
Human pose estimation refers to the process of inferring poses in an image. Essentially, it entails predicting the positions of a person’s joints in an image or video. This problem is also sometimes referred to as the localization of human joints. It’s also important to note that pose estimation has various sub-tasks such as single pose estimation, estimating poses in an image with many people, estimating poses in crowded places, and estimating poses in videos.
Pose estimation can be performed in either 3D or 2D. Some of the applications of human pose estimation include:
Some of the approaches used in the papers we’ll highlight are bottom-up and top-down. Essentially, in a bottom-up approach, the processing is done from high to low resolutions, while in top-down processing is done from low to high resolutions.
The top-down approach starts by identifying and localizing individual person instances using a bounding box object detector. This is then followed by estimating the pose of a single person. The bottom-up approach starts by localizing identity-free semantic entities, then grouping them into person instances.
We’ll now look at some research that’s been conducted in an attempt to solve the problem of human pose estimation:
- DeepPose: Human Pose Estimation via Deep Neural Networks
- Efficient Object Localization Using Convolutional Networks
- Human Pose Estimation with Iterative Error Feedback
- Stacked Hourglass Networks for Human Pose Estimation
- Convolutional Pose Machines
- DeepCut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation
- Simple Baselines for Human Pose Estimation and Tracking
- RMPE: Regional Multi-Person Pose Estimation
- OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
- Human Pose Estimation for Real-World Crowded Scenarios
- DensePose: Dense Human Pose Estimation In The Wild
- PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
DeepPose: Human Pose Estimation via Deep Neural Networks (CVPR, 2014)
This paper proposes using deep neural networks(DNNs) to tackle this ML task. The authors of this paper are Alexander Toshev and Christian Szegedy from Google. The formulation of the pose estimation itself is a DNN-based regression on the joints. The authors achieve state of the art results on standard benchmarks such as the MPII, LSP, and FLIC datasets. They also analyze the effects of jointly training a multi-staged architecture with repeated intermediate supervision.
The DNN is able to capture the content of all the joints and doesn’t require the use of graphical models. As seen below, the network is made up of seven layers. A pooling layer, a convolution layer, and a fully-connected layer form part of these layers.
The convolution layer and fully-connected layer are the only layers that have learnable parameters. They both contain linear transformations followed by a rectified linear unit. The network takes an input image of size 220 × 220 and the learning rate is set to 0.0005. The dropout regularization for the fully-connected layers is set to 0.6. Some of the datasets used in this model are Frames Labeled In Cinema (FLIC) and Leeds Sports Dataset.

The figure below shows the performance of the model on the Percentage of Correct Parts (PCP) metric.


Efficient Object Localization Using Convolutional Networks (2015)
This paper proposes a ConvNet architecture that predicts the location of human joints in monocular RGB images. The authors of this paper are from New York University. The model allows for increased pooling that improves computational efficiency.
The network first performs body part localization and outputs a low-resolution per-pixel heatmap. This heatmap shows the probability of a joint occurring at each spatial location in the image.

The paper also introduces a network that uses the features from the hidden layer from the heatmap regression model in order to increase localization accuracy. The model uses a multi-resolution ConvNet architecture and implements a sliding window detector that has overlapping contexts to produce a coarse heatmap output. A sliding window is usually a rectangular box that has a fixed height and width. The box slides across the image. As the box slides the classifiers try to identify whether that section has an object that is of interest to the task at hand.

The figure below shows the full model architecture proposed in this paper. This architecture is implemented with Torch7 and evaluated using FLIC and MPII-Human-Pose datasets.

The model’s performance is evaluated using the standard PCK (Percentage of Correct Keypoints) measure on the FLIC dataset and the PCKh measure on the MPII dataset.


Human Pose Estimation with Iterative Error Feedback (2016)
This paper proposes a framework that extends the expressive power of hierarchical feature extractors to include both input and output spaces. It does this by introducing top-down feedback. The authors of this paper are from UC Berkeley.
Outputs are not predicted in one go; however, a self-correcting model that feeds back the error predictions is used. The authors call this process Iterative Error Feedback (IEF). The model produces great results on the task of articulated pose estimation on the challenging MPII and LSP benchmarks.
The figure below shows an implementation of Iterative Error Feedback (IEF) for 2D human pose estimation. The left panel shows the input image I and the initial guess of keypoints Y0. The three key points here correspond to the right wrist (green), left wrist (blue), and top of the head (red). The function f in this architecture is modeled as a convolutional neural network. The function g converts each 2D keypoint position into one Gaussian heatmap channel.


This model can be visualized using this mathematical equation on the left.

The table shown below represents the performance of this model.

Stacked Hourglass Networks for Human Pose Estimation (2016)
This paper argues that repeated bottom-up and top-down processing with intermediate supervision improves the performance of their proposed network. The network is referred to as a “stacked hourglass” because of the successive processes of polling and upsampling that are performed to produce the final predictions. The authors of this paper are from the University of Michigan.

