
Summary
This tutorial covers how to set up DeepLab within TensorFlow to train your own machine learning model, with a focus on separating humans from the background of a photograph in order to perform background replacement—also known as image segmentation.

Key Learnings
More generally, this article might be a good introduction for beginners without a lot of code experience in learning how to:
- Prepare a dataset, including scraping, processing, resizing, and renaming things without having to write a bunch of code
- Train a machine learning model in TensorFlow
- Visualize the results of machine learning model training
- Refine segmentation masks with OpenCV
- Automate the background replacement process
Take Me Straight to…
- Part 1: collecting a dataset that is training-ready
- Part 2: training DeepLab on your dataset
- Part 3: visualizing the results of the training, and performing background replacement using OpenCV.
I Just Want to Watch
If you would rather watch this in a video walkthrough format, you can find that here, on YouTube.
Part 1: Creating a Dataset
In this phase you will:
- set up your environment for DeepLab
- scrape images from google for use in model training
- generate segmentation masks for your images that Deeplab can learn from
- get your dataset into a format that works with Deeplab and Tensorflow
Let’s get started.
Installation Process
Create a Python3 Environment with Pip
You may already have a great environment set up for using Python / TensorFlow. If you don’t, Anaconda is a great way to go and is a one-click install.
- With anaconda navigator (or conda) / pyenv / virtualenv, create an environment with Python 3.7.4, and activate it:
- Anaconda has pip preinstalled. If not using anaconda, make sure you have pip installed. Follow these directions if you’re working on a Mac.
Clone the DeepLab Models GitHub Repo
Clone the official TensorFlow models repo
You’ll only need the models/research/deeplab and models/research/slim directories. You can delete everything else.
Merge the files from the tutorial repo into the TensorFlow models repo
Clone or download this repo, and put everything into the directory you just created for the TensorFlow models repo. But don’t overwrite anything *except the input_preprocess.py file in the deeplab directory, which has a small change.
For example, put models/research/eval-pqr.sh into the TensorFlow models/research directory.
Install TensorFlow
- From the models/research/ directory, install TensorFlow:
If you have a CUDA-compatible GPU, You can use tensorflow-gpu instead of TensorFlow.
- Install Pillow — this library helps you process images (Python Image Library):
- Install other needed dependencies:
Make sure to follow the steps in the link to ensure that you can run model_test.py:
Pay special attention to this step:
This command has to be run each time you activate your python environment or open the terminal window.
And also make sure—especially if you’re running multiple Python environments—that you always use python3 and pip3 for every command you run (instead of python and pip). This will save you lots of headaches.
Image Preparation Process
Notes
- Run all python commands with python3
- Run all pip commands with pip3
- Must run:
for each terminal session
Dependencies
- Python V3.7.4
- TensorFlow > 1.14 and < 2.0
Making a dataset
You’ll need a consistent background image, and a large set of transparent (or masked) foreground images with photos of people. You’ll want to composite each foreground image onto the background.
Make sure the background image is representative of the background image you’ll be using for real-time photo replacement.
Make sure the foreground images represent the diversity of photos you’ll likely expect in a live scenario. For best results, consider things like:
- Proximity to camera
- Number of people in photos
- Race and gender
- Clothing styles (loose or tight, patterned, dark, light)
- Proximity to each other (touching, hugging, distance apart—both depthwise and horizontally)
- Poses (sideways, front facing, smiling, acting, etc)
- Props (people holding things, wearing hats or masks, etc)
- Lighting conditions (e.g. high contrast or shadowy, multiple light sources, indoor, outdoor)
Scraping Images
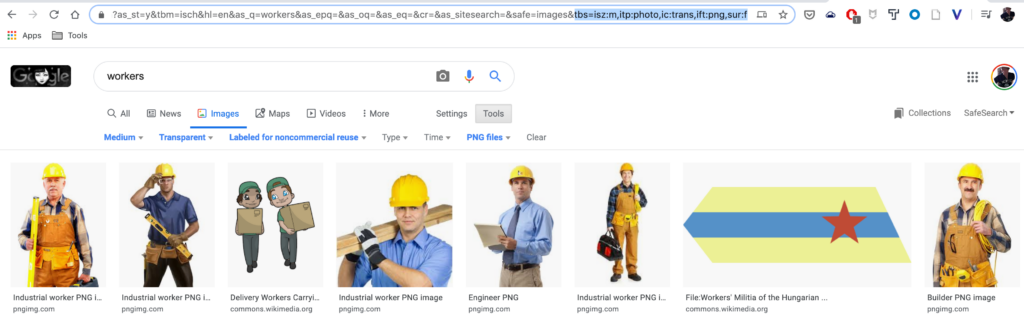
The utilities/scrapeImages.py file is useful in downloading images from Google.
