
In this post, we’re going to investigate the field of image super-resolution and its applications in real world. We’ll discuss a brilliant state-of-the-art model involving generative adversarial networks (GANs) for this task and try to understand the underlying logic behind the approach.
So let’s jump right in!

Kindly refer to the link given below for the complete research paper. The model discussed in this post will be based on the approach used in this paper.
What Is Image Super-Resolution?
As the name suggests, super-resolution refers to the art (yes, data science is an art, people!😉) of converting an image into higher resolution using its lower resolution image. It has various real-world applications like:
- Storing images: For a data-intensive service, storing images in their high resolution format can be pretty expensive, since it takes up a lot of space. For example: Hospitals handle terabytes of data relevant to patients, injuries, MRIs etc.—thus, storing all of this data in high resolution is not economically feasible. With the help of image super-resolution techniques, one can convert the low resolution formats into higher resolution on a need-to-do basis, thus making storage more efficient.
- Reviving history: Ancient artifacts and historical images and documents can benefit from image super-resolution, as well. Such documents can be revived by converting them into their higher resolution counterpart, and thus preserved in a better quality.
Techniques Used for Image Super-Resolution
Single Image Super-Resolution (SISR)
is one the most frequently used techniques to increase the resolution of images. Various techniques have been developed to enhance the resolution of images, Some of them are briefly discussed below:
- Prediction-based methods: These were one of the initial model types for SISR. These algorithms work by interpolating pixel values in the image. Example of such filters are: linear, bicubic, or Lanczos. These filter-based approaches however, reduces contrast or sharp edges of an image and overly simplifies the output image. As a result, the image is too smooth and such results are undesirable in SISR. To learn more, refer to this article.
- Nearest neighbor methods: These techniques are widely used in computer vision. And in this case, the low resolution patches of similar types are upsampled, and thus the image is reconstructed based on the pixel values of the nearest pixels.
GAN-Based Approach
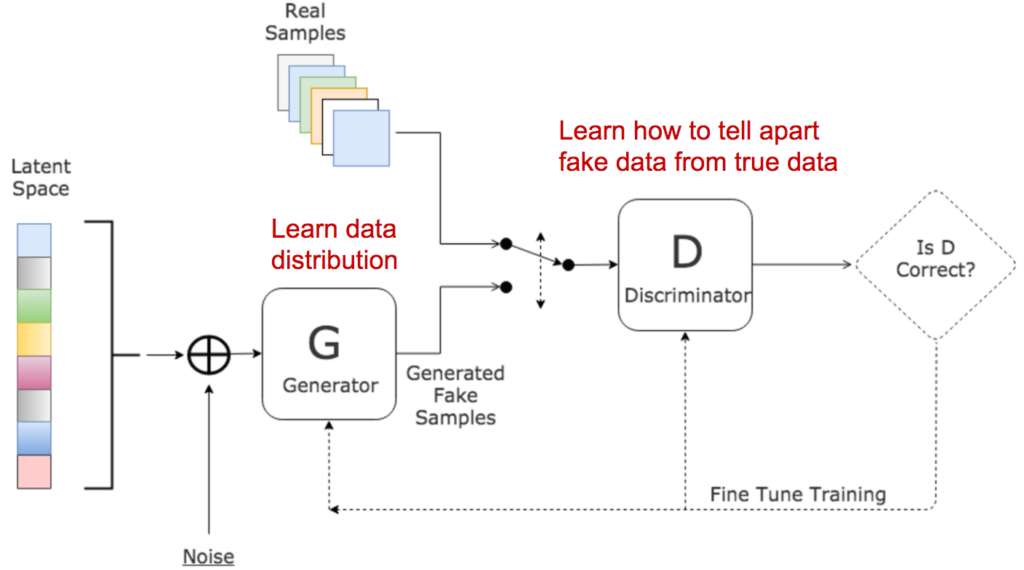
GANs have proven to be a substantial improvement for generative modeling problems like image inpainting and SISR. In generative adversarial networks, two networks train and compete against each other, resulting in mutual improvisation. The generator misleads the discriminator by creating compelling fake inputs and tries to fool the discriminator into thinking of these as real inputs . The discriminator tells us if an input is real or fake.