The network was tested on the FLIC and MPII Human Pose benchmarks. It achieves more than 2% improved accuracy on average on MPII across all joints, and between 4–5% improved accuracy on difficult joints such as ankles and knees.

The hourglass architecture is designed to capture information at every scale. The network outputs pixel-wise predictions. The set up of the network has a convolution layer and max-pooling layers that are used for feature processing. The network outputs heatmaps that predict the occurrence of specific joints at each pixel-level.

The figure below shows the performance of the model on various body parts.

Convolutional Pose Machines (2016)
This paper introduces Convolutional Pose Machines (CPMs) for articulated pose estimations. CPMs are made up of a sequence of convolution networks that produce a 2D belief map for the location of each part. This paper is from the Robotics Institute Carnegie Mellon University.
At every stage in a CPM, the image features and belief maps produced in the preceding stage are used as input.

The network learns implicit spatial models through a sequential composition of convolutional architectures. It also introduces a systematic approach to designing and training such an architecture in order to learn image features and image-dependent spatial models for structured prediction tasks. This doesn’t require the use of any graphical model style inference.
The network is tested on the MPII, LSP, and FLIC datasets.

The model’s PCKh-0.5 score achieves state-of-the-art results at 87.95% and a PCKh0.5 score of 78.28% on the ankle. It has been implemented using Caffe, and the code has been open-sourced.

DeepCut: Joint Subset Partition and Labeling for Multi-Person Pose Estimation (CVPR 2016)
This paper proposes a method for detecting poses in images with multiple people. The model works by detecting the number of people in an image and then predicting the joint locations for each image. This paper is by Max Planck Institute and Stanford University.

In order to obtain strong part detectors, the authors adapt FastRCN for the task. They alter it in two ways; proposal generation and detection region size. The performance of this model in predicting various body parts is shown below.

Since using proposals for body part detection may be suboptimal, the authors use a fully-convolutional VGG that has a stride of 32 px and reduce that stride to 8 px. They then scale the image input to a standing height of 340 px, and this obtains the best results.
For the loss function, they first try the softmax that outputs the probabilities of different body parts. Later, they implement the sigmoid activation function on the output neurons and cross-entropy loss. In the end, they found out that the sigmoid activation function obtains better results than the softmax loss function. The model is trained and evaluated on Leeds Sports Poses (LSP), LSP Extended (LSPET), and MPII Human Pose.


Simple Baselines for Human Pose Estimation and Tracking (EECV, 2018)
This paper’s pose estimation solution is based on deconvolutional layers added on a ResNet. The model achieves an mAP of 73.7 on a COCO test-dev split. Its pose tracking model achieves an mAP score of 74.6 and a MOTA (Multiple Object Tracking Accuracy) score of 57.8. The authors of this paper are from Microsoft Research Asia and the University of Electronic Science and Technology of China.
The method used in this network adds a few deconvolutional layers over the last convolution stage in the ResNet architecture. This structure makes it very easy to generate heatmaps from deep- and low-resolution images. Three deconvolutional layers with batch normalization and ReLU activation are used by default.

The figure below shows the proposed flow of the pose tracking framework. Pose tracking in a video is done by first estimating the human pose, giving it a unique identifier, and then tracking it across the frames.

Below is a comparison of this model to other models.

RMPE: Regional Multi-Person Pose Estimation (2018)
This paper proposes a regional multi-person pose estimation (RMPE) framework for estimation in inaccurate human bounding boxes. The framework consists of three components: a Symmetric Spatial Transformer Network (SSTN), Parametric Pose NonMaximum-Suppression (NMS), and a Pose-Guided Proposals Generator (PGPG). This framework achieves a 76.7 mAP on the MPII (multi-person) dataset. The authors of this paper are from shanghai Jiao Tong University, China and Tencent YouTu.

In this framework, the bounding boxes obtained by the human detector are fed into the “Symmetric STN + SPPE” module. The pose proposals are then generated automatically. These poses are fine-tuned by parametric pose NMS in order to obtain the estimated human poses. At training, “Parallel SPPE” is introduced in order to avoid the local minima.

The figure below shows the performance of the model in comparison to other frameworks, as well as some of the pose predictions obtained by it.

OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (2019)
OpenPose is an open-source real-time system for multi-person 2D pose detection, including body, foot, hand, and facial keypoints. This paper proposes a real-time approach for detecting 2D human poses in images and videos. This proposed method uses nonparametric representations known as Part Affinity Fields (PAFs). Some of the authors of this paper are from IEEE.

As shown below, this method takes an image as the input for a CNN and predicts confidence maps for detecting body parts and PAFs for part association. This paper also presents an annotated foot dataset with 15K human foot instances. The dataset has been publicly released.

The network architecture iteratively predicts affinity fields that encode part-to-part association (shown in blue) and detection confidence maps (shown in beige).