You should first edit the scrapeImages.py file to use your desired query string. Look for:
The tbs= param in this case does the following:
- ism:m downloads medium-sized images
- itp:photo – downloads only photo type images
- ic:trans downloads only images with transparency
- ift:png downloads only images of file type transparency.
To use your own parameters, do an advanced Google search for the type of images you want, and take a look at the query string in the URL bar of your browser for what tbs parameters it generates for you, and replace them here.
You then run the scraper as follows:
Changing [your_search_term] and the value of the –directory flag to where you want to save images to.
Creating Segmentation Images

You’ll need to create a new set of images that merges each transparent foreground image onto the consistent background.
You’ll also need to create a new set of images where the background is black, and the transparent foreground image matches the color you’re trying to segment—in this case “Person”, which is color rgb(192,128,128).
Both sets of images—the “regular” and “segmented” images—should have the same size and match each other exactly in terms of the position and scale of the foreground subjects in relation to the background. See this example:
Regular Image

Segmented Image

The photoshop actions section below has a set of useful actions for accomplishing this properly in Photoshop.
You should make a directory within the models/deeplab/datasets directory. Call it whatever you like (in this case, we used PQR).
Within that folder, make another folder called JPEGImages and place all the “regular” images inside it.
Photoshop Actions
If you know how to use Photoshop actions, this repo contains a set of actions that will help convert and merge your photos. Go to window > actions in Photoshop and choose load actions and load the glowbox.atn file.
To run these actions in a batch, you’ll want to go to File > Automate > Batch in Photoshop, and select the desired action: the folder location of your foreground images. The destination should be None, as the action itself contains a save command.
To edit any of the actions, you’ll want to select the step of the action from the actions panel and double click it, modifying the desired parameters.
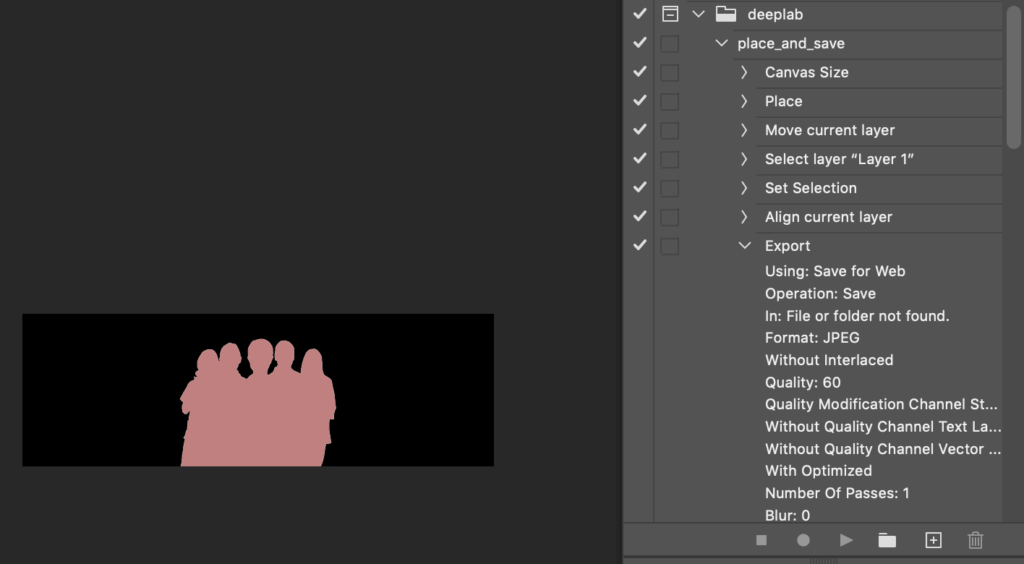
place_and_save
This action:
- Takes a loaded image.
