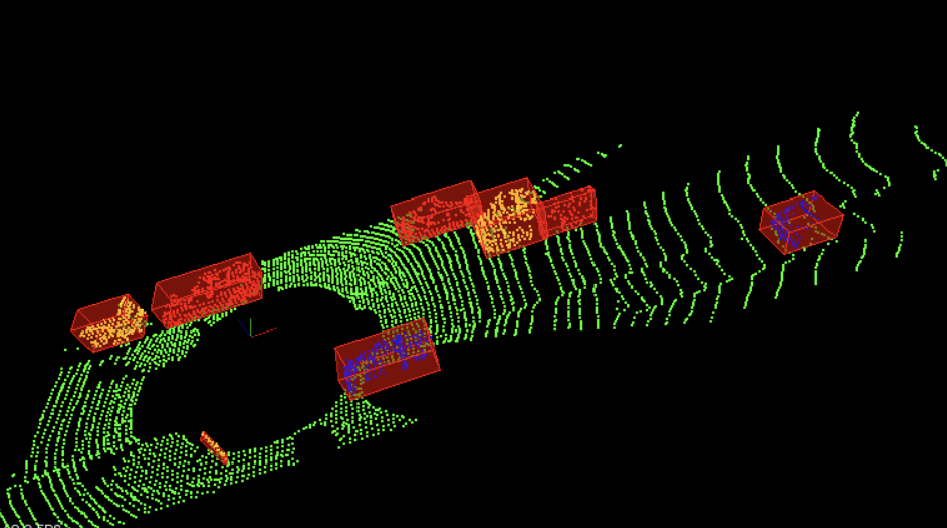
LiDAR stands for Light Detection And Ranging. It’s a 3D Sensor that outputs a set of point clouds; each one having an (X,Y,Z) coordinate. It’s also possible to perform many applications on 3D data—running machine learning models and neural networks included. Here’s an output example.
How to fuse 3D and 2D Data?
So how can we fuse data that are not in the same dimensional space?
In Sensor Fusion, we have two possible processes:
- Early fusion — Fusing the raw data
- Late fusion — Fusing the results
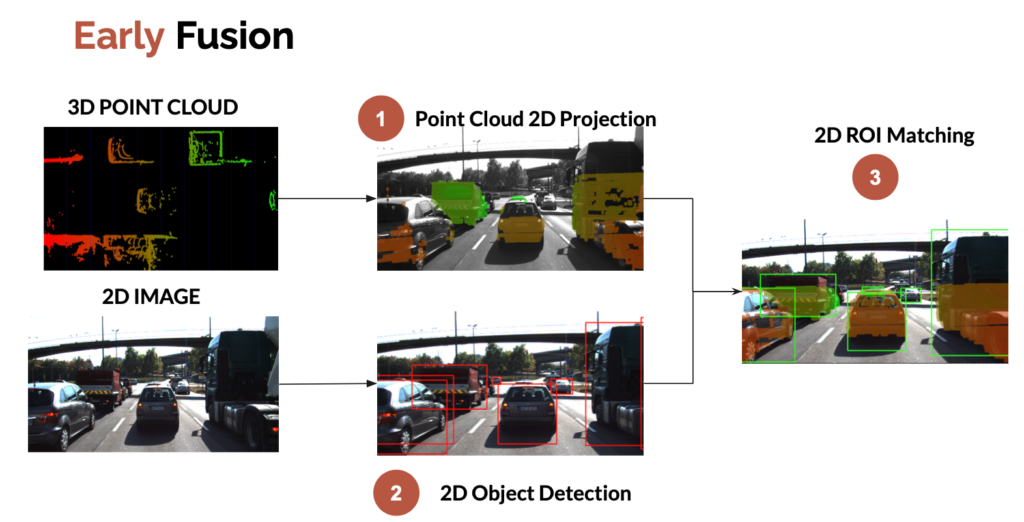
Early fusion is about fusing raw data. We can, for example, project the LiDAR point clouds (3D) onto the 2D image. We then check whether or not the point clouds belong to the 2D bounding boxes.
Here’s what early fusion looks like:
Late fusion, on the other hand, is about fusing the results after independent detections. We can, for example, project the 2D bounding boxes from the camera into 3D bounding boxes, and then fuse these bounding boxes with the ones obtained from the LiDAR detection process.
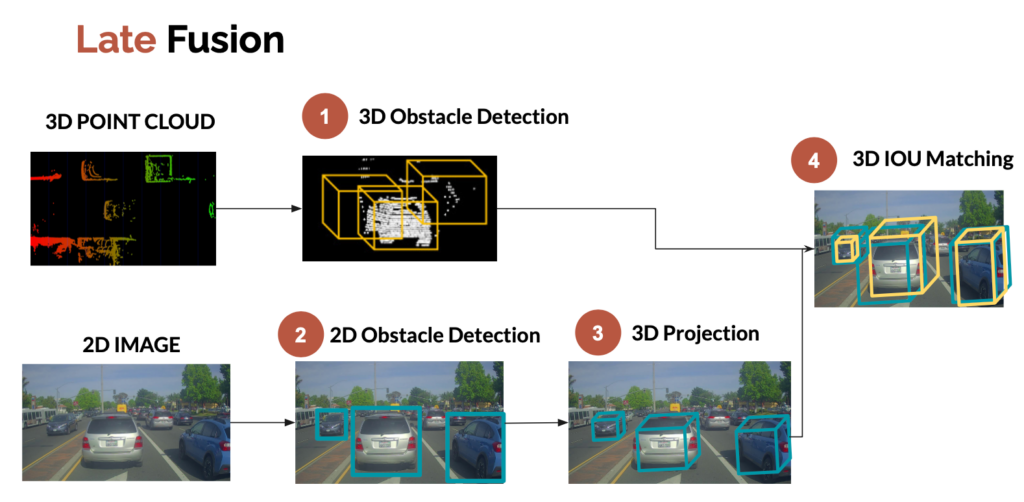
We now know two ways to fuse data between a LiDAR sensor and a camera. But there’s still one thing we need to cover: obstacle association and tracking.
Obstacle Tracking
In my ‘Computer Vision for Tracking’ article, I detailed a technique using The Hungarian algorithm and Kalman filters to associate objects between frames. Here’s what it looks like.

