
Introduction — What’s YOLO?
YOLO stands for You Only Look Once. It’s an object detection model used in deep learning use cases, of which there are mainly 2 main families:
- Two-Stage Detectors
- One-Stage Detectors
The idea of one-stage detection (also referred to as one-shot detection) is that you only look at the image once.
- In a sliding window + classification approach, you look at the image and classify it for every window.
- In a region proposal network, you look at the image in two steps—the first to identify regions where there might be objects, and the next to specify it.
YOLOv3 was introduced as an “Incremental Improvement”
Stating that it was simply a bit better than YOLOv2, but not much changed.
YOLOv4 was then recently introduced as the “Optimal Speed and Accuracy of Object Detection”.
No one in the research community expected a YOLOv4 to be released…
Why? Joseph Redmon, the original author, recently announced that he would stop doing computer vision research because of the military and ethical issues…

Someone had to continue the work…Alexey Bochkovskiy!
You might know him as @AlexeyAB, given that he invented the Windows version of YOLO v2 and v3. He helped a lot of engineers (me included) in implementing YOLO in object detection projects.
Onto YOLOv4
Today, we’ll try to understand why YOLOv4 is a super-network that can, once again, change the world.
Before we start, I invite you to join the Think Autonomous Mailing List and learn every day about self-driving cars, Computer Vision, and Artificial Intelligence.
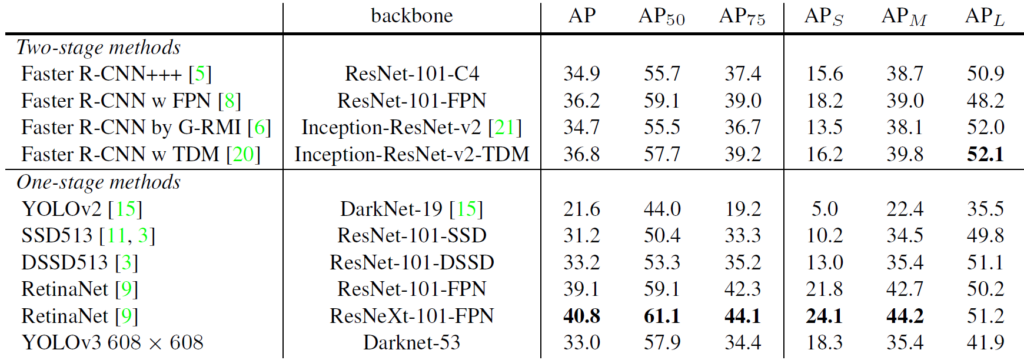
Let’s start with the results

Most people in the field today are used to YOLOv3, which already produces excellent results. YOLOv4 has improved again in terms of accuracy (average precision) and speed (FPS), the two metrics we generally use to qualify an object detection algorithm.

What changed in YOLOv4?
- Model training can be done on a single GPU.
- Specific techniques—Bag-of-Freebies and Bag-Of-Specials—improve the network.
Architecture
Here’s the architecture provided:
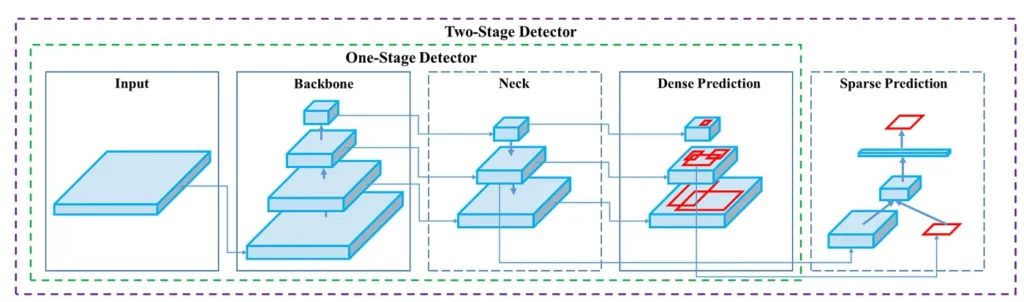
We have 4 apparent blocks, after the input image:
- Backbone
- Neck
- Dense Prediction—used in one-stage-detection algorithms such as YOLO, SSD, etc
- Sparse Prediction—used in two-stage-detection algorithms such as Faster-R-CNN, etc.
Backbone
Backbone here refers to the feature-extraction architecture. If you’re used to YOLO, you might know it by different names, such as Tiny YOLO or Darknet53. The difference between these is the backbone.
- Tiny YOLO has only 9 convolutional layers, so it’s less accurate but faster and better suited for mobile and embedded projects
- Darknet53 has 53 convolutional layers, so it’s more accurate but slower.
Exactly like there are multiple versions of ResNet, there are multiple versions of YOLO, depending on the backbone.
In YOLOv4, backbones can be VGG, ResNet, SpineNet, EfficientNet, ResNeXt, or Darknet53 (the backbone used in YOLOv3).
🛑 If you look at the paper, for YOLOv4, you’ll notice that the backbone used isn’t Darknet53 but CSPDarknet53. These letters are not here to look nice —they actually mean something.
CSP stands for Cross-Stage-Partial connections. The idea here is to separate the current layer into 2 parts, one that will go through a block of convolutions, and one that won’t. Then, we aggregate the results. Here’s an example with DenseNet:

So here’s YOLOv4’s backbone:

Neck
The purpose of the neck block is to add extra layers between the backbone and the head (dense prediction block). You might see that different feature maps from the different layers used.