- Resizes the canvas to the size of your background image and places that image as a layer.
- Moves your foreground image to the bottom center of the photo.
- Exports the image as a 60% quality jpeg.
Make sure to edit the action to specify the location of your background image, the canvas size matching your background image’s size, and the desired export quality. Also, make sure the export location doesn’t overwrite your transparent foreground images—you’ll need those to create your segmentation masks.
segment
This action:
- Takes the transparent images and resizes the canvas to match the dimensions of your chosen background image.
- Aligns the transparent foreground image to the bottom center of the canvas.
- Makes a background and fills it with black (the segmentation color for background in DeepLab)
- Makes a selection of the foreground and fills it with the proper color for the Person segmentation in DeepLab: RGB(192,128,128)
- Exports the image as a 60% quality jpeg.
If you aren’t trying to identify people in your photos, make sure to edit the action to specify the desired color segmentation for your images. You can see the DeepLab (ResNet) color segmentation scheme here.
convert_to_indexed
You don’t have to run this action if you used the segment action above.
However, if you already have images, this action just ensures that the color for the segmentation mask is exact, forcing a pink-ish color to the exact pixel values. Photoshop, for example, does some adjustment of colors on a normal save to match your screen’s color profile. You can prevent having to run this action at all if saving from Photoshop by ensuring that the convert to sRGB option in the save for web dialog is unchecked.
merge_segmentation
This action doesn’t need to be run until after all of your model training and image generation has been done. Essentially it’s the last step, helping you to visualize how well your machine learning-generated masks actually mask or segment your subject. It does the following:
- Adds both the regular image and the segmentation masks as layers
- Selects the color range matching the segmentation layer
- Draws a mask around the regular image
You end up with 3 layers — one with the untouched photo, one with the segmentation mask, and one with your regular image masked off to show how well the background was removed and the subjects were isolated.
Convert your RGB segmentation images to indexed colors
In order to reduce the number of dimensions of processing DeepLab has to do on each image, we’ll be converting each found RGB color in the segmentation images you made (i.e. RGB(192,128,128)) to an indexed color value (i.e. 1). This will make processing a lot faster.
This repo includes a file in the deeplab/datasets/ directory called convert_rgb_to_index.py, which will help you accomplish that.
Before running, make sure to edit the following:
If you aren’t processing people, the palette should contain all of the segmentation colors you’re trying to detect. In our case, since we’re just looking for people, the palette contains black for the background as index 0, and pink for the foreground as index 1.
label_dir: this is the path (relative to the datasets directory where this file is contained) where your Segmentation Class images were saved. Make sure to change it if your file locations differ.
new_label_dir: this is the path where your newly-generated images will be saved. You don’t need to make this directory, it will be generated for you.
To run the script, from the datasets directory, run: python3 convert_rgb_to_index.py. You’ll need to make sure all of this file’s dependencies are installed via pip:
- pip3 install Pillow tqdm numpy
Once it runs, you should have a new folder SegmentationClassRaw (or whatever you called the new_label_dir folder). It should contain a list of .png images. They will all look black. This is normal. We converted the RGB values into single index values, so a standard image viewer won’t understand this format.

Make a list of all your training and test images
Make another folder at the same level as JPEGImages called SegmentationClass (see the folder structure section below for a better sense of the entire folder structure you’ll be adding to DeepLab). This folder will contain all your segmented images.
Deciding how to divide up your train and validation set is up to you. Ideally, you’d have at least 500 training images, and at least 100 test images. A good starting split might be a 10:1 ratio of training to test images.
Generate the tfrecord folder
TensorFlow has a tfrecord format that makes storing training data much more efficient. We’ll need to generate this folder for our dataset. To do so, this repo has made a copy of the build_voc2012_data.py file, which has been saved as a new file (in our case build_pqr_data.py).