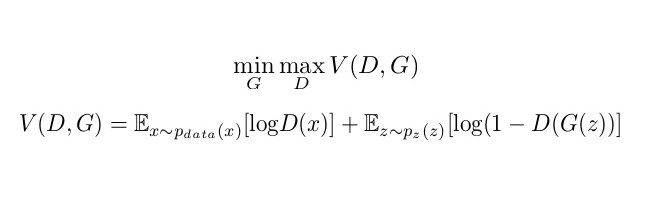
This optimization equation helps to increase the probability of the discriminator being able to differentiate between fake and real images and pushes the generator to create compelling real-like images to fool the discriminator more effectively.
The research paper we are going to discuss proposes a super-resolution generative adversarial network (SRGAN), which uses a deep residual network (ResNet) with skip-connections, and loss functions that are tweaked to address the problem at hand.
Why adopt a GAN-based approach?
Despite there being various other techniques for SISR and numerous advancement in different convolutional neural networks, a GAN-based approach seems to perform the best, given current research efforts.
The reason for this is that the other techniques mentioned above tend to perform operations on the image that result in either: an image being upsampled completely based on the pixel values of the other pixels in it’s vicinity; or based on averaged out squared errors or filters, which smoothen edges and details in an image.
The GAN-based approach on the other hand, depends on generative modeling and thus attempts to build images that are natural and closely resemble the real ones so as to fool the discriminator. In an attempt to do so, the sharpness of the edges and the contrast is preserved.
Images
For training purposes, the images below were downsampled by a factor of r after applying a Gaussian filter for a blur smoothing effect. In terms of width (W), height (H), and number of color channels (C),image tensors would be:
- for low resolution Iᴸᴿ: (W*H*C)
- for high resolution Iᴴᴿ: (rW*rH*C)

Network Architecture
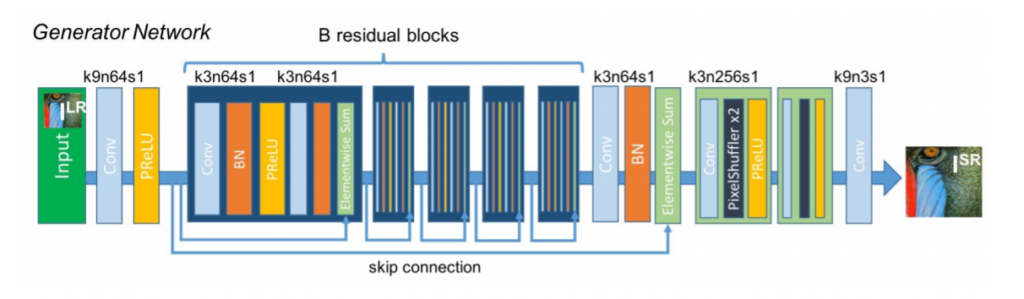
Generator
The generator network is created by appending B identical residual blocks, each consisting of 2 Convolutional layers with 3×3 kernels and 64 feature maps, followed by a batch normalization layer to reduce the effects of internal co-variate shifts. Residual blocks are used to better pass low-level information to the higher layers. A parametric ReLU is used as an activation function. To learn more about activation functions, refer to this article.
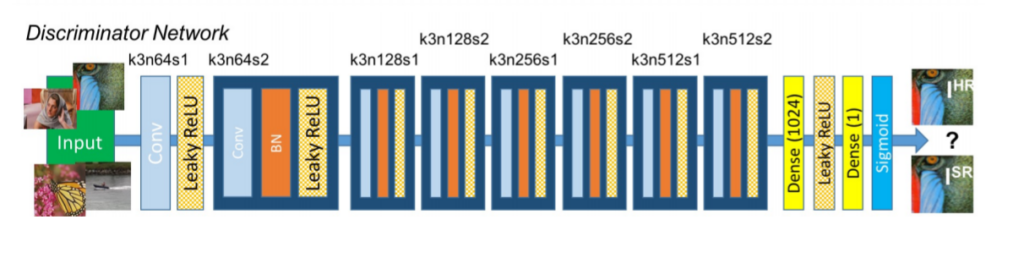
Discriminator
The discriminator network contains 8 convolutional layers of 3 × 3 filter kernels, increasing by a factor of 2 from 64 to 512 kernels. Strided convolution layers are used instead of max pooling layers.
