
In recent years, research related to vision-based 3D image processing has become increasingly active, given its many applications in virtual reality (VR) and augmented reality (AR). Despite years of studies, however, there are still images that machines struggle to understand—one of those is images of human hands.
Hand image understanding targets the problem of recovering the spatial configuration of hands from natural RGB or/and depth images. This task has many applications, such as human-machine interaction and virtual/augmented reality, among others.
Estimating the spatial configuration of hand images is very challenging due to the variations in appearance, self-occlusion, and complex articulations. While many existing works considered markerless image-based understanding, most of them require depth cameras or multi-view images to handle these difficulties.
Considering RGB cameras are more widely available than depth cameras, some recent work has started looking into 3D hand analysis from monocular RGB images, mainly focusing on estimating sparse 3D hand joint locations while ignoring dense 3D hand shapes.
However, many immersive VR and AR applications often require accurate estimation of both 3D hand pose and 3D hand shape. This brings about a more challenging task: How can we jointly estimate not only the 3D hand joint locations, but also the full 3D mesh of a hand’s surface from a single RGB image?

In this post, I’m going to review “End-to-end HAnd Mesh Recovery from a Monocular RGB Image” (or HAMR for short), which presents a new 3D hand shape and pose estimation framework for humans’ hands. Specifically, HAMR uses a single RGB image to estimate a full 3D mesh.
Table of Contents
- The Novelty
- HAMR: HAnd Mesh Recovery
- Experiments and Results
- Discussion
- Conclusion
1. The Novelty
Human Pose Estimation refers to the problem of localization of human joints (also known as keypoints — elbows, wrists, etc) in images or videos. It’s also defined as the search for a specific pose in the space of all articulated poses.
While most previous approaches focus only on pose (Figure 1. second column) and ignore 3D human hand shape, here the proposed approach provides a solution that’s fully automatic and estimates a 3D mesh capturing both pose and shape from a 2D image (Figure 1. fifth & sixth columns).
In this approach, the problem is solved in two steps. First the authors estimate 2D joints using a recently proposed convolutional neural network (CNN) called DeepCut. Consequently, there’s a second step, which estimates 3D pose and shape from the 2D joints using a 3D generative model called MANO.
Note that there’s a great deal of work on the 3D analysis of humans from a single image. Most approaches, however, focus on recovering 3D joint locations. The joints alone are not the full story. Joints are sparse, whereas the human body is defined by a surface in 3D space.
2. HAMR: HAnd Mesh Recovery
The main goal of the paper is to present a unified framework for providing a detailed mesh representation M together with 2D keypoints Φ_2D and 3D joint locations Φ_3D of a hand from a single RGB image. The paper exploits a recent parametric generative model for generating hand meshes, called MANO.
The model architecture then infers hand pose from this generated mesh. The overall architecture of the paper’s framework is illustrated in Figure. 2.

2.1. 2D Pose Estimation
Similar to other recent methods, the authors employ a cascade encoder-decoder network to predict the 2D Gaussian like heat-maps for 2D pose estimation, which is noted as Φ in Equation 1 below.

Here, K indicates the number of joints and {H, W} are the resolutions of the heat-maps. Each keypoint has a corresponding heat-map, and each pixel value on the heat-map indicates the confidence of the keypoint located in that given 2D position.
In addition, as perspective ambiguity cannot be resolved when applying direct regression from 3D pose heat-maps, the authors concatenate the intermediate-layer features with the M heat-maps, and then feed them into the following iterative regression module for additional information.
2.2. Hand Mesh Recovery
MANO (hand Model with Articulated and Non-rigid defOrmations) is utilized as the generic 3D hand model in the HAMR framework. In particular, MANO factors hand mesh into its shape — it mainly models hand properties such as finger slenderness and palm thickness and pose.
MANO parameterizes a triangulated mesh M ∈ R^{N×3} with a set of parameters θ_mesh = {β , θ }, where β ∈ R¹⁰ denotes the shape parameters and θ ∈ R^{K×3} denotes the pose parameters. Technically speaking, β represents the coefficients of PCA components that sculpt the identity subject, and θ denotes the relative 3D rotation of K joints on a Rodrigues Vector representation.

For the enthusiastic reader:
For more details on “MANO” check out the formal project page or check out their video demo.
Given the recovered mesh, The 3D joint locations Φ_3D can be computed via linear interpolations between the vertexes of the mesh, while also obtaining the 2D joint locations Φ_2D with a projection of the 3D joints.
More specifically:
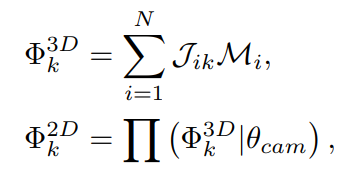
where Φ_3D is a set of 3D coordinates (x,y,z) for each of the keypoints K. Φ_2D is a set of corresponding 2D coordinates (u,v) in camera space. θ_cam={(s,tx,ty)} denotes the camera parameters.
Lastly the 3D-to-2D projection function can be defined as:

where the authors use a weakly perspective camera model, i.e. an orthographic projection.
2.3. Iterative Regression Module
A regression module is applied to fit the camera parameters θ_cam and the mesh parameters θ_mesh. However, the complicated domain gap makes it difficult to produce reasonable estimates in one go.
Inspired by several previous works that revealed that a cascade and coarse-to-fine method is more appropriate than a one-pass solution, an iterative regression module was implemented.The iterative regression module is designed to fit the camera and mesh parameters from semantic features extracted from previous 2D pose modules.