Edit the build_pqr_data.py file, and make sure there’s a flag for our model’s desired folders. In this case, look at ~line80:
Make sure to change any of those directories to match where your files are located. In this instance, the tfrecord folder should exist. The script won’t make it for you. Also note that at around Line 119, I’ve hardcoded the input format to be .jpg:
and the output images to be .png, due to an issue I had with the script utilizing the label_format flag:
You should change those extensions to match the extensions of your own images if they differ.
Now you can run the file (from the datasets directory):
Once this is done, you’ll have a tfrecord directory filled with .tfrecord files.
You’re finally ready to train the model!
Part 2: Training a model on your dataset
Folder Structure
Make sure your folder structure looks similar to this. It should if you followed all of the naming conventions in the above steps:

Download the Pascal Training Set
In order to make our training much faster, we’ll want to use a pre-trained model—in this case, pascal VOC2012. You can download it here. Extract it into the PQR/exp/train_on_tranval_set/init_models directory (should be named deeplabv3_pascal_train_aug).
Edit your training script
First, edit your train-pqr.sh script (in the models/research) directory:
Things you may want to change:
- Make sure all paths are correct (starting from the models/research folder as CURRENT_DIR)
- NUM_ITERATIONS: this is how long you want to train for. For me, on a MacBook Pro without GPU support, it took about 12 hours just to run 1000 iterations. You can expect GPU support to speed that up about 10X. At 1000 iterations, I still had a loss of about .17. I would recommend at least 3000 iterations. Some models can be as high as about 20000. You don’t want to overtrain, but you’re better off overtraining than undertraining.
- train_cropsize: This is the size of the images you’re training on. Your training will go much faster on smaller images. 1000×667 is quite large, and I’d have done better to reduce that size a bit before training. Also, you should make sure these dimensions match in all three scripts: train-pqr,eval-pqr, and vis-pqr.py.
- The checkpoint files (.ckpt) are stored in your PQR_FOLDER and can be quite large (mine were 330 MB per file). However, periodically (in this case every 4 checkpoint files), the oldest checkpoint file will be deleted and the new one added—this should keep your hard drive from filling up too much. But in general, make sure you have plenty of hard drive space.
Start training:
You’re finally ready to start training!
From the models/research directory, run sh train-pqr.sh.
If you’ve set everything up properly, your machine should start training! This will
take.
a.
long.
time.
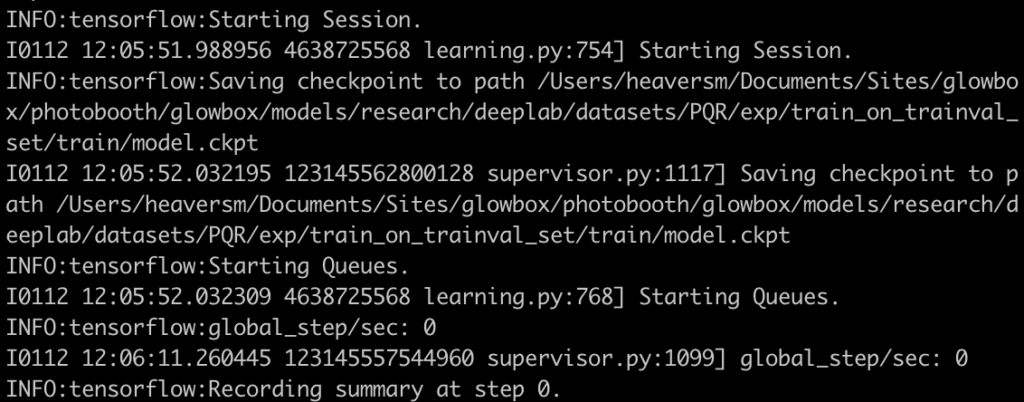
You should be seeing something like this in your terminal:
Evaluation
Running eval-pqr.sh from the same directory will calculate the mean intersection over union score for your model. Essentially, this will tell you the number of pixels in common between the actual mask and the prediction of your model:

In my case, I got a score of ~.87 , which means essentially 87% of the pixels in my prediction mask were found in my target mask. The higher the number here, the better the mask.