Here, we’re tracking the bounding box position and using IOU as a metric. We can also use deep convolutional features to make sure the object in the bounding box is the same — we call this process SORT, or Deep SORT if using convolutional features.
Although this process would work very well in our case, I’d like to discuss another possible approach: feature tracking.
Feature Tracking
In feature tracking, we track the features directly instead of tracking the bounding boxes. Similarly to early and late fusion, we’ll have early and late tracking.
- Early tracking is about tracking features in the image.
- Late tracking is about tracking the detected bounding boxes.
Here’s what it looks like:
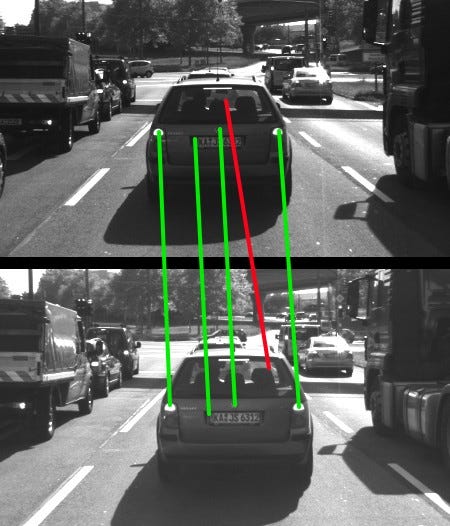
How feature tracking works
The idea here is to locate and track keypoints across images. Keypoints can be corners, edges, gradients, or specific changes in pixels.
In the following images, we can clearly see a line, a corner, and an ellipse. It’s all made by measuring contrast between neighboring dark and bright pixels.

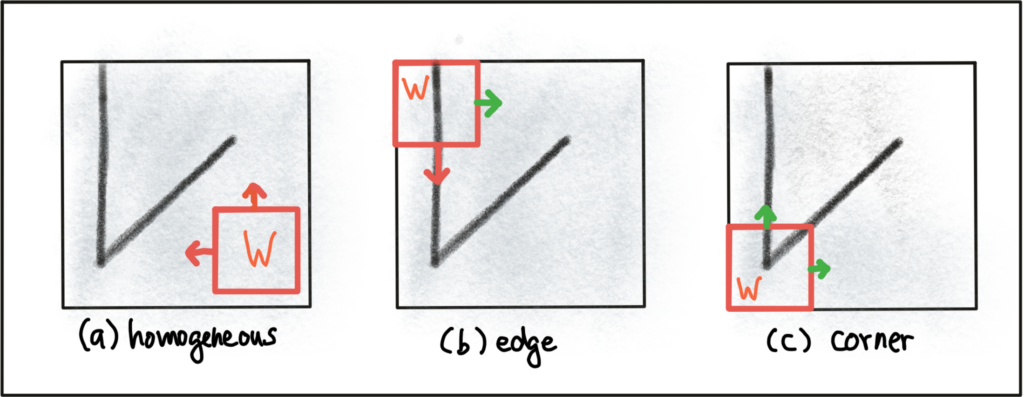
In order to detect and track keypoints, we use a 3 steps process:
- Detectors
- Descriptors
- Matching
Detectors
The idea of a detector is to detect specific pixels in images, such as corners or edges. Several algorithms exist, to name a few:
- Harris Corner Detector — From 1988
- Scale Invariant Feature Transform (SIFT) — From 1996
- Speeded Up Robust Features (SURF) — From 2006
- Features from Accelerated Segment Test (FAST) — From 2006
All these are built with the same goal in mind: Find keypoints rapidly. Some techniques will be robust to changes in light, others will be faster, and techniques like Harris will be focused on corner detection.
The output looks like this —

Descriptors
Now that we’ve used detectors to find keypoints (corners and edges), we can use descriptors to match them alongside images.
To do so, we look at patches that are around a given keypoint. We can go from comparing raw pixel values to using a Histogram of Oriented Gradients (HOG).
The most popular method for description (and detection) is SIFT, already introduced earlier.
Here’s an overview of how it works.
- Detect a keypoint
- For every keypoint, select a surrounding patch.