Strided convolutions are preferred over pooling because they are a kind of convolution, and hence let the model learn new parameters and increase its expressiveness. Conversely, max pooling just selects the maximum value for a given group of pixels as output.
The resulting 512 feature maps are followed by 2 fully connected layers and a final sigmoid activation function for classifying real and fake images.
Loss function
To understand how well/poorly our model is working, we monitor the value of loss functions for several iterations. This helps us measure the accuracy of our model and understand how our model behaves for certain inputs. To learn more about loss functions, refer to this article.
Why not MSE (Mean Sqaured Error)?
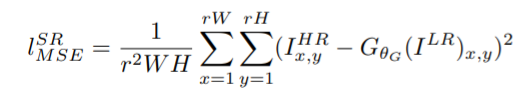
MSE is usually the go-to loss function for various machine learning problems. The problem of SISR cannot use MSE as its loss function for monitoring results. The reason being, MSE works on pixel-based difference in values, and minimizing the value of the loss function (in this case, MSE) will lead to overly-smooth textures, which are not desirable.
Thus the overall perceptual loss function has to be a linear combination of two losses:
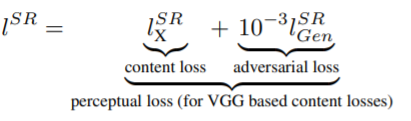
Content Loss
Instead of relying on pixel-wise losses, a part of the loss function should be dedicated to perceptual similarity. This content loss is thus based on pixel-wise differences between the activation layers of a VGG-10 Model. The VGG loss is defined as the Euclidean distance between the feature representations of a reconstructed image Gθ (Iᴸᴿ) and the reference image Iᴴᴿ. The activations between different combinations of layers can be tried and tested for to optimize results.
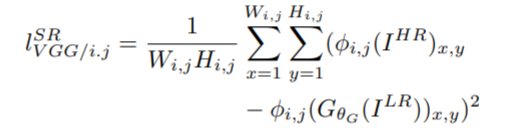
φi,j indicates the feature map obtained by the j-th convolution (after activation) before the i-th maxpooling layer within the VGG-10 network.
Adversarial Loss
The adversarial loss serves as a check on the image generated by the generator. Since the conventional generator generates an image from random or Gaussian noise, for the output image to resemble the input image, the low resolution image Iᴸᴿ is passed to the generator. Adversarial loss favors the generation of natural-looking images. Thus, it’s defined by the discriminator probabilities over all training images.
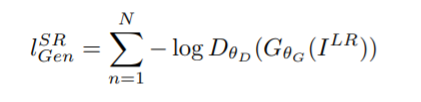
Training Parameters
The network was trained using a sample of 350,000 images from ImageNet. The low resolution images were obtained by downsampling the original images (BGR, C = 3) with a factor r = 4. The pixel values of Iᴸᴿ images were scaled to [0, 1] and pixel values of Iᴴᴿ images were scaled to [−1, 1]. The MSE loss was calculated on images of intensity range [−1, 1].
The learning rate was kept as 10⁻⁴ for 105 iterations, and then 10⁻⁵ for another 105 iterations. An Adam optimizer was employed with β1 = 0.9.
Results
The SRGAN model produced promising results, which were, visually-speaking, significantly better than any of the prior research done in the field of SISR. Some glimpses of the results are shown below:

Conclusion
In this post, we discussed image super-resolution as a real-world problem and discussed a state-of-the-art approach at length. Image super-resolution continues to be one of the most intriguing problems in deep learning and computer vision. The GAN-based approach seems to work well for the same.
Let me know if you want me to write more posts discussing research papers for interesting machine learning problems.
All feedback is welcome and appreciated — I’d love to hear what you think of this article.
Comments 0 Responses