Part 3: Visualization
To visualize the actual output of your masks, run vis-pqr.sh from the models/research directory. These will output to your visualization directory you specified (in our case, models/research/deeplab/datasets/PQR/exp/train_on_trainval_set/vis/segmentation_results).
You will see two separate images for each visualization: the “regular” image, and the “prediction” (the segmentation mask).
If you want to combine these two images, the merge_segmentation Photoshop action can help.
I’ve also set this up as an automated process in OpenCV, to take an image and its segmentation mask and automatically substitute in a background of your choosing. I’ll cover how to set that up next.
Using OpenCV for background replacement
Install OpenCV
Follow these directions to install OpenCV on Mac — but use version 4.1.2 instead of 4.0:
Give your virtual environment a name of cv, then workon cv.
Rename/usr/local/lib/python3.7/site-packages/cv2/python-3.7/cv2.cpython-37m-darwin.so to cv2.so
Then cd /Users/[your_username]/.virtualenvs/cv/lib/python3.7/site-packages
Then ln -s /usr/local/lib/python3.7/site-packages/cv2/python-3.7/cv2.so cv2.so
The cv Python virtual environment is entirely independent and sequestered from the default Python version on your system. Any Python packages in the global directories will not be available to the cv virtual environment. Similarly, any Python packages installed in site-packages of cv will not be available to the global install of Python.
Directory Structure
Navigate to the cv directory. You should have the following directory structure:
- /input: contains the images whose background you want to replace
- /masks: contains the segmentation masks that will separate the foreground from the background (people from everything else).
- /output: where the photos with the replaced background will be saved
- /bg: contains the background image that will be used as the replacement.
- replacebg_dd.py: the Python script that utilizes OpenCV to handle background replacement.
Using the replacebg.py script
Before calling the script, check the following lines within the script:
These directories should match your directories relative to the replacebg.py script.
initial_threshold_val = 150: Changing this value will change the black / white value above which the foreground is kept, rather than the background.
Script Options
The Python script is responsible for handling what pixels to keep from the source vs which to throw away, and it can do some basic thresholding and blurring of the mask image to attempt to improve results.
There are a few parameters you can pass to the replacebg.py script:
- –image (i.e. replacebg.py –image 36) would show (but not save) the image numbered 36.
- –generate (i.e. replacebg.py –generate 20) would save out the first 20 images.
- –all (replacebg.py –all) would save out all images (provided you manually keep the num_inputs variable synched with however many files you have in your input directory).
- replacebg.py –start 20 would generate images between the 20th and num_inputs photos.
- replacebg.py –start 20 –end 30 would generate images between the 20th and 30th photos in the directory.
Keyboard commands
When you run the script and it’s displaying an image, you can use the following keyboard commands:
- z increases the threshold, tightening up on the subjects and revealing more of the substituted background
- x decreases the threshold, showing more of the source photo
- s saves the image out
- q quits the window and script execution
- i cycles to the next image in the sequence
NOTE:
This tutorial and repo were created through my difficulties installing and training DeepLab, in the hopes that it would make things easier for others trying to do the same. Very little of the code is my own and has been assembled from a variety of sources — all of which were extremely helpful, but none of which I was able to follow on their own in order to successfully train DeepLab. By combining various pieces of the following links, I was able to create a process that worked smoothly for me.
Links:
Analytics Vidhya — Semantic Segmentation: Introduction to the Deep Learning Technique Behind Google Pixel’s Camera!, Saurabh Pal
Installing TensorFlow — Official Documentation
Installing DeepLab — Official Documentation
Tensorflow-Deeplab-Resnet — Dr. Sleep
Free Code Camp — How to use DeepLab in TensorFlow for object segmentation using Deep Learning, Beeren Sahu
Dataset Utils — Gene Kogan — useful in scraping images for a dataset and creating randomly sized, scaled, and flipped images in order to increase the training set size.
Comments 0 Responses