Intuitively, the current parameters θ are taken at time t as additional inputs upon the image features, thus yielding an estimate of a more accurate θ at time t+1. As illustrated in Figure. 3, the iterative regression module consists of a simple fully convolutional encoder and multiple fully connected layers.
The predictions are strong supervised by utilizing a ground-truth of the camera parameters computed from paired 3D and 2D annotations.
2.4. Loss
For the target to recover the hand mesh from a single RGB image, a deep convolutional network is leveraged to fit the mesh parameters θ_mesh.
However, in a real-world scenario, it’s almost impossible to obtain the ground-truth mesh parameters when annotating from single RGB images. Fortunately, the HAMR framework can define derived 3D and 2D joint locations from the mesh. By doing so, HAMR is trained with widely-available 3D and 2D annotations, thus enabling the mesh reconstruction.
HAMR defines the overall loss function as follows:

Here, L2 loss is employed between the derived 3D and 2D representations and ground-truth labels, which results in L3D and L2D, respectively. Additionally, the geometric constraints are reformulated as regularizers leading to Lgeo, which defines over the predicted 3D poses (more details about geo loss can be found in the paper).
Furthermore, L2 loss is utilized to supervise the estimated camera parameters with ground-truth camera parameters leading to Lcam. Finally the model penalizes the misalignment between the rendered mask and ground-truth silhouette via L1 loss, leading to Lseg (more details about seg loss can be found in the paper).
The whole process is fully differentiable with respect to all the learnable parameters, thus making the HAMR framework trainable from end-to-end.
3. Experiments & Results
To evaluate the efficacy of HAMR, qualitative results are initially presented on the recovered mesh from single RGB images. Secondly, since there exists no ground-truth mesh representation for comparison study, the authors quantitatively evaluate the superiority of HAMR on the task of 3D and 2D hand pose estimation instead.

3.1. Visualization of Appealing Mesh
In order to verify the quality of the generated mesh and the robustness of the framework in various cases, some representative samples from STB and RHD testing sets are illustrated in Figure. 4.
Experiments demonstrate that the HAMR framework is capable of generating high-quality, appealing hand meshes. Further, the HAMR framework is robust enough to reconstruct hand meshes accurately, even in very difficulty scenarios with poor lighting, image truncation, self-occlusion, and exaggerated articulation, among others.
3.2. Quantitative Evaluation
HAMR is evaluated on the performance of 3D hand pose estimation in regards to the measure of the area under the curve (AUC) on the percentage of correct keypoints (PCK) score with different thresholds. All of the comparison methods are evaluated on both RHD, STB, and Dexter datasets. These experimental results are shown in Figure. 5.

On the STB dataset, the 3D PCK curves are intertwined with each other, since the STB dataset is relatively small and lacks diversity. The HAMR method performs competitively in comparison to other methods, which is reasonable considering the saturated performance on this dataset.
In contrast, the RHD dataset is relatively complex and more diverse. Here, the HAMR method is superior to those proposed and achieves state-of-the-art results. Similarity, on the Dexter Object dataset, HAMR method largely outperforms most state-of-the art methods. It’s consistent with the authors’ expectation that introducing the parametric hand model can greatly help in solving the perspective ambiguity issue, which in turn improves the accuracy of hand pose estimation.
4. Discussion
In this post, I presented HAnd Mesh Recovery (HAMR), a framework designed to tackle the problem of reconstructing a full 3D mesh of a human hand from a single RGB image.
Hand image understanding is a widely-researched topic and has many real-world vision applications. While hand pose estimation has been well studied in the literature, there still exists little research on the problem of hand mesh recovery from single RGB images.
The proposed HAMR architecture enriches this field by leveraging a generic 3D hand model to achieve a mesh representation. With the mesh model, the framework can produce 2D and 3D hand pose estimations as well.
Qualitatively, HAMR successfully recovers reasonable hand meshes from single RGB images, even under severe occlusions. Quantitatively, the superiority of HAMR was empirically confirmed on 2D and 3D hand pose estimation tasks when compared with state-of-the-art methods.
Given these developments and continued interest in this problem, it’s fair to expect future advancements in both hand mesh recovery and pose estimation.
5. Conclusion
As always, if you have any questions or comments feel free to leave your feedback below, or you can always reach me on LinkedIn.
See you in my next post! 😄
Comments 0 Responses