3. Compute the orientation and magnitude and get a HOG.
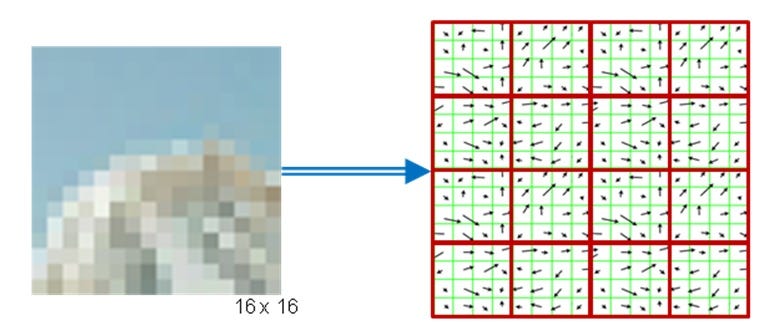
4. This gives a histogram that we can compare between frames.
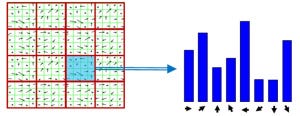
Results
Here’s the detector/descriptor result — we have keypoints and orientations.

Matchers
So the descriptor idea is to have something a bit better than a single pixel value to compare between frames.
What metric do we use to match the descriptors?
We have two histograms, or vectors representing our features.
The idea now is to use a loss function to determine if these vectors are similar or different. We can use the Sum of the Squared Differences (SSD) to get a number and threshold it. Some errors are better for a set of detectors and descriptors.
We can also use a nearest neighbor matcher, or even brute force matching.
One of the most popular and efficient technique is called FLANN.
What to pay attention to
Here’s an example of something we want to pay attention to:
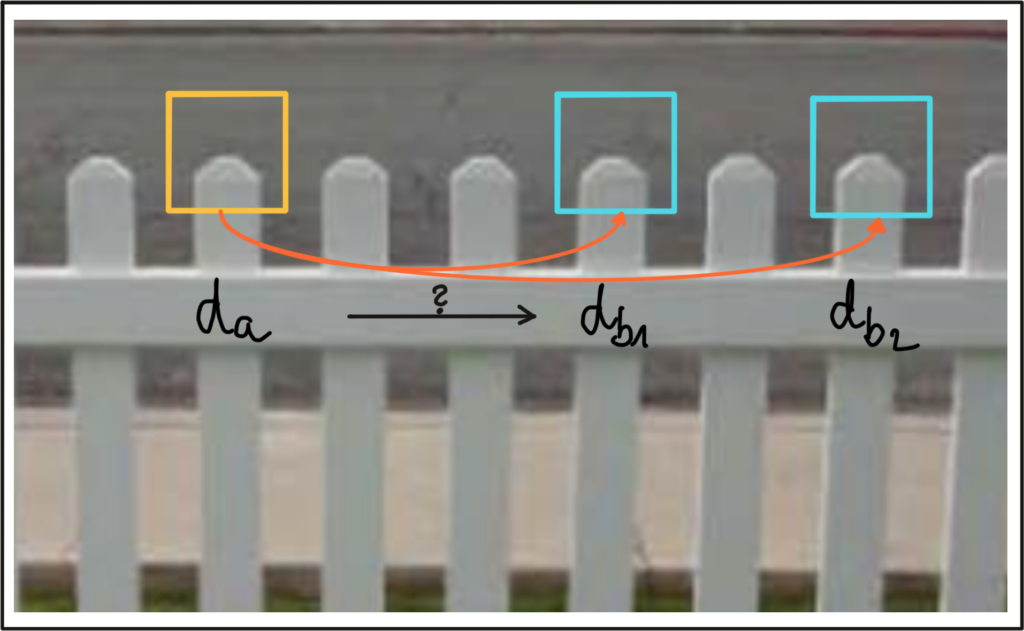
These descriptors are very close in terms of features, and a descriptor from frame t-1 can lead to an incorrect match. Filtering techniques such as SSD ratio exist to help us with this problem.
Conclusion
You now have a full overview of the sensor fusion process between a LiDAR and a camera.
Let’s summarize what we’ve learned:
- The sensor fusion process is about fusing the data from different sensors, here a LiDAR and a camera.
- Tracking is also a big part of the sensor fusion process — There can be late tracking, where we track the bounding boxes, or early tracking, where we track the pixels.

Go Further
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Comet Newsletter), join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.
Comments 0 Responses