OpenPose is also the surrounding software and API that has the ability to fetch images from a variety of sources. For example, one can select the input as a camera feed, webcam, video, or image. It runs on different platforms such as Ubuntu, Windows, Mac OS X, and embedded systems (e.g., Nvidia Tegra TX2). It also provides support for different hardware, such as CUDA GPUs, OpenCL GPUs, and CPU-only devices.
OpenPose has three blocks; body+foot detection, hand detection, and face detection. It has been evaluated on the MPII human multi-person dataset, COCO keypoint challenge dataset, and the paper’s proposed foot dataset. The figure below shows the results obtained by OpenPose in comparison to other models.

Human Pose Estimation for Real-World Crowded Scenarios (AVSS, 2019)
This paper proposes methods for estimating pose estimation for human crowds. The challenges of estimating poses in such densely populated areas include people in close proximity to each other, mutual occlusions, and partial visibility. The authors of this paper are from the Fraunhofer Institute for Optronics and Karlsruhe Institute of Technology KIT.

One of the methods used to optimize pose estimation for crowded images is a single-person pose estimator using the ResNet50 network as the backbone. The method is a two-stage, top-down approach that localizes each person and then performs a single-person pose estimation for every prediction.
The paper also introduces two occlusion detection networks; Occlusion Net and Occlusion Net Cross Branch. Occlusion Net splits after two transposed convolutions so a joint representation can be learned in the previous layers. The Occlusion Net Cross Branch splits after one transposed convolution. The Occlusion Detection Networks output two sets of heatmaps per pose. One heatmap for the visible keypoints, and the other for occluded keypoints.

The table below shows the performance of this model compared to other models.

DensePose: Dense Human Pose Estimation In The Wild (2018)
This is a paper from INRIA-CentraleSupelec and Facebook AI Research, whose objective is to map all human pixels of an RGB image to the 3D surface of the human body. It also introduces a DensePose-COCO dataset. This is a dataset with image-to-surface correspondence of 50K COCO images that have been manually annotated. The authors then use this dataset to train CNN-based systems that deliver dense correspondence in the presence of background, occlusions, and scale variations. Correspondence is basically a representation of how images in one image correspond to the pixels in another image.

In this model, a single RGB image is taken as input and used to establish a correspondence between surface points and image pixels.

The approach in this model has been built by combining with the Mask-RCNN system. The model operates at 20–26 frames per second on a GTX 1080 GPU for a 240 × 320 image and 4–5 frames per second on a 240 × 320 image.

The authors have combined the Dense Regression (DenseReg) system with the Mask-RCNN architecture to come up with the DensePose-RCNN system.

The model uses a fully-convolutional network that’s dedicated to generating a classification and a regression head for assignment and coordinate predictions. The authors use the same architecture used in the keypoint branch of MaskRCNN. It consists of a stack of 8 alternating 3×3 fully convolutional and ReLU layers with 512 channels.

The authors run experiments on a test set of 1.5k images containing 2.3k humans and a training set of 48K humans. The figure below is a comparison of its performance in relation to other methods.


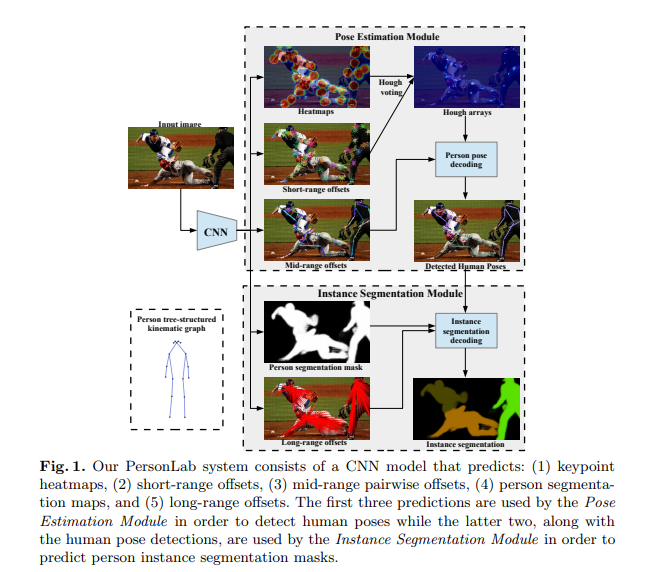
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model (2018)
The authors of this paper are from Google. They present a box-free bottom-up approach for pose estimation and instance segmentation for images with multiple people.

This means that the authors first detect body parts and then group these parts into human instances. The approach achieves COCO test-dev keypoint average precision of 0.665 using single-scale inference and 0.687 using multi-scale inference.
The model proposesd in this paper is a box-free, fully convolutional system that first predicts all the key points for every individual in an image. The model is trained on the COCO keypoint dataset.
At the keypoint detection stage, the model detects visible key points of a person in the image. The PersonLab system was evaluated on the standard COCO keypoints task and on COCO instance segmentation for the person class only.
The figure below shows its performance on the COCO keypoints test-dev split.

Conclusion
We should now be up to speed on some of the most common — and a couple of very recent — techniques for performing human pose estimation in a variety of contexts.
The papers/abstracts mentioned and linked to above also contain links to their code implementations. We’d be happy to see the results you obtain after testing them.
Comments 0 Responses