In the early days of convolutional neural networks (CNNs), everything was very linear. In more recent versions, we have a lot of middle blocks, skip connections, and aggregations of data between layers. This is a family of techniques called “parameter aggregation methods”.
Here’s a popular technique called FPN (Feature Pyramid Network):

🛑 This is not used in YOLOv4. But I wanted to show it to you so you can connect to it in the next technique: a Path Aggregation Network (PANet).
- We’ll be using a modified version of the PANet (Path Aggregation Network). The idea is again to aggregate information to get higher accuracy.

- Another technique used is Spatial Attention Module (SAM). Attention mechanisms have been widely used in deep learning, and especially in recurrent neural networks. It refers to focusing on a specific part of the input. As I can’t cover attention in this post, here’s a link to a good overview.
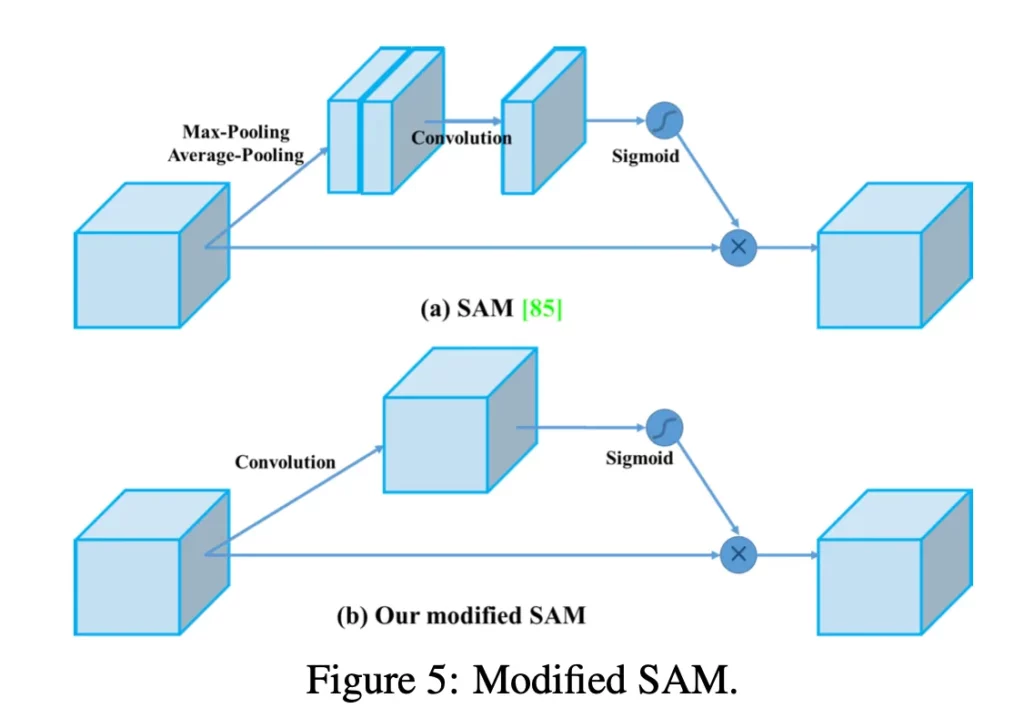
- Finally, Spatial Pyramid Pooling (SPP), used in R-CNN networks and numerous other algorithms, is also used here.

Head
The head block is the part used to:
- Locate bounding boxes
- Classify what’s inside each box
Here, we have the the same process as in YOLOv3. The network detects the bounding box coordinates (x,y,w,h) as well as the confidence score for a class. This technique is anchor-based. In case you need a refresher on how YOLO computes the prediction, I’ll point you to Andrew Ng’s explanation.
It’s not over yet
To be a state-of-the-art model, YOLOv4 needs to be at the leading-edge of deep learning. The authors have worked on techniques to improve the accuracy of the model while training and in post-processing.
These techniques are called bag-of-freebies and bag-of-specials. We’ll have a look at the techniques used here, but I can’t cover everything.
Bag-Of-Freebies 🧮
Bag-Of-Freebies (BoF) is a set of techniques that help during training without adding much inference time. Some popular techniques include data augmentation, random cropping, shadowing, dropout, etc.
Here’s the list of techniques used, according to the paper:
- BoF for the backbone: CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing.
- BoF for the detector: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, self-adversarial training, eliminate grid sensitivity, using multiple anchors for a single ground-truth sample, cosine annealing scheduler, optimizing hyperparameters, random training shapes.
So, it’s a bit more complicated than just data augmentation, but you get the idea. For example, DropBlock is similar to Dropout, but with blocks.
Bag-Of-Specials 🧮
Bag-of-Specials (BoS) is another family of techniques. Unlike BoF, they change the architecture of the network and thus might augment the inference cost a bit. We already saw SAM, PAN, and SPP, which all belong to this family.
Here’s the complete list, from the paper:
- BoS for backbone: Mish activation, cross-stage partial connections (CSP), multi-input weighted residual connections (MiWRC)
- BoS for detector: Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
It can be a bit complicated—we saw at least half of them working together. But the idea is to improve the performance using techniques that have proven to work.
Conclusion
You’ve made it this far—congrats! The path to understanding a research paper of this caliber is very long and hard. Studying techniques one after the other can help. But it’s nevertheless important—YOLOv4 is the new state of the art in object detection. Again, here’s the paper if you want to study it.
Go further
- Read more articles on self-driving cars and Computer Vision
Comments 0 Responses